 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecomposed Mutual Information Estimation for Contrastive Representation Learning
Jun 25, 2021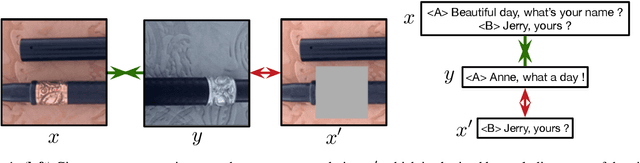

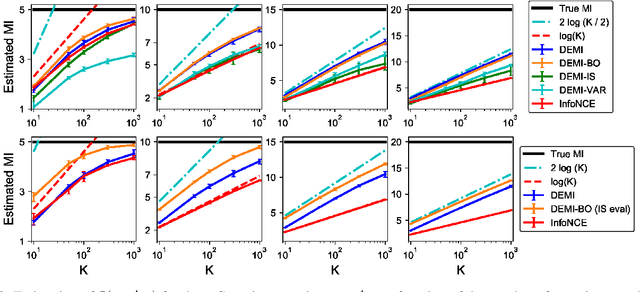
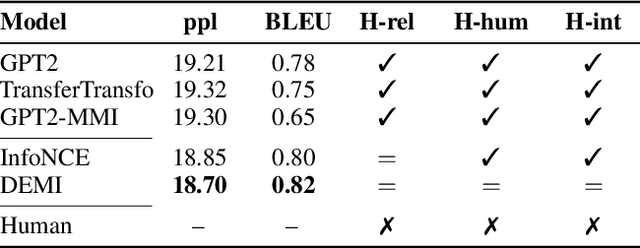
Recent contrastive representation learning methods rely on estimating mutual information (MI) between multiple views of an underlying context. E.g., we can derive multiple views of a given image by applying data augmentation, or we can split a sequence into views comprising the past and future of some step in the sequence. Contrastive lower bounds on MI are easy to optimize, but have a strong underestimation bias when estimating large amounts of MI. We propose decomposing the full MI estimation problem into a sum of smaller estimation problems by splitting one of the views into progressively more informed subviews and by applying the chain rule on MI between the decomposed views. This expression contains a sum of unconditional and conditional MI terms, each measuring modest chunks of the total MI, which facilitates approximation via contrastive bounds. To maximize the sum, we formulate a contrastive lower bound on the conditional MI which can be approximated efficiently. We refer to our general approach as Decomposed Estimation of Mutual Information (DEMI). We show that DEMI can capture a larger amount of MI than standard non-decomposed contrastive bounds in a synthetic setting, and learns better representations in a vision domain and for dialogue generation.
Towards a Scalable and Distributed Infrastructure for Deep Learning Applications
Oct 06, 2020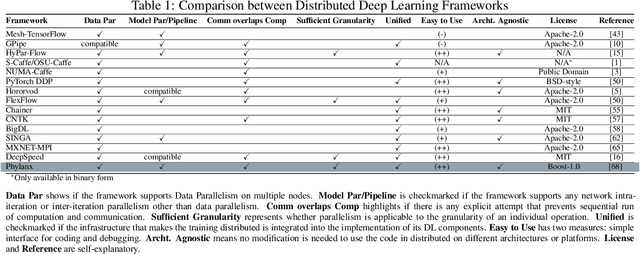
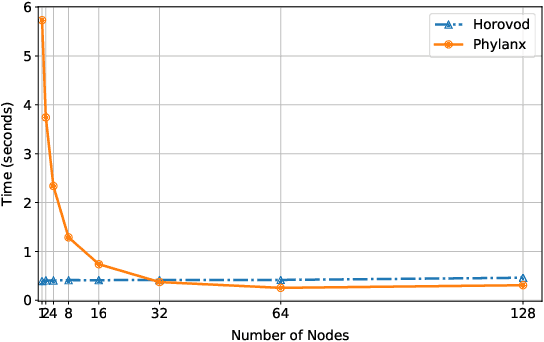
Although recent scaling up approaches to train deep neural networks have proven to be effective, the computational intensity of large and complex models, as well as the availability of large-scale datasets require deep learning frameworks to utilize scaling out techniques. Parallelization approaches and distribution requirements are not considered in the primary designs of most available distributed deep learning frameworks and most of them still are not able to perform effective and efficient fine-grained inter-node communication. We present Phylanx that has the potential to alleviate these shortcomings. Phylanx presents a productivity-oriented frontend where user Python code is translated to a futurized execution tree that can be executed efficiently on multiple nodes using the C++ standard library for parallelism and concurrency (HPX), leveraging fine-grained threading and an active messaging task-based runtime system.
