 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Evaluation of Common-Sense Reasoning in Natural Language Understanding
Nov 05, 2018

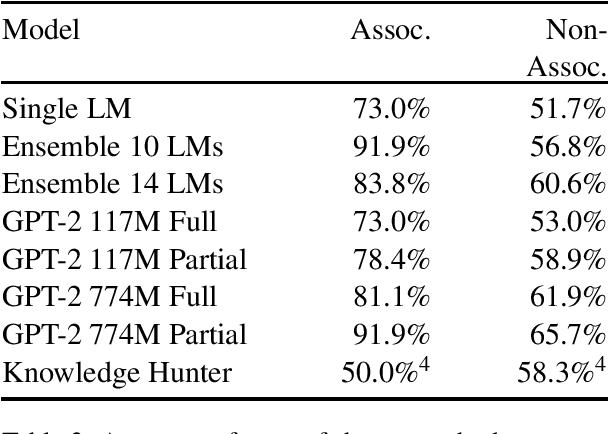
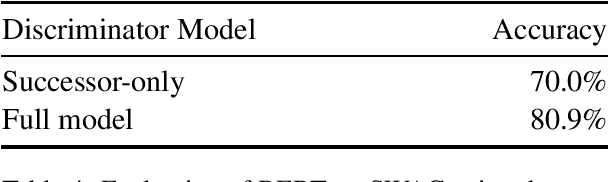
The NLP and ML communities have long been interested in developing models capable of common-sense reasoning, and recent works have significantly improved the state of the art on benchmarks like the Winograd Schema Challenge (WSC). Despite these advances, the complexity of tasks designed to test common-sense reasoning remains under-analyzed. In this paper, we make a case study of the Winograd Schema Challenge and, based on two new measures of instance-level complexity, design a protocol that both clarifies and qualifies the results of previous work. Our protocol accounts for the WSC's limited size and variable instance difficulty, properties common to other common-sense benchmarks. Accounting for these properties when assessing model results may prevent unjustified conclusions.
The Hard-CoRe Coreference Corpus: Removing Gender and Number Cues for Difficult Pronominal Anaphora Resolution
Nov 02, 2018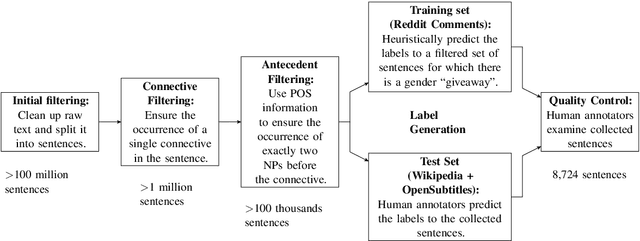


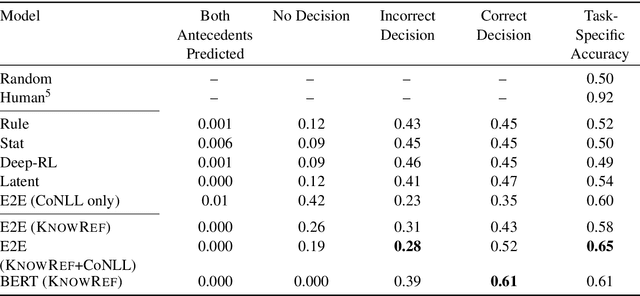
We introduce a new benchmark task for coreference resolution, Hard-CoRe, that targets common-sense reasoning and world knowledge. Previous coreference resolution tasks have been overly vulnerable to systems that simply exploit the number and gender of the antecedents, or have been handcrafted and do not reflect the diversity of sentences in naturally occurring text. With these limitations in mind, we present a resolution task that is both challenging and realistic. We demonstrate that various coreference systems, whether rule-based, feature-rich, graphical, or neural-based, perform at random or slightly above-random on the task, whereas human performance is very strong with high inter-annotator agreement. To explain this performance gap, we show empirically that state-of-the art models often fail to capture context and rely only on the antecedents to make a decision.
Safe Policy Improvement with Baseline Bootstrapping
Jun 14, 2018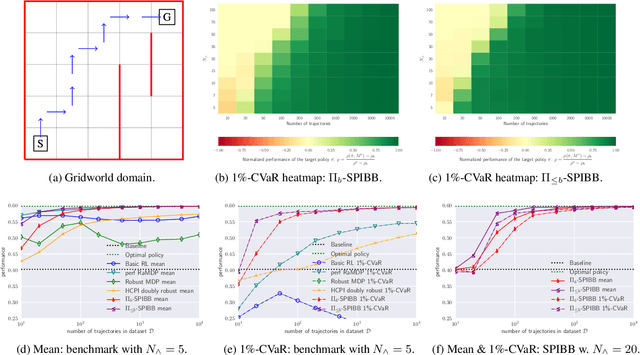

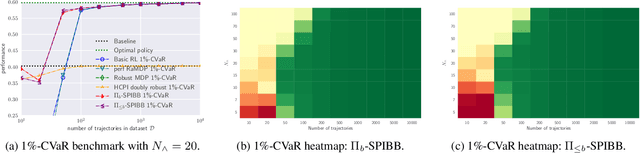
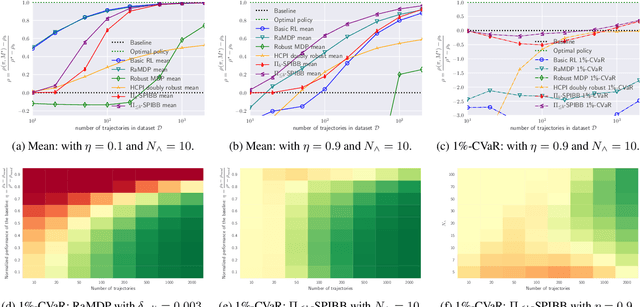
A common goal in Reinforcement Learning is to derive a good strategy given a limited batch of data. In this paper, we adopt the safe policy improvement (SPI) approach: we compute a target policy guaranteed to perform at least as well as a given baseline policy, approximately and with high probability. Our SPI strategy, inspired by the knows-what-it-knows paradigm, consists in bootstrapping the target with the baseline when the target does not know. We develop two computationally efficient bootstrapping algorithms, one value-based and one policy-based, both accompanied by theoretical SPI bounds for the tabular case. We empirically show the limits of the existing algorithms on a small stochastic gridworld problem, and then demonstrate that our algorithms not only improve the worst-case scenario but also the mean performance.