 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-time Fake News from Adversarial Feedback
Oct 18, 2024



We show that existing evaluations for fake news detection based on conventional sources, such as claims on fact-checking websites, result in an increasing accuracy over time for LLM-based detectors -- even after their knowledge cutoffs. This suggests that recent popular political claims, which form the majority of fake news on such sources, are easily classified using surface-level shallow patterns. Instead, we argue that a proper fake news detection dataset should test a model's ability to reason factually about the current world by retrieving and reading related evidence. To this end, we develop a novel pipeline that leverages natural language feedback from a RAG-based detector to iteratively modify real-time news into deceptive fake news that challenges LLMs. Our iterative rewrite decreases the binary classification AUC by an absolute 17.5 percent for a strong RAG GPT-4o detector. Our experiments reveal the important role of RAG in both detecting and generating fake news, as retrieval-free LLM detectors are vulnerable to unseen events and adversarial attacks, while feedback from RAG detection helps discover more deceitful patterns in fake news.
Enhancing Large Language Models' Situated Faithfulness to External Contexts
Oct 18, 2024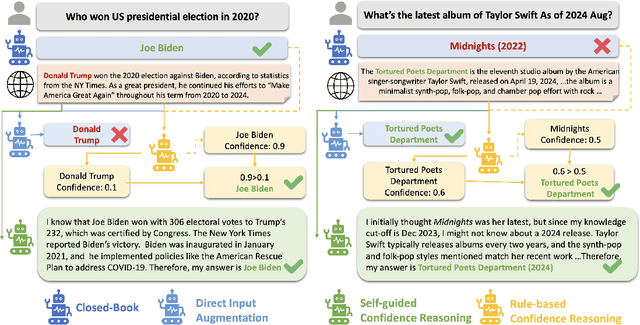
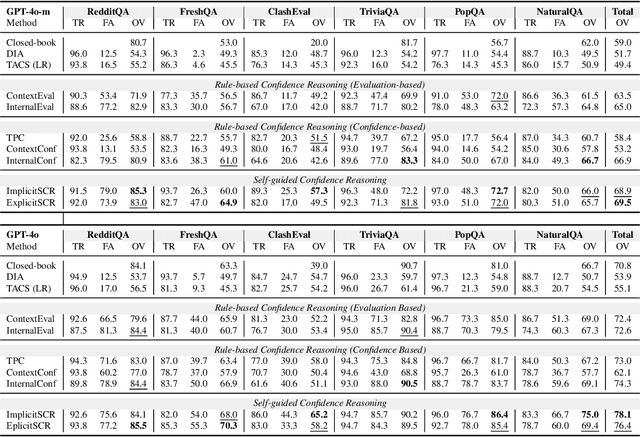
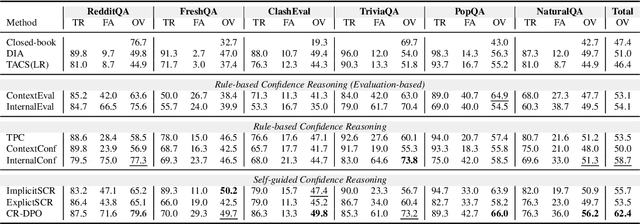

Large Language Models (LLMs) are often augmented with external information as contexts, but this external information can sometimes be inaccurate or even intentionally misleading. We argue that robust LLMs should demonstrate situated faithfulness, dynamically calibrating their trust in external information based on their confidence in the internal knowledge and the external context. To benchmark this capability, we evaluate LLMs across several QA datasets, including a newly created dataset called RedditQA featuring in-the-wild incorrect contexts sourced from Reddit posts. We show that when provided with both correct and incorrect contexts, both open-source and proprietary models tend to overly rely on external information, regardless of its factual accuracy. To enhance situated faithfulness, we propose two approaches: Self-Guided Confidence Reasoning (SCR) and Rule-Based Confidence Reasoning (RCR). SCR enables models to self-access the confidence of external information relative to their own internal knowledge to produce the most accurate answer. RCR, in contrast, extracts explicit confidence signals from the LLM and determines the final answer using predefined rules. Our results show that for LLMs with strong reasoning capabilities, such as GPT-4o and GPT-4o mini, SCR outperforms RCR, achieving improvements of up to 24.2% over a direct input augmentation baseline. Conversely, for a smaller model like Llama-3-8B, RCR outperforms SCR. Fine-tuning SCR with our proposed Confidence Reasoning Direct Preference Optimization (CR-DPO) method improves performance on both seen and unseen datasets, yielding an average improvement of 8.9% on Llama-3-8B. In addition to quantitative results, we offer insights into the relative strengths of SCR and RCR. Our findings highlight promising avenues for improving situated faithfulness in LLMs. The data and code are released.
CItruS: Chunked Instruction-aware State Eviction for Long Sequence Modeling
Jun 17, 2024



