 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Validity of Coreference-based Evaluations of Natural Language Understanding
Feb 18, 2026In this thesis, I refine our understanding as to what conclusions we can reach from coreference-based evaluations by expanding existing evaluation practices and considering the extent to which evaluation results are either converging or conflicting. First, I analyze standard coreference evaluations and show that their design often leads to non-generalizable conclusions due to issues of measurement validity - including contestedness (multiple, competing definitions of coreference) and convergent validity (evaluation results that rank models differently across benchmarks). Second, I propose and implement a novel evaluation focused on testing systems' ability to infer the relative plausibility of events, a key aspect of resolving coreference. Through this extended evaluation, I find that contemporary language models demonstrate strong performance on standard benchmarks - improving over earlier baseline systems within certain domains and types of coreference - but remain sensitive to the evaluation conditions: they often fail to generalize in ways one would expect a human to be capable of when evaluation contexts are slightly modified. Taken together, these findings clarify both the strengths, such as improved accuracy over baselines on widely used evaluations, and the limitations of the current NLP paradigm, including weaknesses in measurement validity, and suggest directions for future work in developing better evaluation methods and more genuinely generalizable systems.
Solving the Challenge Set without Solving the Task: On Winograd Schemas as a Test of Pronominal Coreference Resolution
Oct 12, 2024
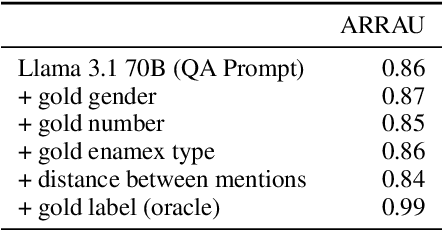


Challenge sets such as the Winograd Schema Challenge (WSC) are used to benchmark systems' ability to resolve ambiguities in natural language. If one assumes as in existing work that solving a given challenge set is at least as difficult as solving some more general task, then high performance on the challenge set should indicate high performance on the general task overall. However, we show empirically that this assumption of difficulty does not always hold. In particular, we demonstrate that despite the strong performance of prompted language models (LMs) on the WSC and its variants, these same modeling techniques perform relatively poorly at resolving certain pronominal ambiguities attested in OntoNotes and related datasets that are perceived to be easier. Motivated by these findings, we propose a method for ensembling a prompted LM with a supervised, task-specific system that is overall more accurate at resolving pronominal coreference across datasets. Finally, we emphasize that datasets involving the same linguistic phenomenon draw on distinct, but overlapping, capabilities, and evaluating on any one dataset alone does not provide a complete picture of a system's overall capability.
A Controlled Reevaluation of Coreference Resolution Models
Mar 31, 2024
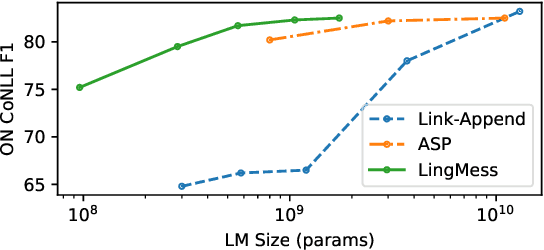
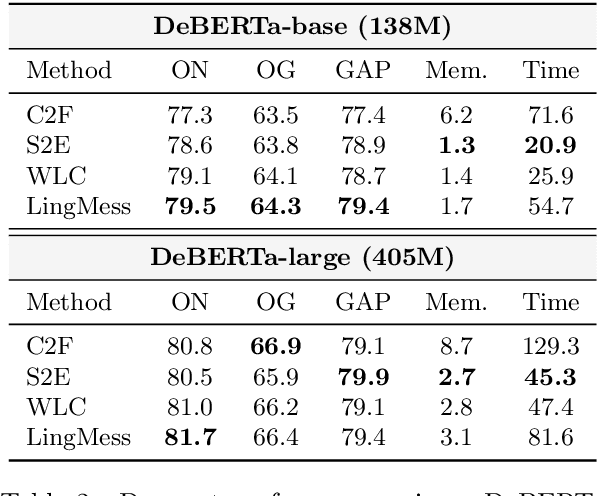

