 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusionista2.0: Efficiency Retrieval System for Large-Scale Datasets
Nov 15, 2025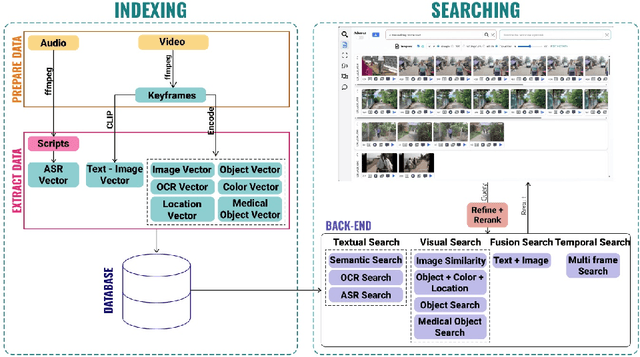

The Video Browser Showdown (VBS) challenges systems to deliver accurate results under strict time constraints. To meet this demand, we present Fusionista2.0, a streamlined video retrieval system optimized for speed and usability. All core modules were re-engineered for efficiency: preprocessing now relies on ffmpeg for fast keyframe extraction, optical character recognition uses Vintern-1B-v3.5 for robust multilingual text recognition, and automatic speech recognition employs faster-whisper for real-time transcription. For question answering, lightweight vision-language models provide quick responses without the heavy cost of large models. Beyond these technical upgrades, Fusionista2.0 introduces a redesigned user interface with improved responsiveness, accessibility, and workflow efficiency, enabling even non-expert users to retrieve relevant content rapidly. Evaluations demonstrate that retrieval time was reduced by up to 75% while accuracy and user satisfaction both increased, confirming Fusionista2.0 as a competitive and user-friendly system for large-scale video search.
From FiLM to Video: Multi-turn Question Answering with Multi-modal Context
Dec 17, 2018

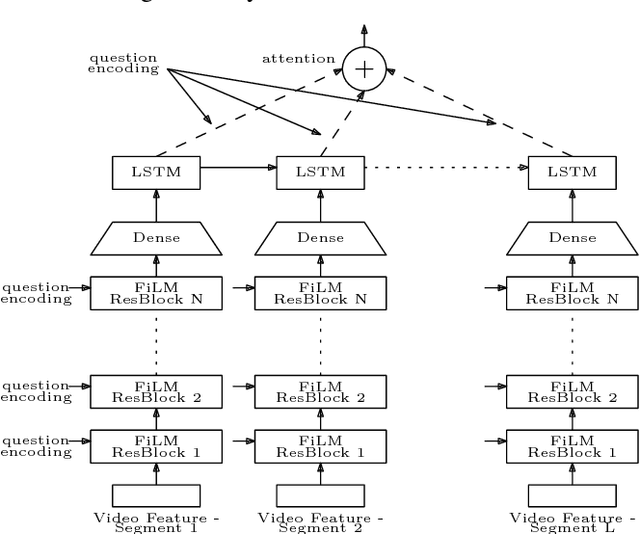
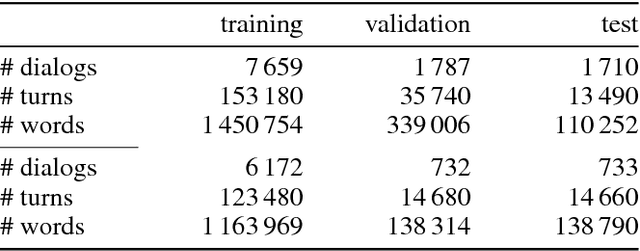
Understanding audio-visual content and the ability to have an informative conversation about it have both been challenging areas for intelligent systems. The Audio Visual Scene-aware Dialog (AVSD) challenge, organized as a track of the Dialog System Technology Challenge 7 (DSTC7), proposes a combined task, where a system has to answer questions pertaining to a video given a dialogue with previous question-answer pairs and the video itself. We propose for this task a hierarchical encoder-decoder model which computes a multi-modal embedding of the dialogue context. It first embeds the dialogue history using two LSTMs. We extract video and audio frames at regular intervals and compute semantic features using pre-trained I3D and VGGish models, respectively. Before summarizing both modalities into fixed-length vectors using LSTMs, we use FiLM blocks to condition them on the embeddings of the current question, which allows us to reduce the dimensionality considerably. Finally, we use an LSTM decoder that we train with scheduled sampling and evaluate using beam search. Compared to the modality-fusing baseline model released by the AVSD challenge organizers, our model achieves a relative improvements of more than 16%, scoring 0.36 BLEU-4 and more than 33%, scoring 0.997 CIDEr.
Coherence Modeling of Asynchronous Conversations: A Neural Entity Grid Approach
May 06, 2018



