 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"It was 80% me, 20% AI": Seeking Authenticity in Co-Writing with Large Language Models
Nov 20, 2024
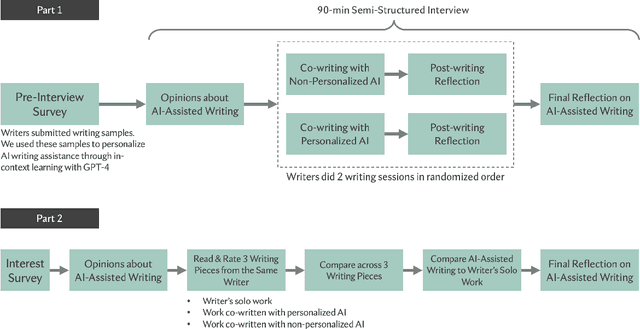


Given the rising proliferation and diversity of AI writing assistance tools, especially those powered by large language models (LLMs), both writers and readers may have concerns about the impact of these tools on the authenticity of writing work. We examine whether and how writers want to preserve their authentic voice when co-writing with AI tools and whether personalization of AI writing support could help achieve this goal. We conducted semi-structured interviews with 19 professional writers, during which they co-wrote with both personalized and non-personalized AI writing-support tools. We supplemented writers' perspectives with opinions from 30 avid readers about the written work co-produced with AI collected through an online survey. Our findings illuminate conceptions of authenticity in human-AI co-creation, which focus more on the process and experience of constructing creators' authentic selves. While writers reacted positively to personalized AI writing tools, they believed the form of personalization needs to target writers' growth and go beyond the phase of text production. Overall, readers' responses showed less concern about human-AI co-writing. Readers could not distinguish AI-assisted work, personalized or not, from writers' solo-written work and showed positive attitudes toward writers experimenting with new technology for creative writing.
Responsible AI Considerations in Text Summarization Research: A Review of Current Practices
Nov 18, 2023



AI and NLP publication venues have increasingly encouraged researchers to reflect on possible ethical considerations, adverse impacts, and other responsible AI issues their work might engender. However, for specific NLP tasks our understanding of how prevalent such issues are, or when and why these issues are likely to arise, remains limited. Focusing on text summarization -- a common NLP task largely overlooked by the responsible AI community -- we examine research and reporting practices in the current literature. We conduct a multi-round qualitative analysis of 333 summarization papers from the ACL Anthology published between 2020-2022. We focus on how, which, and when responsible AI issues are covered, which relevant stakeholders are considered, and mismatches between stated and realized research goals. We also discuss current evaluation practices and consider how authors discuss the limitations of both prior work and their own work. Overall, we find that relatively few papers engage with possible stakeholders or contexts of use, which limits their consideration of potential downstream adverse impacts or other responsible AI issues. Based on our findings, we make recommendations on concrete practices and research directions.
Deep Language Networks: Joint Prompt Training of Stacked LLMs using Variational Inference
Jun 21, 2023



We view large language models (LLMs) as stochastic \emph{language layers} in a network, where the learnable parameters are the natural language \emph{prompts} at each layer. We stack two such layers, feeding the output of one layer to the next. We call the stacked architecture a \emph{Deep Language Network} (DLN). We first show how to effectively perform prompt optimization for a 1-Layer language network (DLN-1). We then show how to train 2-layer DLNs (DLN-2), where two prompts must be learnt. We consider the output of the first layer as a latent variable to marginalize, and devise a variational inference algorithm for joint prompt training. A DLN-2 reaches higher performance than a single layer, sometimes comparable to few-shot GPT-4 even when each LLM in the network is smaller and less powerful. The DLN code is open source: https://github.com/microsoft/deep-language-networks .
Think Before You Act: Decision Transformers with Internal Working Memory
May 24, 2023Large language model (LLM)-based decision-making agents have shown the ability to generalize across multiple tasks. However, their performance relies on massive data and compute. We argue that this inefficiency stems from the forgetting phenomenon, in which a model memorizes its behaviors in parameters throughout training. As a result, training on a new task may deteriorate the model's performance on previous tasks. In contrast to LLMs' implicit memory mechanism, the human brain utilizes distributed memory storage, which helps manage and organize multiple skills efficiently, mitigating the forgetting phenomenon. Thus inspired, we propose an internal working memory module to store, blend, and retrieve information for different downstream tasks. Evaluation results show that the proposed method improves training efficiency and generalization in both Atari games and meta-world object manipulation tasks. Moreover, we demonstrate that memory fine-tuning further enhances the adaptability of the proposed architecture.
Investigating Failures to Generalize for Coreference Resolution Models
Mar 16, 2023