All state-of-the-art coreference resolution (CR) models involve finetuning a pretrained language model. Whether the superior performance of one CR model over another is due to the choice of language model or other factors, such as the task-specific architecture, is difficult or impossible to determine due to lack of a standardized experimental setup. To resolve this ambiguity, we systematically evaluate five CR models and control for certain design decisions including the pretrained language model used by each. When controlling for language model size, encoder-based CR models outperform more recent decoder-based models in terms of both accuracy and inference speed. Surprisingly, among encoder-based CR models, more recent models are not always more accurate, and the oldest CR model that we test generalizes the best to out-of-domain textual genres. We conclude that controlling for the choice of language model reduces most, but not all, of the increase in F1 score reported in the past five years.
Investigating Failures to Generalize for Coreference Resolution Models
Mar 16, 2023



Coreference resolution models are often evaluated on multiple datasets. Datasets vary, however, in how coreference is realized -- i.e., how the theoretical concept of coreference is operationalized in the dataset -- due to factors such as the choice of corpora and annotation guidelines. We investigate the extent to which errors of current coreference resolution models are associated with existing differences in operationalization across datasets (OntoNotes, PreCo, and Winogrande). Specifically, we distinguish between and break down model performance into categories corresponding to several types of coreference, including coreferring generic mentions, compound modifiers, and copula predicates, among others. This break down helps us investigate how state-of-the-art models might vary in their ability to generalize across different coreference types. In our experiments, for example, models trained on OntoNotes perform poorly on generic mentions and copula predicates in PreCo. Our findings help calibrate expectations of current coreference resolution models; and, future work can explicitly account for those types of coreference that are empirically associated with poor generalization when developing models.
Does Pre-training Induce Systematic Inference? How Masked Language Models Acquire Commonsense Knowledge
Dec 16, 2021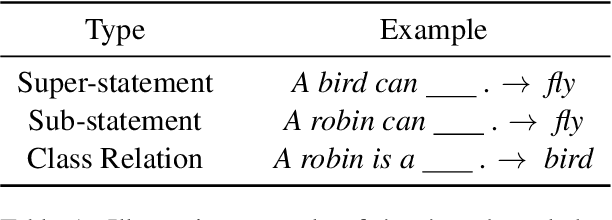
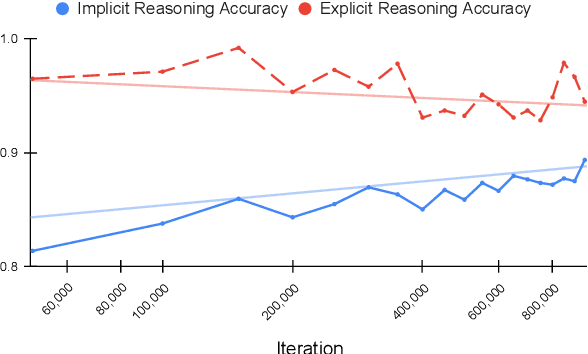
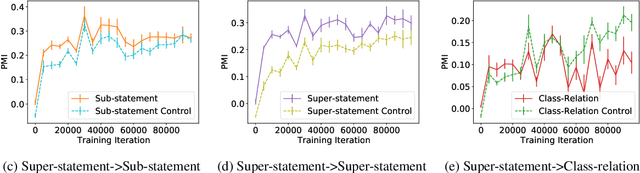
Transformer models pre-trained with a masked-language-modeling objective (e.g., BERT) encode commonsense knowledge as evidenced by behavioral probes; however, the extent to which this knowledge is acquired by systematic inference over the semantics of the pre-training corpora is an open question. To answer this question, we selectively inject verbalized knowledge into the minibatches of a BERT model during pre-training and evaluate how well the model generalizes to supported inferences. We find generalization does not improve over the course of pre-training, suggesting that commonsense knowledge is acquired from surface-level, co-occurrence patterns rather than induced, systematic reasoning.
Modeling Event Plausibility with Consistent Conceptual Abstraction
Apr 20, 2021


Understanding natural language requires common sense, one aspect of which is the ability to discern the plausibility of events. While distributional models -- most recently pre-trained, Transformer language models -- have demonstrated improvements in modeling event plausibility, their performance still falls short of humans'. In this work, we show that Transformer-based plausibility models are markedly inconsistent across the conceptual classes of a lexical hierarchy, inferring that "a person breathing" is plausible while "a dentist breathing" is not, for example. We find this inconsistency persists even when models are softly injected with lexical knowledge, and we present a simple post-hoc method of forcing model consistency that improves correlation with human plausibility judgements.
Can a Gorilla Ride a Camel? Learning Semantic Plausibility from Text
Nov 13, 2019