Hybrid Generative-Retrieval Transformers for Dialogue Domain Adaptation
Mar 06, 2020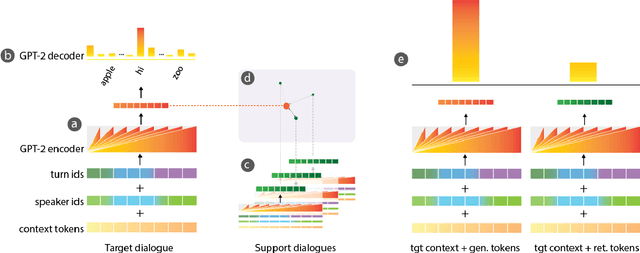

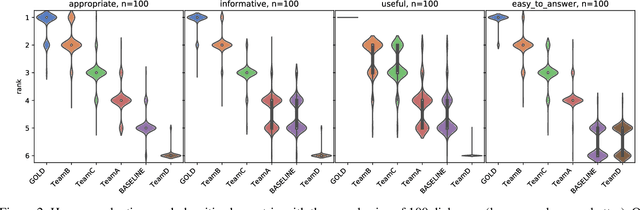
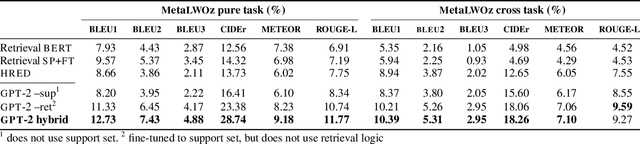
Domain adaptation has recently become a key problem in dialogue systems research. Deep learning, while being the preferred technique for modeling such systems, works best given massive training data. However, in the real-world scenario, such resources aren't available for every new domain, so the ability to train with a few dialogue examples can be considered essential. Pre-training on large data sources and adapting to the target data has become the standard method for few-shot problems within the deep learning framework. In this paper, we present the winning entry at the fast domain adaptation task of DSTC8, a hybrid generative-retrieval model based on GPT-2 fine-tuned to the multi-domain MetaLWOz dataset. Robust and diverse in response generation, our model uses retrieval logic as a fallback, being SoTA on MetaLWOz in human evaluation (>4% improvement over the 2nd place system) and attaining competitive generalization performance in adaptation to the unseen MultiWOZ dataset.
