 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Experimental Comparison of Naive Bayesian and Keyword-Based Anti-Spam Filtering with Personal E-mail Messages
Aug 22, 2000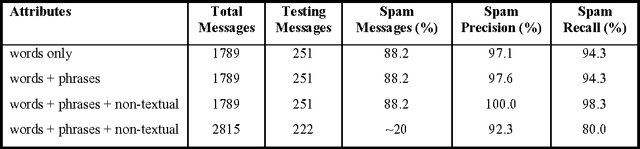


The growing problem of unsolicited bulk e-mail, also known as "spam", has generated a need for reliable anti-spam e-mail filters. Filters of this type have so far been based mostly on manually constructed keyword patterns. An alternative approach has recently been proposed, whereby a Naive Bayesian classifier is trained automatically to detect spam messages. We test this approach on a large collection of personal e-mail messages, which we make publicly available in "encrypted" form contributing towards standard benchmarks. We introduce appropriate cost-sensitive measures, investigating at the same time the effect of attribute-set size, training-corpus size, lemmatization, and stop lists, issues that have not been explored in previous experiments. Finally, the Naive Bayesian filter is compared, in terms of performance, to a filter that uses keyword patterns, and which is part of a widely used e-mail reader.
An evaluation of Naive Bayesian anti-spam filtering
Jun 07, 2000
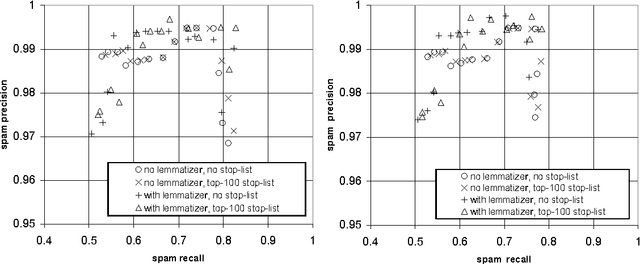
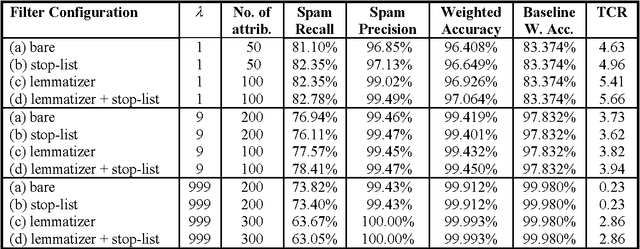
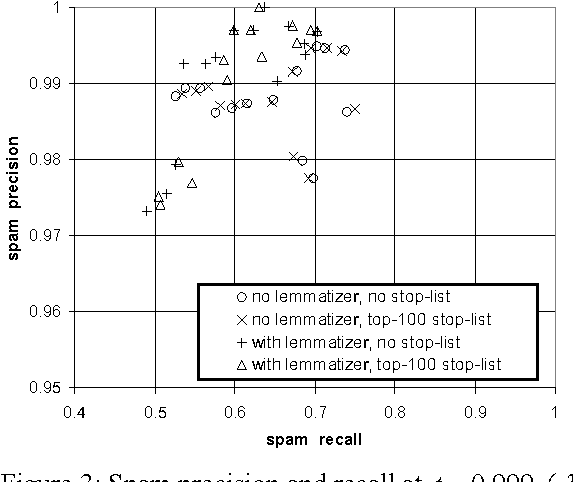
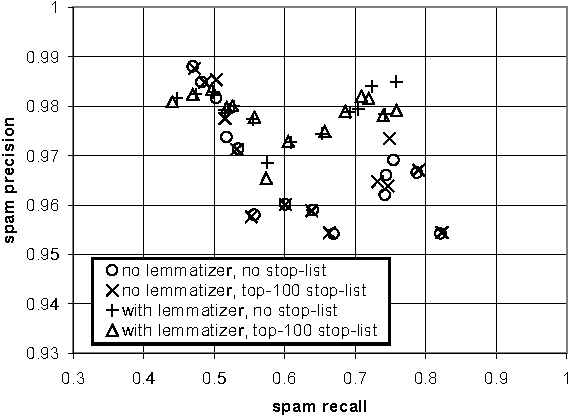
It has recently been argued that a Naive Bayesian classifier can be used to filter unsolicited bulk e-mail ("spam"). We conduct a thorough evaluation of this proposal on a corpus that we make publicly available, contributing towards standard benchmarks. At the same time we investigate the effect of attribute-set size, training-corpus size, lemmatization, and stop-lists on the filter's performance, issues that had not been previously explored. After introducing appropriate cost-sensitive evaluation measures, we reach the conclusion that additional safety nets are needed for the Naive Bayesian anti-spam filter to be viable in practice.
* 9 pages