 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe Policy Improvement with Baseline Bootstrapping
Paper and Code
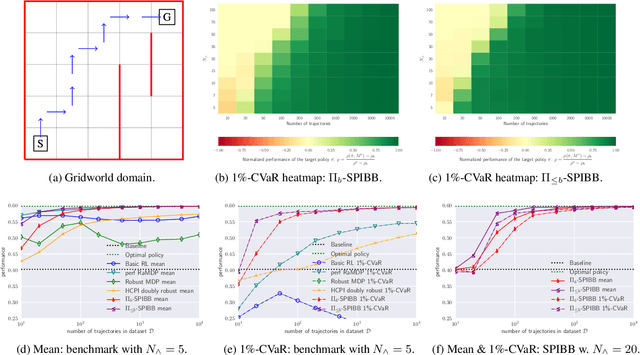

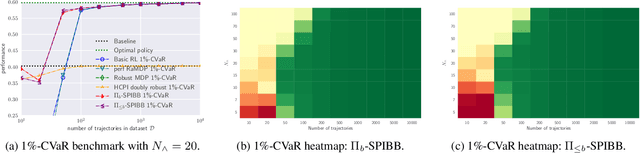
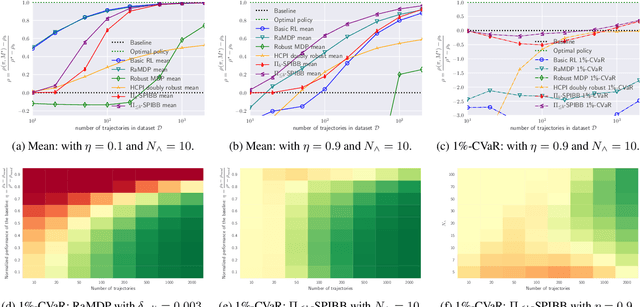
A common goal in Reinforcement Learning is to derive a good strategy given a limited batch of data. In this paper, we adopt the safe policy improvement (SPI) approach: we compute a target policy guaranteed to perform at least as well as a given baseline policy, approximately and with high probability. Our SPI strategy, inspired by the knows-what-it-knows paradigm, consists in bootstrapping the target with the baseline when the target does not know. We develop two computationally efficient bootstrapping algorithms, one value-based and one policy-based, both accompanied by theoretical SPI bounds for the tabular case. We empirically show the limits of the existing algorithms on a small stochastic gridworld problem, and then demonstrate that our algorithms not only improve the worst-case scenario but also the mean performance.