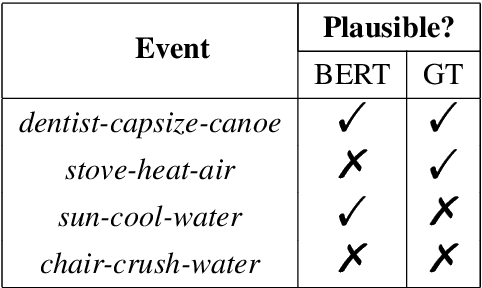
Modeling semantic plausibility requires commonsense knowledge about the world and has been used as a testbed for exploring various knowledge representations. Previous work has focused specifically on modeling physical plausibility and shown that distributional methods fail when tested in a supervised setting. At the same time, distributional models, namely large pretrained language models, have led to improved results for many natural language understanding tasks. In this work, we show that these pretrained language models are in fact effective at modeling physical plausibility in the supervised setting. We therefore present the more difficult problem of learning to model physical plausibility directly from text. We create a training set by extracting attested events from a large corpus, and we provide a baseline for training on these attested events in a self-supervised manner and testing on a physical plausibility task. We believe results could be further improved by injecting explicit commonsense knowledge into a distributional model.
* Accepted at COIN@EMNLP 2019
Faster and More Accurate Trace-based Policy Evaluation via Overall Target Error Meta-Optimization
May 25, 2019
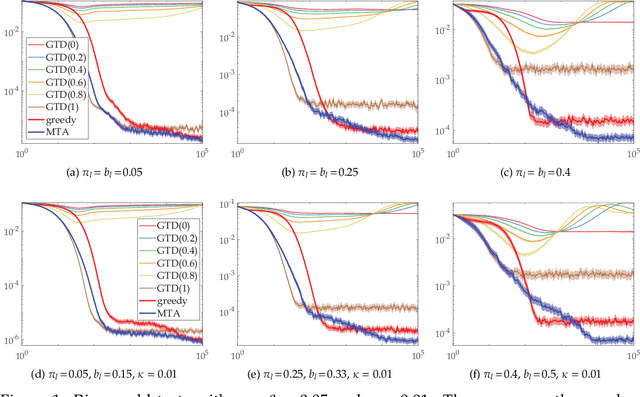
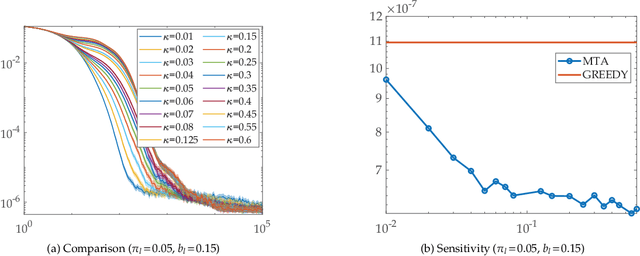
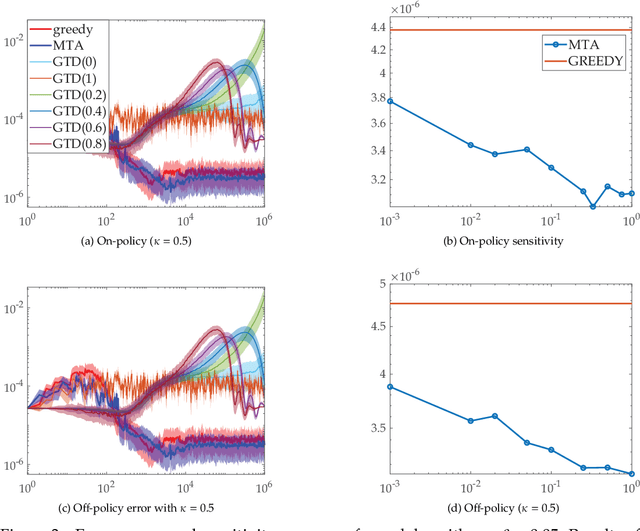
To improve the speed and accuracy of the trace based policy evaluation method TD({\lambda}), under appropriate assumptions, we derive and propose an off-policy compatible method of meta-learning state-based {\lambda}'s online with efficient incremental updates. Furthermore, we prove the derived bias-variance tradeoff minimization method, with slight adjustments, is equivalent to minimizing the overall target error in terms of state based {\lambda}'s. In experiments, the method shows significantly better performance when compared to the existing method and the baselines.