The Eighth Dialog System Technology Challenge
Nov 14, 2019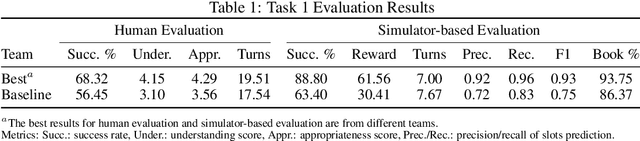
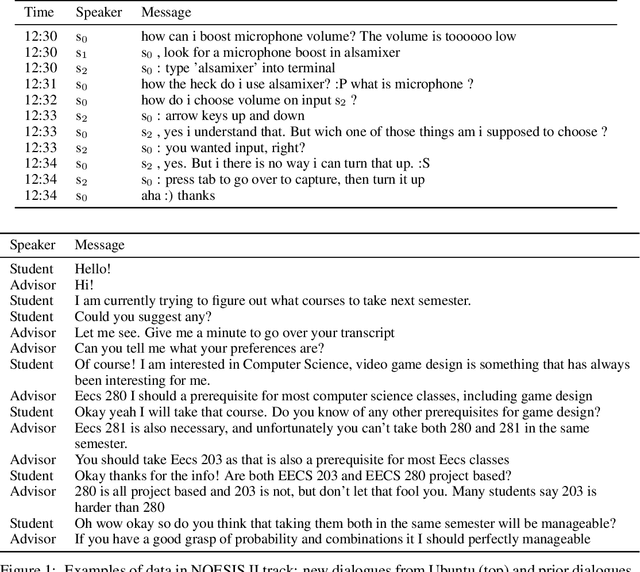
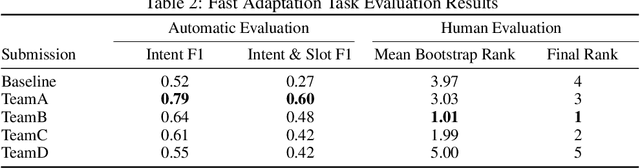
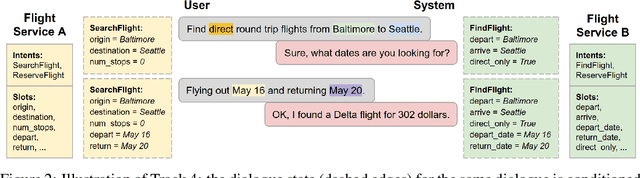
This paper introduces the Eighth Dialog System Technology Challenge. In line with recent challenges, the eighth edition focuses on applying end-to-end dialog technologies in a pragmatic way for multi-domain task-completion, noetic response selection, audio visual scene-aware dialog, and schema-guided dialog state tracking tasks. This paper describes the task definition, provided datasets, and evaluation set-up for each track. We also summarize the results of the submitted systems to highlight the overall trends of the state-of-the-art technologies for the tasks.
Towards Deep Conversational Recommendations
Dec 18, 2018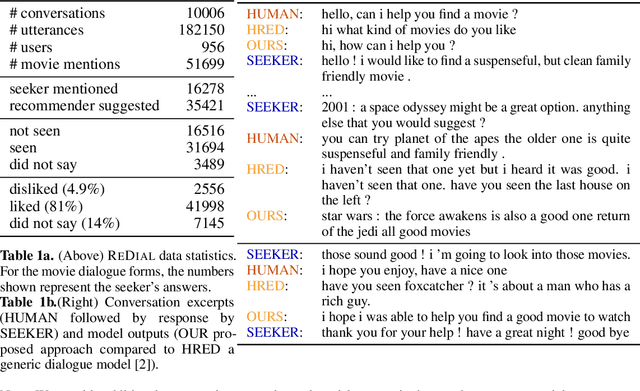
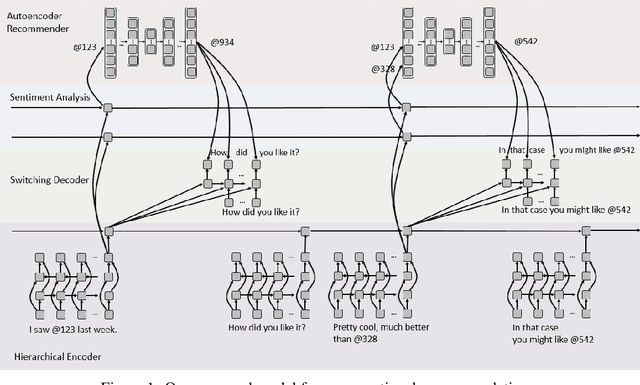


There has been growing interest in using neural networks and deep learning techniques to create dialogue systems. Conversational recommendation is an interesting setting for the scientific exploration of dialogue with natural language as the associated discourse involves goal-driven dialogue that often transforms naturally into more free-form chat. This paper provides two contributions. First, until now there has been no publicly available large-scale dataset consisting of real-world dialogues centered around recommendations. To address this issue and to facilitate our exploration here, we have collected ReDial, a dataset consisting of over 10,000 conversations centered around the theme of providing movie recommendations. We make this data available to the community for further research. Second, we use this dataset to explore multiple facets of conversational recommendations. In particular we explore new neural architectures, mechanisms, and methods suitable for composing conversational recommendation systems. Our dataset allows us to systematically probe model sub-components addressing different parts of the overall problem domain ranging from: sentiment analysis and cold-start recommendation generation to detailed aspects of how natural language is used in this setting in the real world. We combine such sub-components into a full-blown dialogue system and examine its behavior.
