 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEllogon: A New Text Engineering Platform
May 13, 2002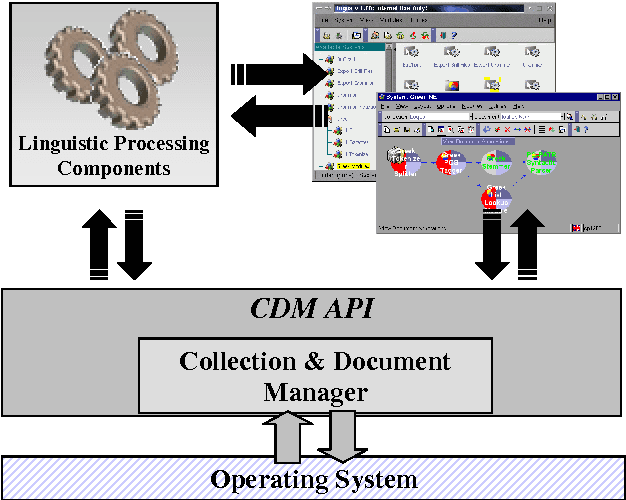

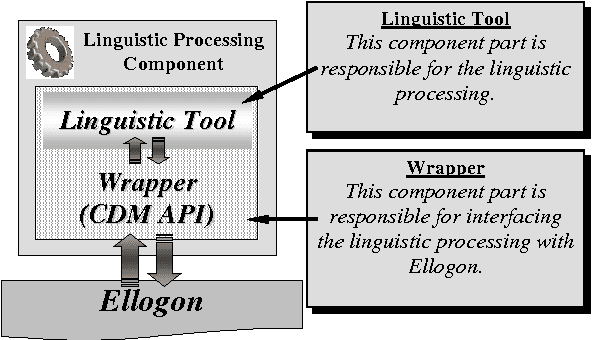
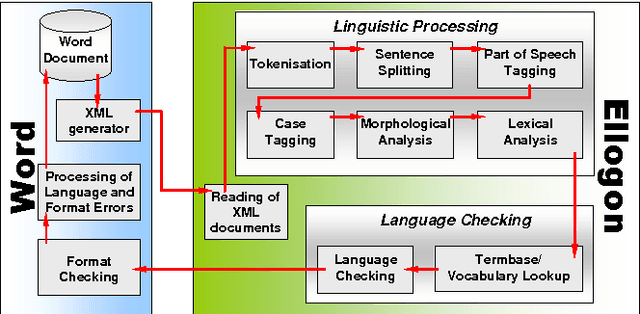
This paper presents Ellogon, a multi-lingual, cross-platform, general-purpose text engineering environment. Ellogon was designed in order to aid both researchers in natural language processing, as well as companies that produce language engineering systems for the end-user. Ellogon provides a powerful TIPSTER-based infrastructure for managing, storing and exchanging textual data, embedding and managing text processing components as well as visualising textual data and their associated linguistic information. Among its key features are full Unicode support, an extensive multi-lingual graphical user interface, its modular architecture and the reduced hardware requirements.
