 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat's in a Message?
Feb 13, 2009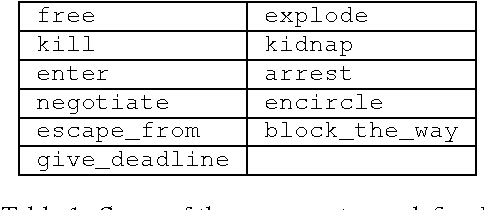
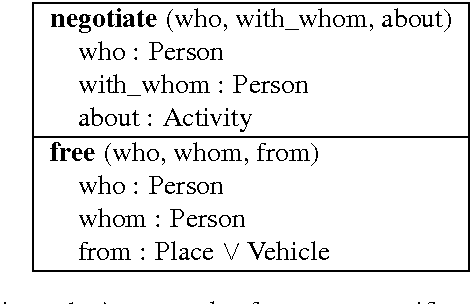

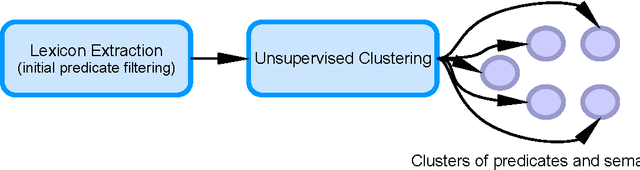
In this paper we present the first step in a larger series of experiments for the induction of predicate/argument structures. The structures that we are inducing are very similar to the conceptual structures that are used in Frame Semantics (such as FrameNet). Those structures are called messages and they were previously used in the context of a multi-document summarization system of evolving events. The series of experiments that we are proposing are essentially composed from two stages. In the first stage we are trying to extract a representative vocabulary of words. This vocabulary is later used in the second stage, during which we apply to it various clustering approaches in order to identify the clusters of predicates and arguments--or frames and semantic roles, to use the jargon of Frame Semantics. This paper presents in detail and evaluates the first stage.
Let's get the student into the driver's seat
Nov 23, 2007



Speaking a language and achieving proficiency in another one is a highly complex process which requires the acquisition of various kinds of knowledge and skills, like the learning of words, rules and patterns and their connection to communicative goals (intentions), the usual starting point. To help the learner to acquire these skills we propose an enhanced, electronic version of an age old method: pattern drills (henceforth PDs). While being highly regarded in the fifties, PDs have become unpopular since then, partially because of their lack of grounding (natural context) and rigidity. Despite these shortcomings we do believe in the virtues of this approach, at least with regard to the acquisition of basic linguistic reflexes or skills (automatisms), necessary to survive in the new language. Of course, the method needs improvement, and we will show here how this can be achieved. Unlike tapes or books, computers are open media, allowing for dynamic changes, taking users' performances and preferences into account. Building an electronic version of PDs amounts to building an open resource, accomodatable to the users' ever changing needs.
* 6 pages
Some Reflections on the Task of Content Determination in the Context of Multi-Document Summarization of Evolving Events
Oct 29, 2007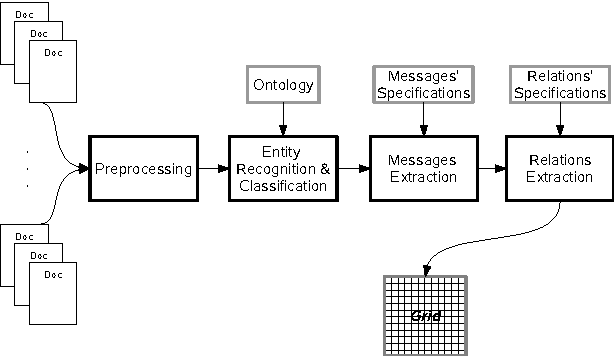
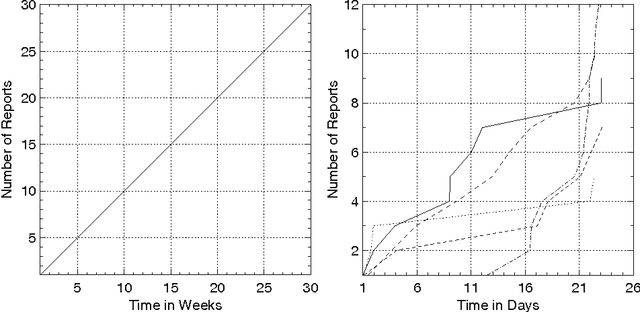
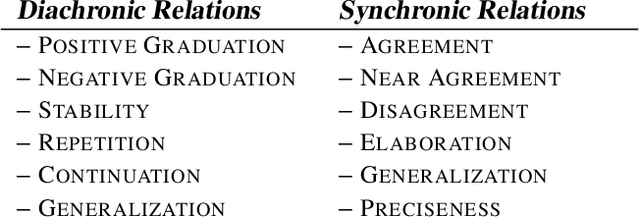
Despite its importance, the task of summarizing evolving events has received small attention by researchers in the field of multi-document summariztion. In a previous paper (Afantenos et al. 2007) we have presented a methodology for the automatic summarization of documents, emitted by multiple sources, which describe the evolution of an event. At the heart of this methodology lies the identification of similarities and differences between the various documents, in two axes: the synchronic and the diachronic. This is achieved by the introduction of the notion of Synchronic and Diachronic Relations. Those relations connect the messages that are found in the documents, resulting thus in a graph which we call grid. Although the creation of the grid completes the Document Planning phase of a typical NLG architecture, it can be the case that the number of messages contained in a grid is very large, exceeding thus the required compression rate. In this paper we provide some initial thoughts on a probabilistic model which can be applied at the Content Determination stage, and which tries to alleviate this problem.
* 5 pages, 2 figures
Using Synchronic and Diachronic Relations for Summarizing Multiple Documents Describing Evolving Events
Oct 18, 2007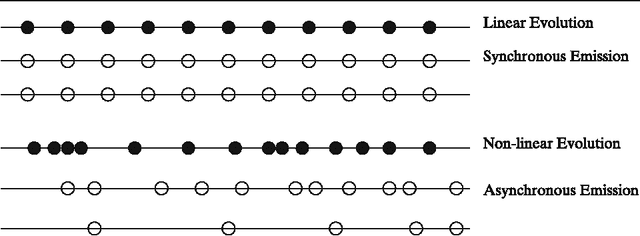