From FiLM to Video: Multi-turn Question Answering with Multi-modal Context
Dec 17, 2018

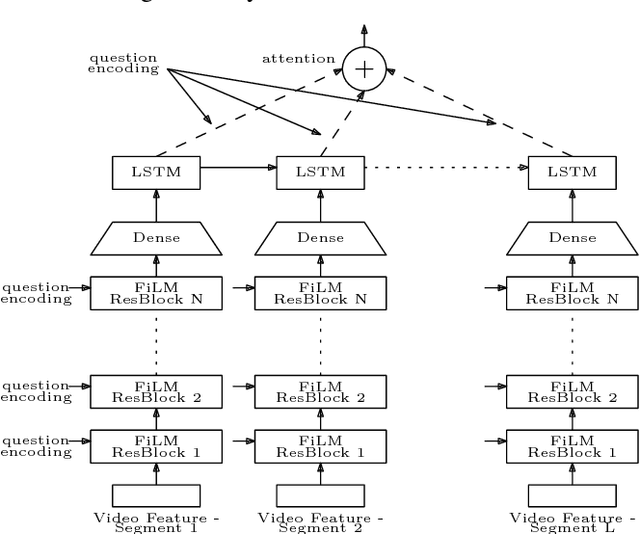
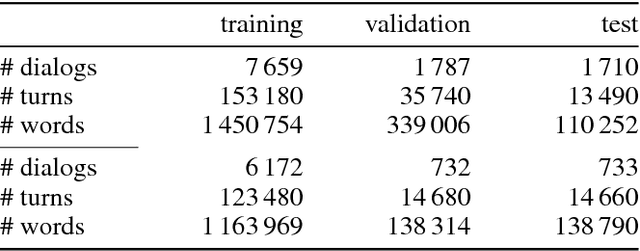
Understanding audio-visual content and the ability to have an informative conversation about it have both been challenging areas for intelligent systems. The Audio Visual Scene-aware Dialog (AVSD) challenge, organized as a track of the Dialog System Technology Challenge 7 (DSTC7), proposes a combined task, where a system has to answer questions pertaining to a video given a dialogue with previous question-answer pairs and the video itself. We propose for this task a hierarchical encoder-decoder model which computes a multi-modal embedding of the dialogue context. It first embeds the dialogue history using two LSTMs. We extract video and audio frames at regular intervals and compute semantic features using pre-trained I3D and VGGish models, respectively. Before summarizing both modalities into fixed-length vectors using LSTMs, we use FiLM blocks to condition them on the embeddings of the current question, which allows us to reduce the dimensionality considerably. Finally, we use an LSTM decoder that we train with scheduled sampling and evaluate using beam search. Compared to the modality-fusing baseline model released by the AVSD challenge organizers, our model achieves a relative improvements of more than 16%, scoring 0.36 BLEU-4 and more than 33%, scoring 0.997 CIDEr.
