 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCItruS: Chunked Instruction-aware State Eviction for Long Sequence Modeling
Jun 17, 2024



Long sequence modeling has gained broad interest as large language models (LLMs) continue to advance. Recent research has identified that a large portion of hidden states within the key-value caches of Transformer models can be discarded (also termed evicted) without affecting the perplexity performance in generating long sequences. However, we show that these methods, despite preserving perplexity performance, often drop information that is important for solving downstream tasks, a problem which we call information neglect. To address this issue, we introduce Chunked Instruction-aware State Eviction (CItruS), a novel modeling technique that integrates the attention preferences useful for a downstream task into the eviction process of hidden states. In addition, we design a method for chunked sequence processing to further improve efficiency. Our training-free method exhibits superior performance on long sequence comprehension and retrieval tasks over several strong baselines under the same memory budget, while preserving language modeling perplexity.
A Controlled Reevaluation of Coreference Resolution Models
Mar 31, 2024
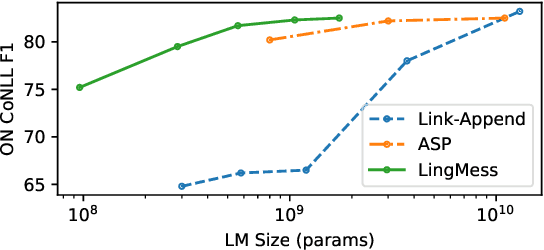
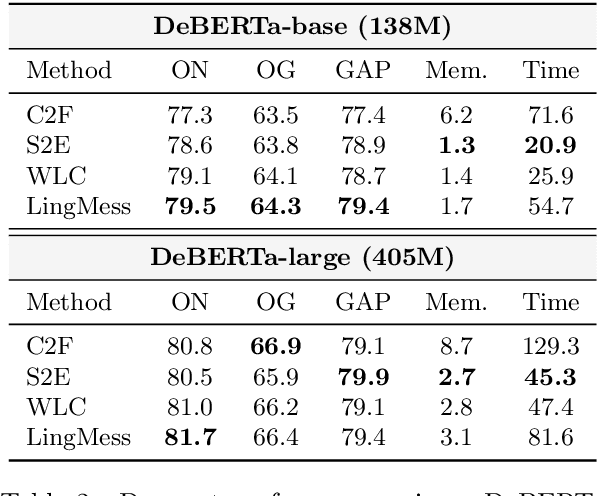

All state-of-the-art coreference resolution (CR) models involve finetuning a pretrained language model. Whether the superior performance of one CR model over another is due to the choice of language model or other factors, such as the task-specific architecture, is difficult or impossible to determine due to lack of a standardized experimental setup. To resolve this ambiguity, we systematically evaluate five CR models and control for certain design decisions including the pretrained language model used by each. When controlling for language model size, encoder-based CR models outperform more recent decoder-based models in terms of both accuracy and inference speed. Surprisingly, among encoder-based CR models, more recent models are not always more accurate, and the oldest CR model that we test generalizes the best to out-of-domain textual genres. We conclude that controlling for the choice of language model reduces most, but not all, of the increase in F1 score reported in the past five years.