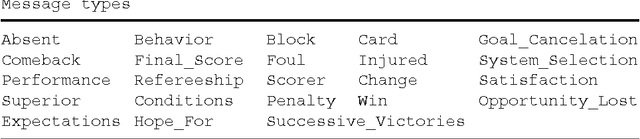
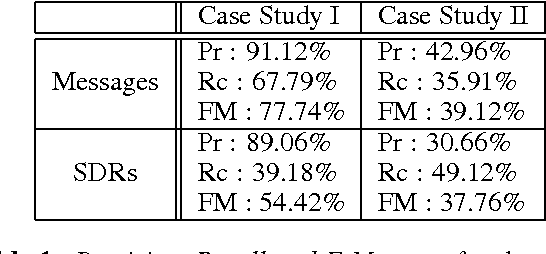
In this paper we present a fresh look at the problem of summarizing evolving events from multiple sources. After a discussion concerning the nature of evolving events we introduce a distinction between linearly and non-linearly evolving events. We present then a general methodology for the automatic creation of summaries from evolving events. At its heart lie the notions of Synchronic and Diachronic cross-document Relations (SDRs), whose aim is the identification of similarities and differences between sources, from a synchronical and diachronical perspective. SDRs do not connect documents or textual elements found therein, but structures one might call messages. Applying this methodology will yield a set of messages and relations, SDRs, connecting them, that is a graph which we call grid. We will show how such a grid can be considered as the starting point of a Natural Language Generation System. The methodology is evaluated in two case-studies, one for linearly evolving events (descriptions of football matches) and another one for non-linearly evolving events (terrorist incidents involving hostages). In both cases we evaluate the results produced by our computational systems.
Summarizing Reports on Evolving Events; Part I: Linear Evolution
Aug 22, 2005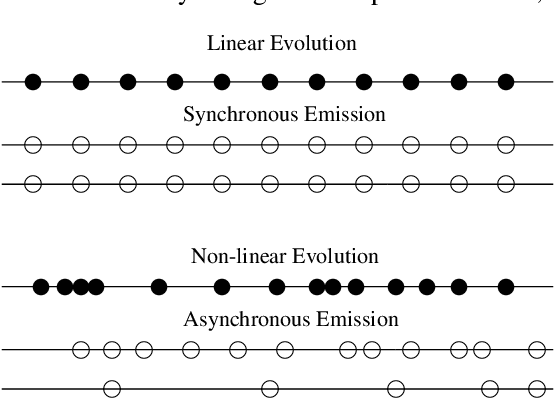