Coreference resolution models are often evaluated on multiple datasets. Datasets vary, however, in how coreference is realized -- i.e., how the theoretical concept of coreference is operationalized in the dataset -- due to factors such as the choice of corpora and annotation guidelines. We investigate the extent to which errors of current coreference resolution models are associated with existing differences in operationalization across datasets (OntoNotes, PreCo, and Winogrande). Specifically, we distinguish between and break down model performance into categories corresponding to several types of coreference, including coreferring generic mentions, compound modifiers, and copula predicates, among others. This break down helps us investigate how state-of-the-art models might vary in their ability to generalize across different coreference types. In our experiments, for example, models trained on OntoNotes perform poorly on generic mentions and copula predicates in PreCo. Our findings help calibrate expectations of current coreference resolution models; and, future work can explicitly account for those types of coreference that are empirically associated with poor generalization when developing models.
The KITMUS Test: Evaluating Knowledge Integration from Multiple Sources in Natural Language Understanding Systems
Dec 15, 2022Many state-of-the-art natural language understanding (NLU) models are based on pretrained neural language models. These models often make inferences using information from multiple sources. An important class of such inferences are those that require both background knowledge, presumably contained in a model's pretrained parameters, and instance-specific information that is supplied at inference time. However, the integration and reasoning abilities of NLU