Learning to Filter Spam E-Mail: A Comparison of a Naive Bayesian and a Memory-Based Approach
Sep 18, 2000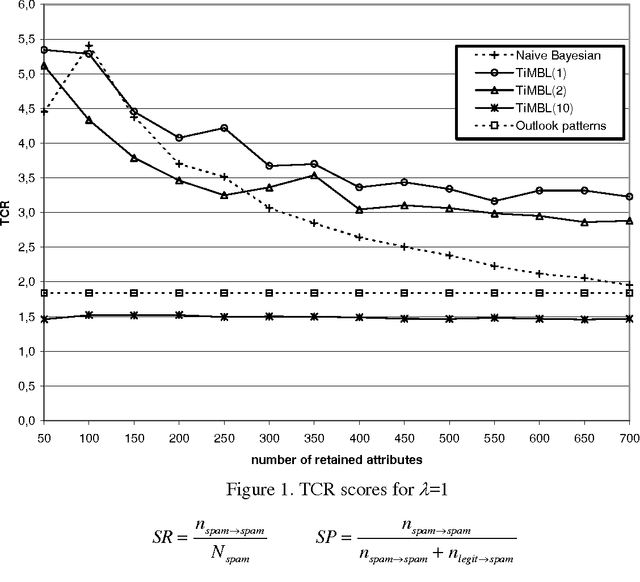
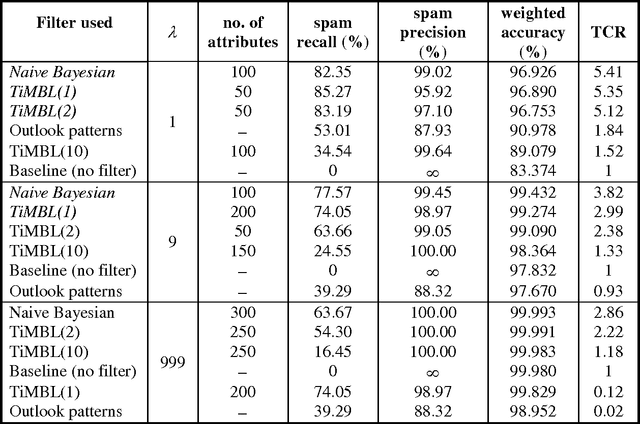
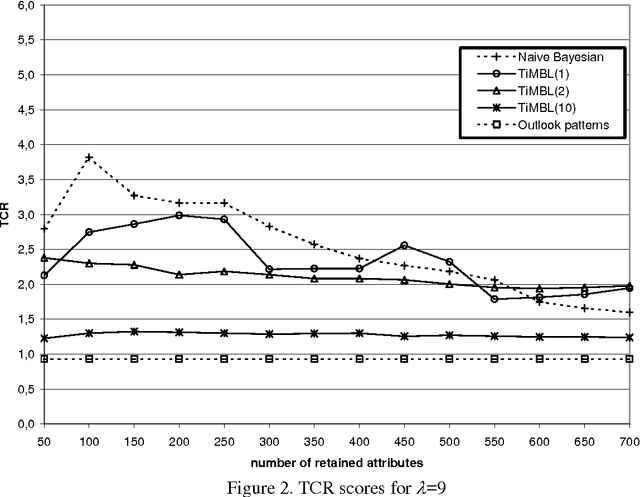
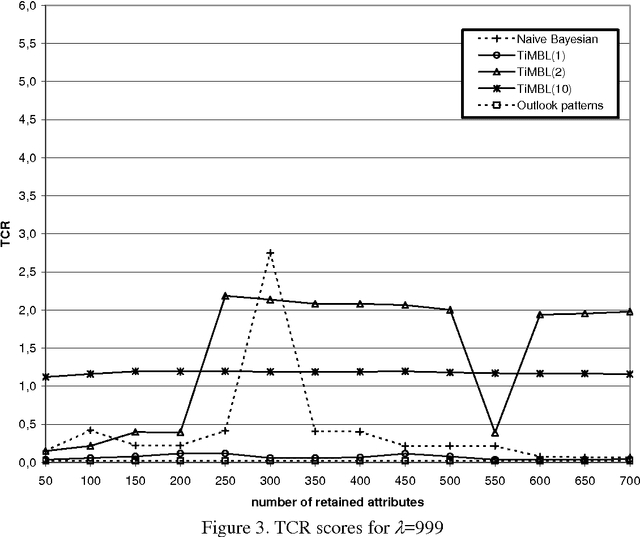
We investigate the performance of two machine learning algorithms in the context of anti-spam filtering. The increasing volume of unsolicited bulk e-mail (spam) has generated a need for reliable anti-spam filters. Filters of this type have so far been based mostly on keyword patterns that are constructed by hand and perform poorly. The Naive Bayesian classifier has recently been suggested as an effective method to construct automatically anti-spam filters with superior performance. We investigate thoroughly the performance of the Naive Bayesian filter on a publicly available corpus, contributing towards standard benchmarks. At the same time, we compare the performance of the Naive Bayesian filter to an alternative memory-based learning approach, after introducing suitable cost-sensitive evaluation measures. Both methods achieve very accurate spam filtering, outperforming clearly the keyword-based filter of a widely used e-mail reader.