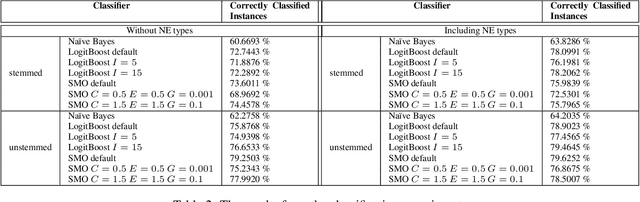
We present an approach for summarization from multiple documents which report on events that evolve through time, taking into account the different document sources. We distinguish the evolution of an event into linear and non-linear. According to our approach, each document is represented by a collection of messages which are then used in order to instantiate the cross-document relations that determine the summary content. The paper presents the summarization system that implements this approach through a case study on linear evolution.
* 7 pages. Published on the Conference Recent Advances in Natural Language Processing (RANLP, 2005)
Summarization from Medical Documents: A Survey
Apr 13, 2005
Objective: The aim of this paper is to survey the recent work in medical documents summarization. Background: During the last decade, documents summarization got increasing attention by the AI research community. More recently it also attracted the interest of the medical research community as well, due to the enormous growth of information that is available to the physicians and researchers in medicine, through the large and growing number of published journals, conference proceedings, medical sites and portals on the World Wide Web, electronic medical records, etc. Methodology: This survey gives first a general background on documents summarization, presenting the factors that summarization depends upon, discussing evaluation issues and describing briefly the various types of summarization techniques. It then examines the characteristics of the medical domain through the different types of medical documents. Finally, it presents and discusses the summarization techniques used so far in the medical domain, referring to the corresponding systems and their characteristics. Discussion and conclusions: The paper discusses thoroughly the promising paths for future research in medical documents summarization. It mainly focuses on the issue of scaling to large collections of documents in various languages and from different media, on personalization issues, on portability to new sub-domains, and on the integration of summarization technology in practical applications
* 21 pages, 4 tables
An Introduction to the Summarization of Evolving Events: Linear and Non-linear Evolution
Mar 15, 2005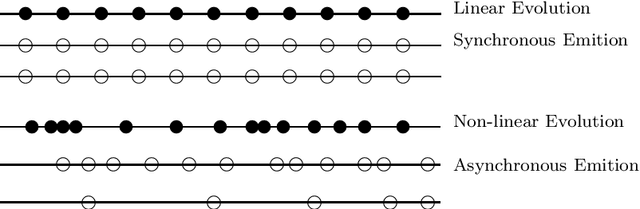
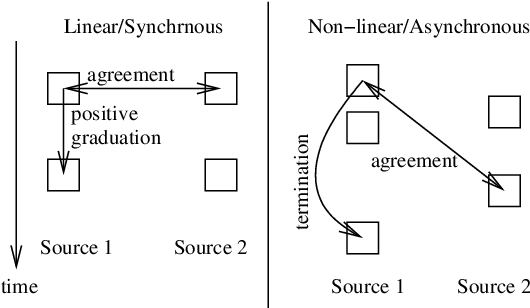
This paper examines the summarization of events that evolve through time. It discusses different types of evolution taking into account the time in which the incidents of an event are happening and the different sources reporting on the specific event. It proposes an approach for multi-document summarization which employs ``messages'' for representing the incidents of an event and cross-document relations that hold between messages according to certain conditions. The paper also outlines the current version of the summarization system we are implementing to realize this approach.
* 10 pages, 3 figures. To be pulished in Natural Language Understanding and Cognitive Science (NLUCS - 2005) conference
Exploiting Cross-Document Relations for Multi-document Evolving Summarization
Apr 23, 2004

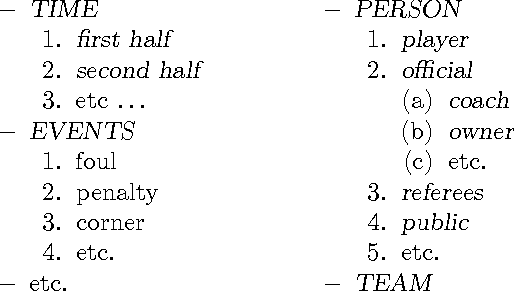
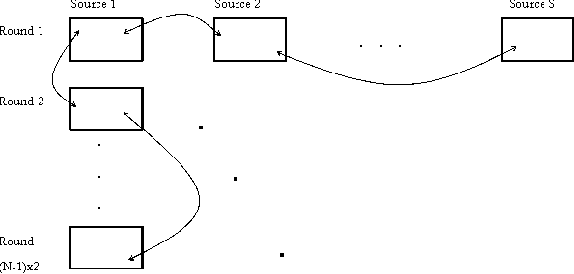
This paper presents a methodology for summarization from multiple documents which are about a specific topic. It is based on the specification and identification of the cross-document relations that occur among textual elements within those documents. Our methodology involves the specification of the topic-specific entities, the messages conveyed for the specific entities by certain textual elements and the specification of the relations that can hold among these messages. The above resources are necessary for setting up a specific topic for our query-based summarization approach which uses these resources to identify the query-specific messages within the documents and the query-specific relations that connect these messages across documents.
* 10 pages