models in the presence of multiple knowledge sources have been largely understudied. In this work, we propose a test suite of coreference resolution tasks that require reasoning over multiple facts. Our dataset is organized into subtasks that differ in terms of which knowledge sources contain relevant facts. We evaluate state-of-the-art coreference resolution models on our dataset. Our results indicate that several models struggle to reason on-the-fly over knowledge observed both at pretrain time and at inference time. However, with task-specific training, a subset of models demonstrates the ability to integrate certain knowledge types from multiple sources.
Deconstructing NLG Evaluation: Evaluation Practices, Assumptions, and Their Implications
May 13, 2022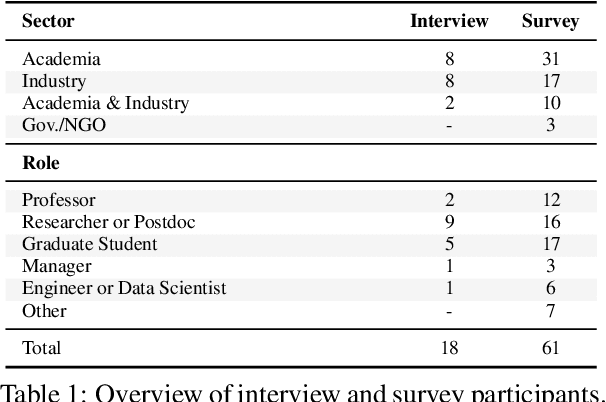
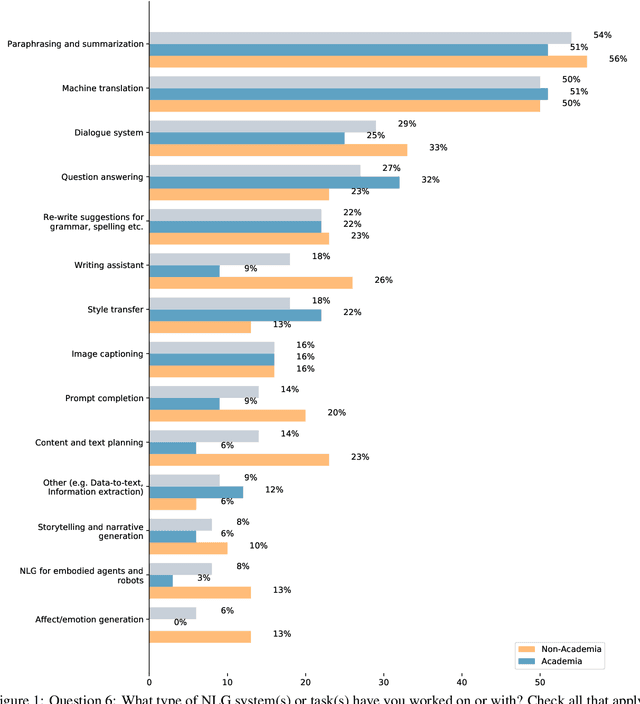
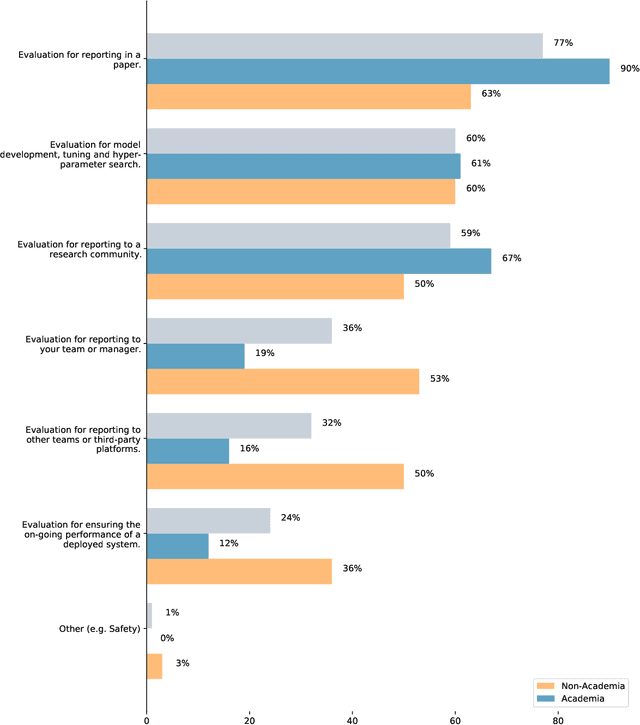
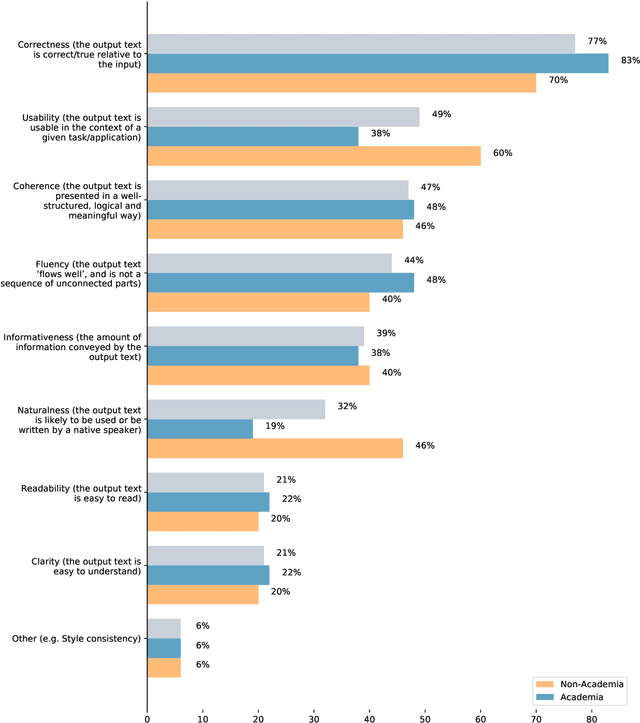
There are many ways to express similar things in text, which makes evaluating natural language generation (NLG) systems difficult. Compounding this difficulty is the need to assess varying quality criteria depending on the deployment setting. While the landscape of NLG evaluation has been well-mapped, practitioners' goals, assumptions, and constraints -- which inform decisions about what, when, and how to evaluate -- are often partially or implicitly stated, or not stated at all. Combining a formative semi-structured interview study of NLG practitioners (N=18) with a survey study of a broader sample of practitioners (N=61), we surface goals, community practices, assumptions, and constraints that shape NLG evaluations, examining their implications and how they embody ethical considerations.
Modeling Event Plausibility with Consistent Conceptual Abstraction
Apr 20, 2021

