 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeurIPS 2025 E2LM Competition : Early Training Evaluation of Language Models
Jun 09, 2025Existing benchmarks have proven effective for assessing the performance of fully trained large language models. However, we find striking differences in the early training stages of small models, where benchmarks often fail to provide meaningful or discriminative signals. To explore how these differences arise, this competition tackles the challenge of designing scientific knowledge evaluation tasks specifically tailored for measuring early training progress of language models. Participants are invited to develop novel evaluation methodologies or adapt existing benchmarks to better capture performance differences among language models. To support this effort, we provide three pre-trained small models (0.5B, 1B, and 3B parameters), along with intermediate checkpoints sampled during training up to 200B tokens. All experiments and development work can be run on widely available free cloud-based GPU platforms, making participation accessible to researchers with limited computational resources. Submissions will be evaluated based on three criteria: the quality of the performance signal they produce, the consistency of model rankings at 1 trillion tokens of training, and their relevance to the scientific knowledge domain. By promoting the design of tailored evaluation strategies for early training, this competition aims to attract a broad range of participants from various disciplines, including those who may not be machine learning experts or have access to dedicated GPU resources. Ultimately, this initiative seeks to make foundational LLM research more systematic and benchmark-informed from the earliest phases of model development.
Falcon2-11B Technical Report
Jul 20, 2024



We introduce Falcon2-11B, a foundation model trained on over five trillion tokens, and its multimodal counterpart, Falcon2-11B-vlm, which is a vision-to-text model. We report our findings during the training of the Falcon2-11B which follows a multi-stage approach where the early stages are distinguished by their context length and a final stage where we use a curated, high-quality dataset. Additionally, we report the effect of doubling the batch size mid-training and how training loss spikes are affected by the learning rate. The downstream performance of the foundation model is evaluated on established benchmarks, including multilingual and code datasets. The foundation model shows strong generalization across all the tasks which makes it suitable for downstream finetuning use cases. For the vision language model, we report the performance on several benchmarks and show that our model achieves a higher average score compared to open-source models of similar size. The model weights and code of both Falcon2-11B and Falcon2-11B-vlm are made available under a permissive license.
Deep Retrieval-Based Dialogue Systems: A Short Review
Jul 30, 2019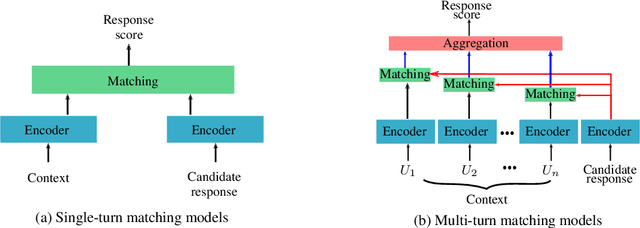
Building dialogue systems that naturally converse with humans is being an attractive and an active research domain. Multiple systems are being designed everyday and several datasets are being available. For this reason, it is being hard to keep an up-to-date state-of-the-art. In this work, we present the latest and most relevant retrieval-based dialogue systems and the available datasets used to build and evaluate them. We discuss their limitations and provide insights and guidelines for future work.
Thread Reconstruction in Conversational Data using Neural Coherence Models
Jul 25, 2017



Discussion forums are an important source of information. They are often used to answer specific questions a user might have and to discover more about a topic of interest. Discussions in these forums may evolve in intricate ways, making it difficult for users to follow the flow of ideas. We propose a novel approach for automatically identifying the underlying thread structure of a forum discussion. Our approach is based on a neural model that computes coherence scores of possible reconstructions and then selects the highest scoring, i.e., the most coherent one. Preliminary experiments demonstrate promising results outperforming a number of strong baseline methods.