 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSummarizing Reports on Evolving Events; Part I: Linear Evolution
Aug 22, 2005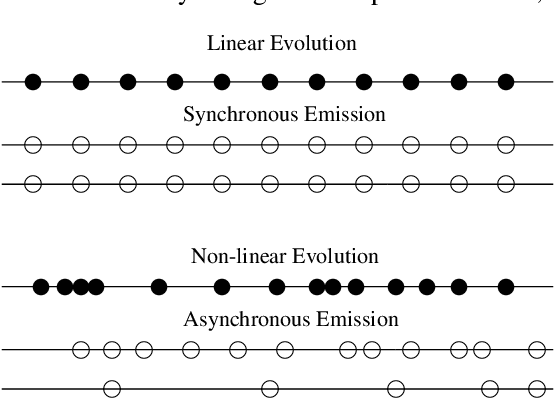

We present an approach for summarization from multiple documents which report on events that evolve through time, taking into account the different document sources. We distinguish the evolution of an event into linear and non-linear. According to our approach, each document is represented by a collection of messages which are then used in order to instantiate the cross-document relations that determine the summary content. The paper presents the summarization system that implements this approach through a case study on linear evolution.
* 7 pages. Published on the Conference Recent Advances in Natural Language Processing (RANLP, 2005)
Summarization from Medical Documents: A Survey
Apr 13, 2005
Objective: The aim of this paper is to survey the recent work in medical documents summarization. Background: During the last decade, documents summarization got increasing attention by the AI research community. More recently it also attracted the interest of the medical research community as well, due to the enormous growth of information that is available to the physicians and researchers in medicine, through the large and growing number of published journals, conference proceedings, medical sites and portals on the World Wide Web, electronic medical records, etc. Methodology: This survey gives first a general background on documents summarization, presenting the factors that summarization depends upon, discussing evaluation issues and describing briefly the various types of summarization techniques. It then examines the characteristics of the medical domain through the different types of medical documents. Finally, it presents and discusses the summarization techniques used so far in the medical domain, referring to the corresponding systems and their characteristics. Discussion and conclusions: The paper discusses thoroughly the promising paths for future research in medical documents summarization. It mainly focuses on the issue of scaling to large collections of documents in various languages and from different media, on personalization issues, on portability to new sub-domains, and on the integration of summarization technology in practical applications
* 21 pages, 4 tables
Learning to Filter Spam E-Mail: A Comparison of a Naive Bayesian and a Memory-Based Approach
Sep 18, 2000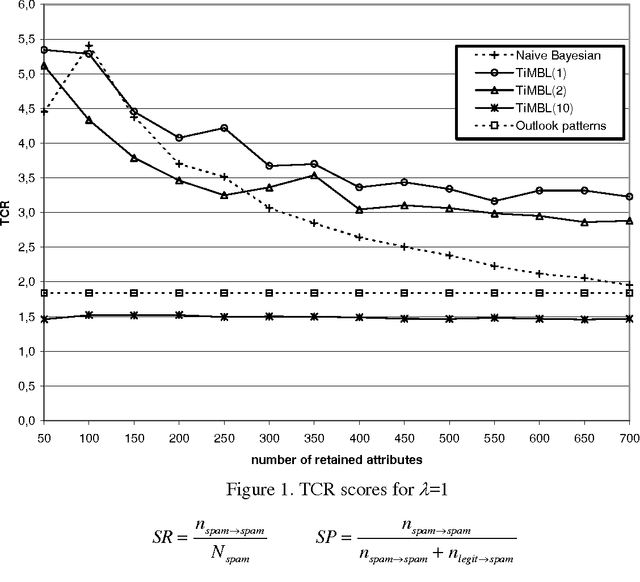
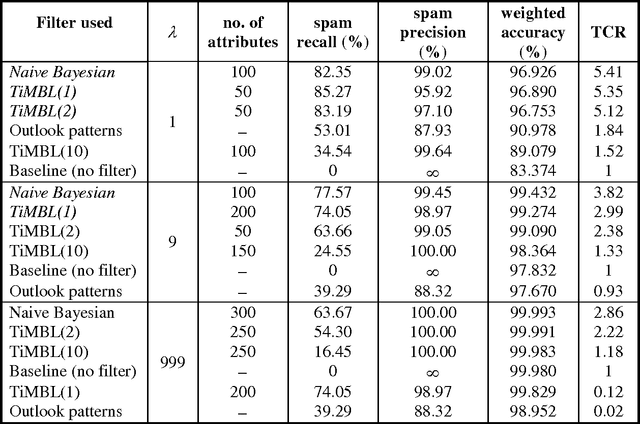
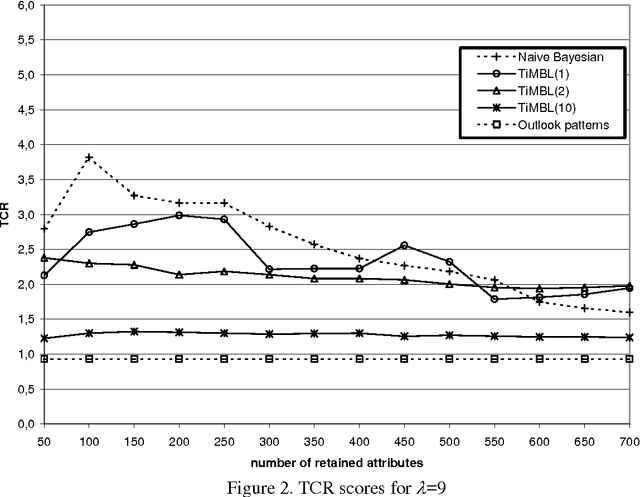
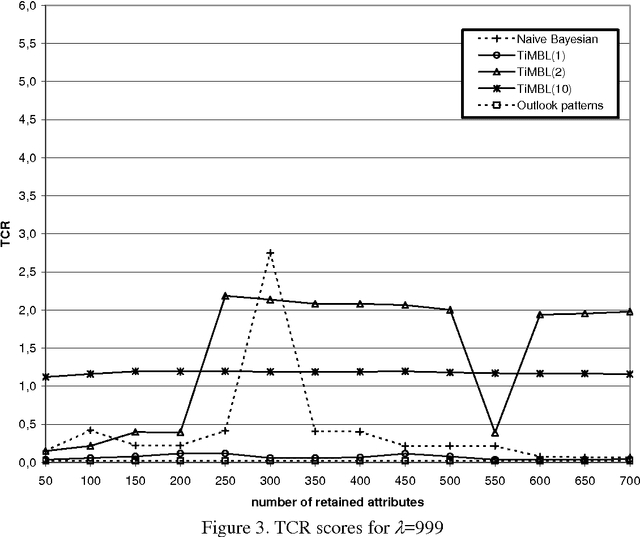
We investigate the performance of two machine learning algorithms in the context of anti-spam filtering. The increasing volume of unsolicited bulk e-mail (spam) has generated a need for reliable anti-spam filters. Filters of this type have so far been based mostly on keyword patterns that are constructed by hand and perform poorly. The Naive Bayesian classifier has recently been suggested as an effective method to construct automatically anti-spam filters with superior performance. We investigate thoroughly the performance of the Naive Bayesian filter on a publicly available corpus, contributing towards standard benchmarks. At the same time, we compare the performance of the Naive Bayesian filter to an alternative memory-based learning approach, after introducing suitable cost-sensitive evaluation measures. Both methods achieve very accurate spam filtering, outperforming clearly the keyword-based filter of a widely used e-mail reader.