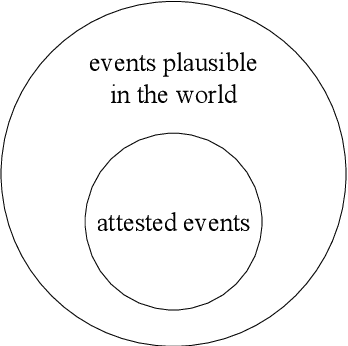

Understanding natural language requires common sense, one aspect of which is the ability to discern the plausibility of events. While distributional models -- most recently pre-trained, Transformer language models -- have demonstrated improvements in modeling event plausibility, their performance still falls short of humans'. In this work, we show that Transformer-based plausibility models are markedly inconsistent across the conceptual classes of a lexical hierarchy, inferring that "a person breathing" is plausible while "a dentist breathing" is not, for example. We find this inconsistency persists even when models are softly injected with lexical knowledge, and we present a simple post-hoc method of forcing model consistency that improves correlation with human plausibility judgements.
An Analysis of Dataset Overlap on Winograd-Style Tasks
Nov 09, 2020
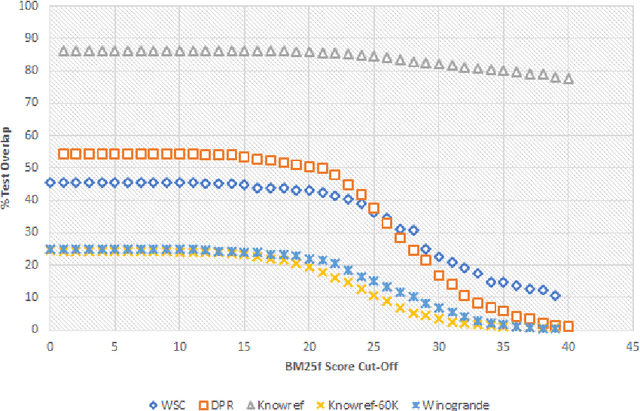
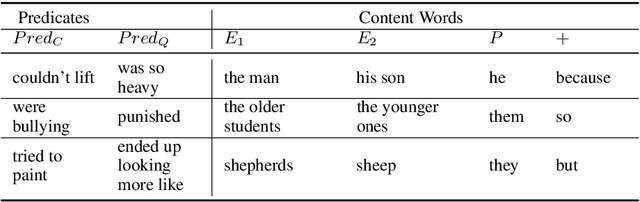
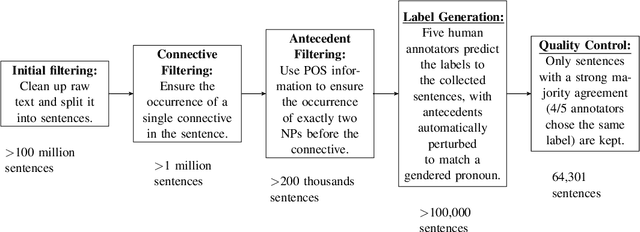
The Winograd Schema Challenge (WSC) and variants inspired by it have become important benchmarks for common-sense reasoning (CSR). Model performance on the WSC has quickly progressed from chance-level to near-human using neural language models trained on massive corpora. In this paper, we analyze the effects of varying degrees of overlap between these training corpora and the test instances in WSC-style tasks. We find that a large number of test instances overlap considerably with the corpora on which state-of-the-art models are (pre)trained, and that a significant drop in classification accuracy occurs when we evaluate models on instances with minimal overlap. Based on these results, we develop the KnowRef-60K dataset, which consists of over 60k pronoun disambiguation problems scraped from web data. KnowRef-60K is the largest corpus to date for WSC-style common-sense reasoning and exhibits a significantly lower proportion of overlaps with current pretraining corpora.
ALFWorld: Aligning Text and Embodied Environments for Interactive Learning
Oct 08, 2020



Given a simple request (e.g., Put a washed apple in the kitchen fridge), humans can reason in purely abstract terms by imagining action sequences and scoring their likelihood of success, prototypicality, and efficiency, all without moving a muscle. Once we see the kitchen in question, we can update our abstract plans to fit the scene. Embodied agents require the same abilities, but existing work does not yet provide the infrastructure necessary for both reasoning abstractly and executing concretely. We address this limitation by introducing ALFWorld, a simulator that enables agents to learn abstract, text-based policies in TextWorld (C\^ot\'e et al., 2018) and then execute goals from the ALFRED benchmark (Shridhar et al., 2020) in a rich visual environment. ALFWorld enables the creation of a new BUTLER agent whose abstract knowledge, learned in TextWorld, corresponds directly to concrete, visually grounded actions. In turn, as we demonstrate empirically, this fosters better agent generalization than training only in the visually grounded environment. BUTLER's simple, modular design factors the problem to allow researchers to focus on models for improving every piece of the pipeline (language understanding, planning, navigation, visual scene understanding, and so forth).