We propose a novel coherence model for written asynchronous conversations (e.g., forums, emails), and show its applications in coherence assessment and thread reconstruction tasks. We conduct our research in two steps. First, we propose improvements to the recently proposed neural entity grid model by lexicalizing its entity transitions. Then, we extend the model to asynchronous conversations by incorporating the underlying conversational structure in the entity grid representation and feature computation. Our model achieves state of the art results on standard coherence assessment tasks in monologue and conversations outperforming existing models. We also demonstrate its effectiveness in reconstructing thread structures.
Thread Reconstruction in Conversational Data using Neural Coherence Models
Jul 25, 2017



Discussion forums are an important source of information. They are often used to answer specific questions a user might have and to discover more about a topic of interest. Discussions in these forums may evolve in intricate ways, making it difficult for users to follow the flow of ideas. We propose a novel approach for automatically identifying the underlying thread structure of a forum discussion. Our approach is based on a neural model that computes coherence scores of possible reconstructions and then selects the highest scoring, i.e., the most coherent one. Preliminary experiments demonstrate promising results outperforming a number of strong baseline methods.
Automatic Image Filtering on Social Networks Using Deep Learning and Perceptual Hashing During Crises
Apr 09, 2017

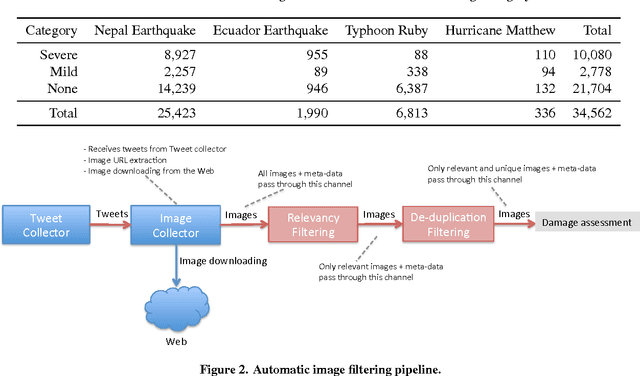

The extensive use of social media platforms, especially during disasters, creates unique opportunities for humanitarian organizations to gain situational awareness and launch relief operations accordingly. In addition to the textual content, people post overwhelming amounts of imagery data on social networks within minutes of a disaster hit. Studies point to the importance of this online imagery content for emergency response. Despite recent advances in the computer vision field, automatic processing of the crisis-related social media imagery data remains a challenging task. It is because a majority of which consists of redundant and irrelevant content. In this paper, we present an image processing pipeline that comprises de-duplication and relevancy filtering mechanisms to collect and filter social media image content in real-time during a crisis event. Results obtained from extensive experiments on real-world crisis datasets demonstrate the significance of the proposed pipeline for optimal utilization of both human and machine computing resources.
Applications of Online Deep Learning for Crisis Response Using Social Media Information
Oct 05, 2016