Keep Drawing It: Iterative language-based image generation and editing
Nov 24, 2018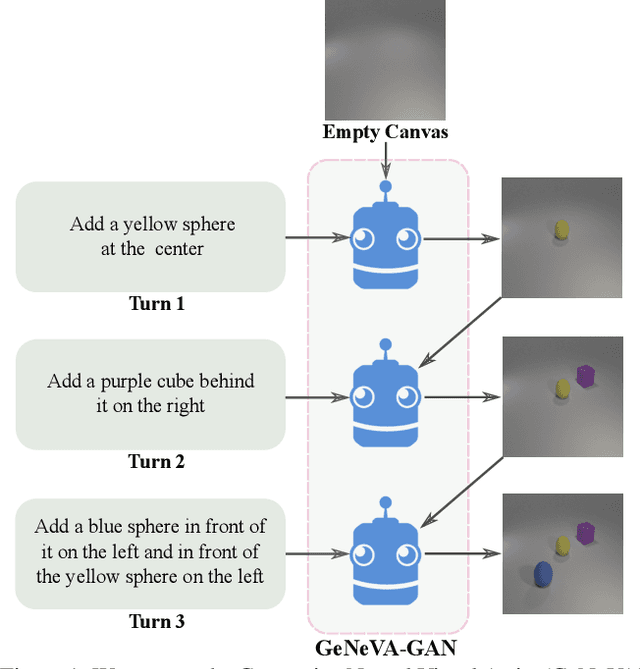


Conditional text-to-image generation approaches commonly focus on generating a single image in a single step. One practical extension beyond one-step generation is an interactive system that generates an image iteratively, conditioned on ongoing linguistic input / feedback. This is significantly more challenging as such a system must understand and keep track of the ongoing context and history. In this work, we present a recurrent image generation model which takes into account both the generated output up to the current step as well as all past instructions for generation. We show that our model is able to generate the background, add new objects, apply simple transformations to existing objects, and correct previous mistakes. We believe our approach is an important step toward interactive generation.
The Hard-CoRe Coreference Corpus: Removing Gender and Number Cues for Difficult Pronominal Anaphora Resolution
Nov 02, 2018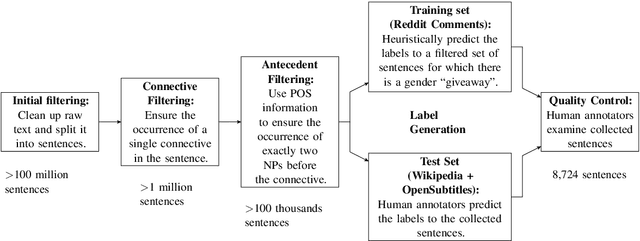


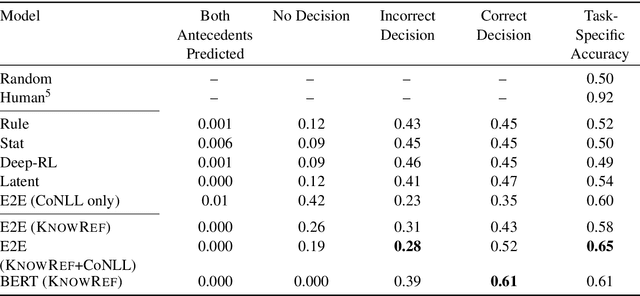
We introduce a new benchmark task for coreference resolution, Hard-CoRe, that targets common-sense reasoning and world knowledge. Previous coreference resolution tasks have been overly vulnerable to systems that simply exploit the number and gender of the antecedents, or have been handcrafted and do not reflect the diversity of sentences in naturally occurring text. With these limitations in mind, we present a resolution task that is both challenging and realistic. We demonstrate that various coreference systems, whether rule-based, feature-rich, graphical, or neural-based, perform at random or slightly above-random on the task, whereas human performance is very strong with high inter-annotator agreement. To explain this performance gap, we show empirically that state-of-the art models often fail to capture context and rely only on the antecedents to make a decision.