An Experimental Comparison of Naive Bayesian and Keyword-Based Anti-Spam Filtering with Personal E-mail Messages
Aug 22, 2000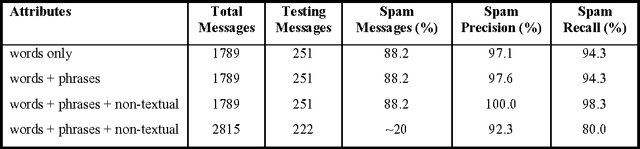

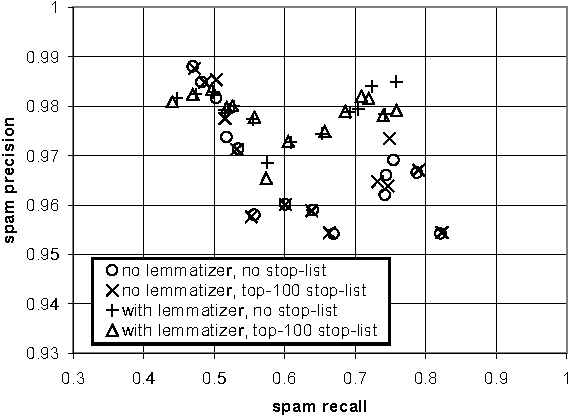

The growing problem of unsolicited bulk e-mail, also known as "spam", has generated a need for reliable anti-spam e-mail filters. Filters of this type have so far been based mostly on manually constructed keyword patterns. An alternative approach has recently been proposed, whereby a Naive Bayesian classifier is trained automatically to detect spam messages. We test this approach on a large collection of personal e-mail messages, which we make publicly available in "encrypted" form contributing towards standard benchmarks. We introduce appropriate cost-sensitive measures, investigating at the same time the effect of attribute-set size, training-corpus size, lemmatization, and stop lists, issues that have not been explored in previous experiments. Finally, the Naive Bayesian filter is compared, in terms of performance, to a filter that uses keyword patterns, and which is part of a widely used e-mail reader.
An evaluation of Naive Bayesian anti-spam filtering
Jun 07, 2000
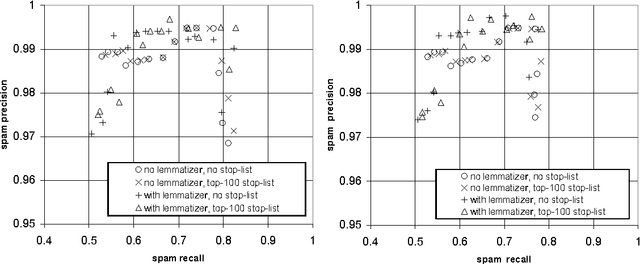
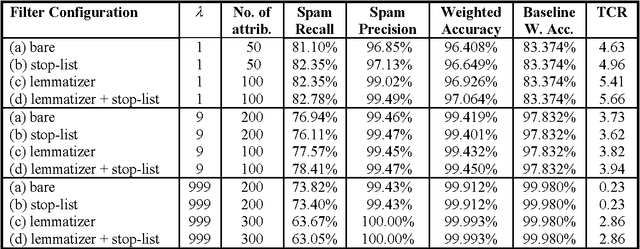
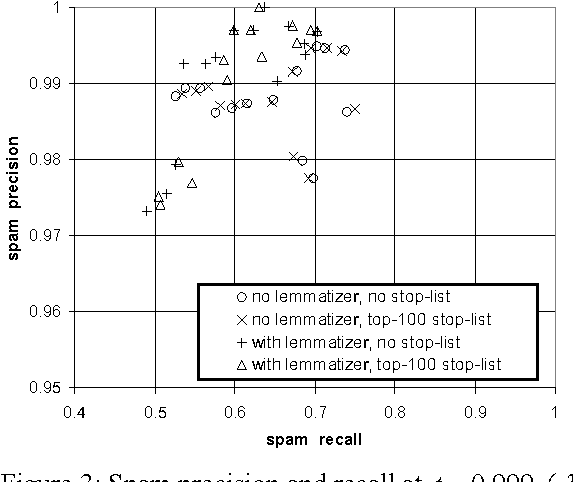
It has recently been argued that a Naive Bayesian classifier can be used to filter unsolicited bulk e-mail ("spam"). We conduct a thorough evaluation of this proposal on a corpus that we make publicly available, contributing towards standard benchmarks. At the same time we investigate the effect of attribute-set size, training-corpus size, lemmatization, and stop-lists on the filter's performance, issues that had not been previously explored. After introducing appropriate cost-sensitive evaluation measures, we reach the conclusion that additional safety nets are needed for the Naive Bayesian anti-spam filter to be viable in practice.
* 9 pages