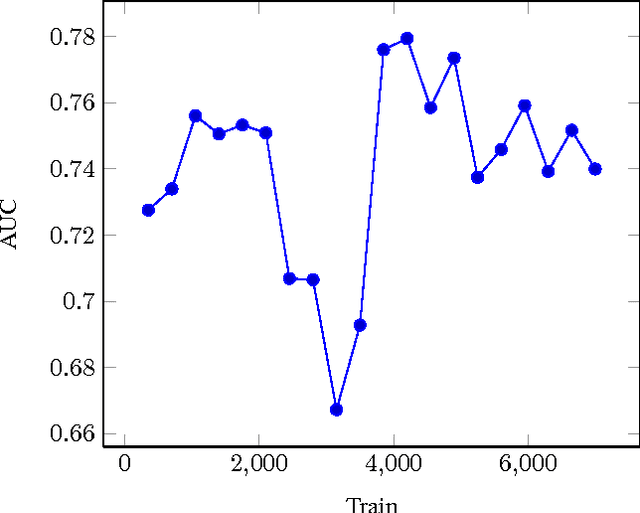
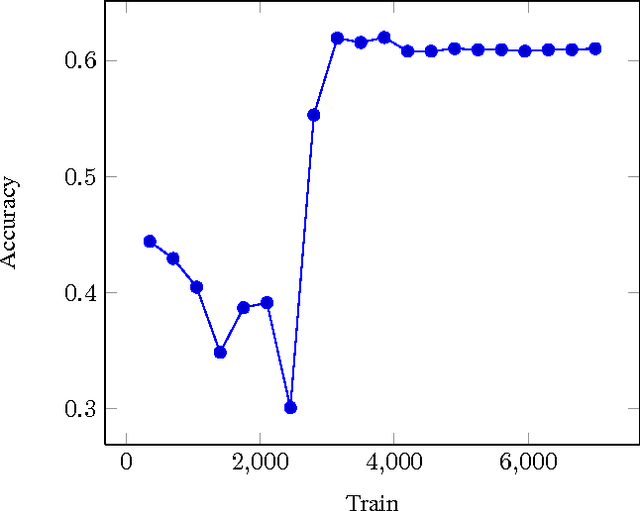
During natural or man-made disasters, humanitarian response organizations look for useful information to support their decision-making processes. Social media platforms such as Twitter have been considered as a vital source of useful information for disaster response and management. Despite advances in natural language processing techniques, processing short and informal Twitter messages is a challenging task. In this paper, we propose to use Deep Neural Network (DNN) to address two types of information needs of response organizations: 1) identifying informative tweets and 2) classifying them into topical classes. DNNs use distributed representation of words and learn the representation as well as higher level features automatically for the classification task. We propose a new online algorithm based on stochastic gradient descent to train DNNs in an online fashion during disaster situations. We test our models using a crisis-related real-world Twitter dataset.
Rapid Classification of Crisis-Related Data on Social Networks using Convolutional Neural Networks
Aug 12, 2016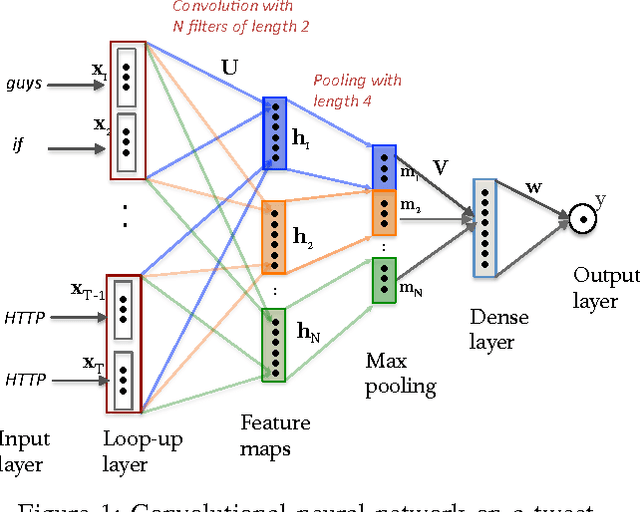
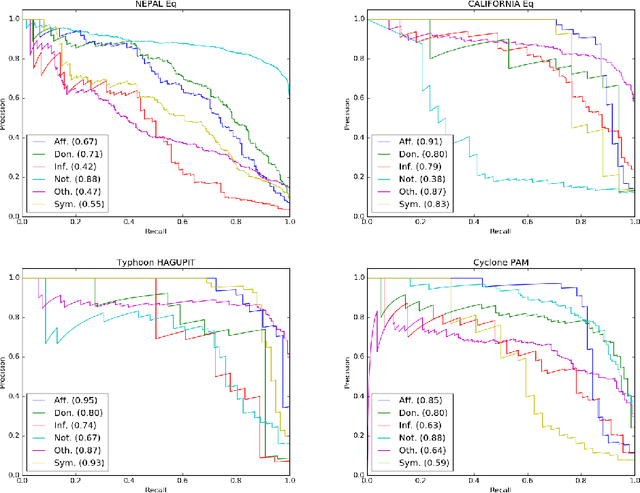
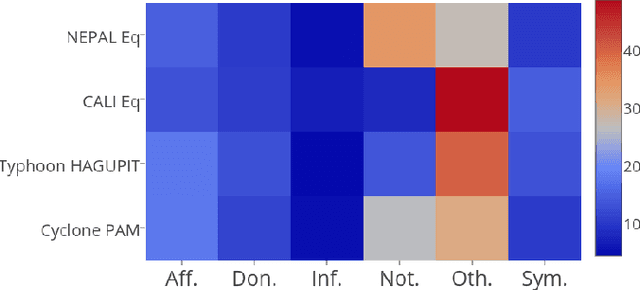

The role of social media, in particular microblogging platforms such as Twitter, as a conduit for actionable and tactical information during disasters is increasingly acknowledged. However, time-critical analysis of big crisis data on social media streams brings challenges to machine learning techniques, especially the ones that use supervised learning. The Scarcity of labeled data, particularly in the early hours of a crisis, delays the machine learning process. The current state-of-the-art classification methods require a significant amount of labeled data specific to a particular event for training plus a lot of feature engineering to achieve best results. In this work, we introduce neural network based classification methods for binary and multi-class tweet classification task. We show that neural network based models do not require any feature engineering and perform better than state-of-the-art methods. In the early hours of a disaster when no labeled data is available, our proposed method makes the best use of the out-of-event data and achieves good results.
Unveiling the Dreams of Word Embeddings: Towards Language-Driven Image Generation
Nov 23, 2015



We introduce language-driven image generation, the task of generating an image visualizing the semantic contents of a word embedding, e.g., given the word embedding of grasshopper, we generate a natural image of a grasshopper. We implement a simple method based on two mapping functions. The first takes as input a word embedding (as produced, e.g., by the word2vec toolkit) and maps it onto a high-level visual space (e.g., the space defined by one of the top layers of a Convolutional Neural Network). The second function maps this abstract visual representation to pixel space, in order to generate the target image. Several user studies suggest that the current system produces images that capture general visual properties of the concepts encoded in the word embedding, such as color or typical environment, and are sufficient to discriminate between general categories of objects.