 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolving the Challenge Set without Solving the Task: On Winograd Schemas as a Test of Pronominal Coreference Resolution
Paper and Code

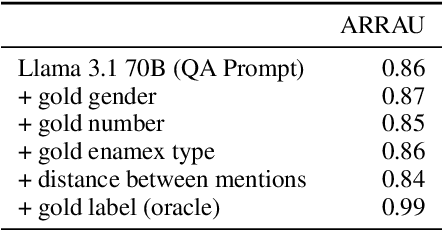


Challenge sets such as the Winograd Schema Challenge (WSC) are used to benchmark systems' ability to resolve ambiguities in natural language. If one assumes as in existing work that solving a given challenge set is at least as difficult as solving some more general task, then high performance on the challenge set should indicate high performance on the general task overall. However, we show empirically that this assumption of difficulty does not always hold. In particular, we demonstrate that despite the strong performance of prompted language models (LMs) on the WSC and its variants, these same modeling techniques perform relatively poorly at resolving certain pronominal ambiguities attested in OntoNotes and related datasets that are perceived to be easier. Motivated by these findings, we propose a method for ensembling a prompted LM with a supervised, task-specific system that is overall more accurate at resolving pronominal coreference across datasets. Finally, we emphasize that datasets involving the same linguistic phenomenon draw on distinct, but overlapping, capabilities, and evaluating on any one dataset alone does not provide a complete picture of a system's overall capability.