Relevance of Unsupervised Metrics in Task-Oriented Dialogue for Evaluating Natural Language Generation
Jun 29, 2017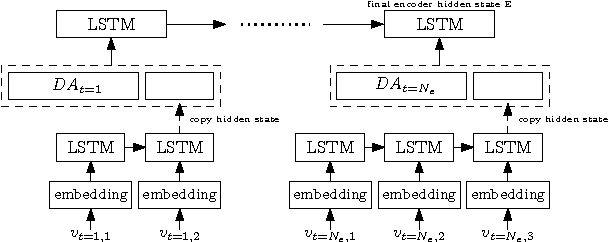

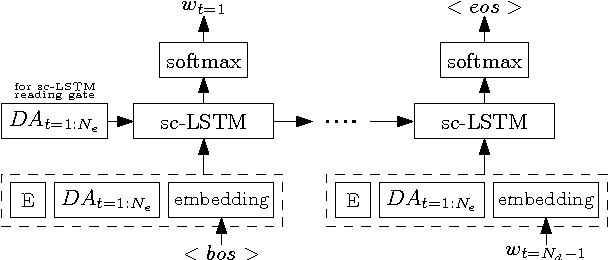
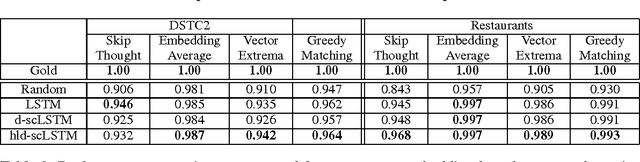
Automated metrics such as BLEU are widely used in the machine translation literature. They have also been used recently in the dialogue community for evaluating dialogue response generation. However, previous work in dialogue response generation has shown that these metrics do not correlate strongly with human judgment in the non task-oriented dialogue setting. Task-oriented dialogue responses are expressed on narrower domains and exhibit lower diversity. It is thus reasonable to think that these automated metrics would correlate well with human judgment in the task-oriented setting where the generation task consists of translating dialogue acts into a sentence. We conduct an empirical study to confirm whether this is the case. Our findings indicate that these automated metrics have stronger correlation with human judgments in the task-oriented setting compared to what has been observed in the non task-oriented setting. We also observe that these metrics correlate even better for datasets which provide multiple ground truth reference sentences. In addition, we show that some of the currently available corpora for task-oriented language generation can be solved with simple models and advocate for more challenging datasets.
A Frame Tracking Model for Memory-Enhanced Dialogue Systems
Jun 06, 2017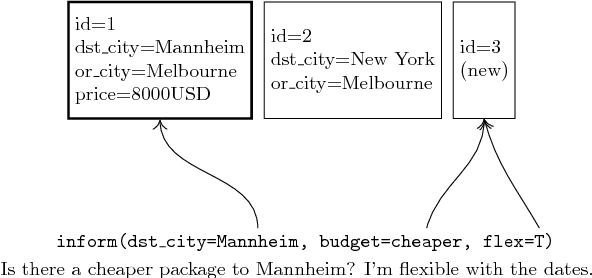

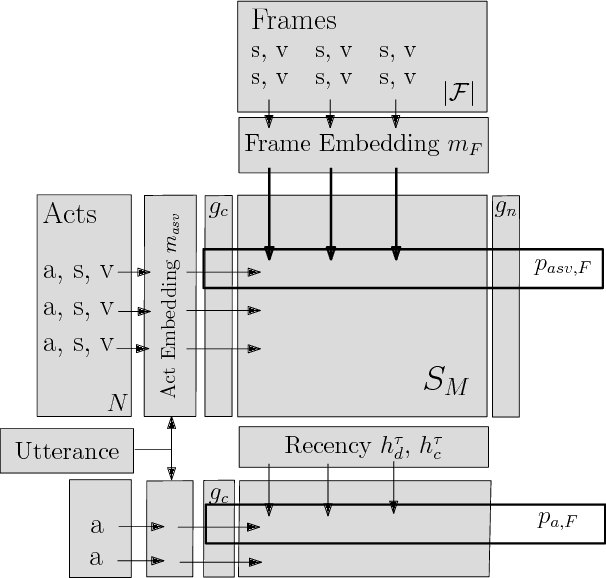

Recently, resources and tasks were proposed to go beyond state tracking in dialogue systems. An example is the frame tracking task, which requires recording multiple frames, one for each user goal set during the dialogue. This allows a user, for instance, to compare items corresponding to different goals. This paper proposes a model which takes as input the list of frames created so far during the dialogue, the current user utterance as well as the dialogue acts, slot types, and slot values associated with this utterance. The model then outputs the frame being referenced by each triple of dialogue act, slot type, and slot value. We show that on the recently published Frames dataset, this model significantly outperforms a previously proposed rule-based baseline. In addition, we propose an extensive analysis of the frame tracking task by dividing it into sub-tasks and assessing their difficulty with respect to our model.