Long sequence modeling has gained broad interest as large language models (LLMs) continue to advance. Recent research has identified that a large portion of hidden states within the key-value caches of Transformer models can be discarded (also termed evicted) without affecting the perplexity performance in generating long sequences. However, we show that these methods, despite preserving perplexity performance, often drop information that is important for solving downstream tasks, a problem which we call information neglect. To address this issue, we introduce Chunked Instruction-aware State Eviction (CItruS), a novel modeling technique that integrates the attention preferences useful for a downstream task into the eviction process of hidden states. In addition, we design a method for chunked sequence processing to further improve efficiency. Our training-free method exhibits superior performance on long sequence comprehension and retrieval tasks over several strong baselines under the same memory budget, while preserving language modeling perplexity.
Tailoring Vaccine Messaging with Common-Ground Opinions
May 17, 2024

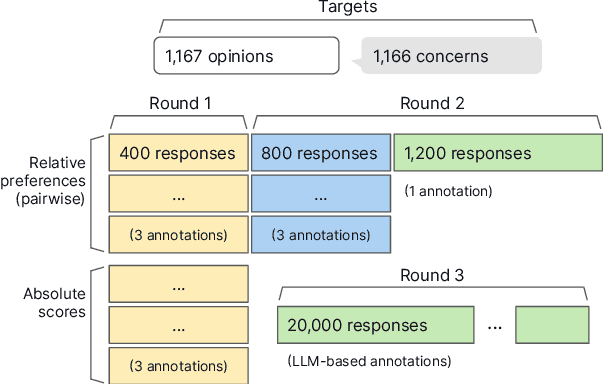

One way to personalize chatbot interactions is by establishing common ground with the intended reader. A domain where establishing mutual understanding could be particularly impactful is vaccine concerns and misinformation. Vaccine interventions are forms of messaging which aim to answer concerns expressed about vaccination. Tailoring responses in this domain is difficult, since opinions often have seemingly little ideological overlap. We define the task of tailoring vaccine interventions to a Common-Ground Opinion (CGO). Tailoring responses to a CGO involves meaningfully improving the answer by relating it to an opinion or belief the reader holds. In this paper we introduce TAILOR-CGO, a dataset for evaluating how well responses are tailored to provided CGOs. We benchmark several major LLMs on this task; finding GPT-4-Turbo performs significantly better than others. We also build automatic evaluation metrics, including an efficient and accurate BERT model that outperforms finetuned LLMs, investigate how to successfully tailor vaccine messaging to CGOs, and provide actionable recommendations from this investigation. Code and model weights: https://github.com/rickardstureborg/tailor-cgo Dataset: https://huggingface.co/datasets/DukeNLP/tailor-cgo
ChatShop: Interactive Information Seeking with Language Agents
Apr 15, 2024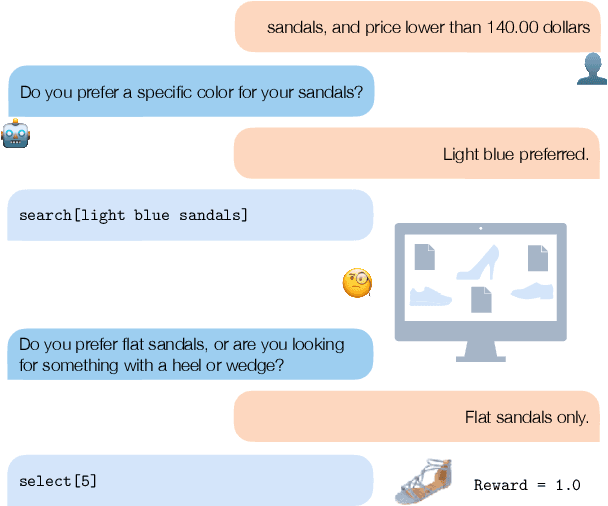
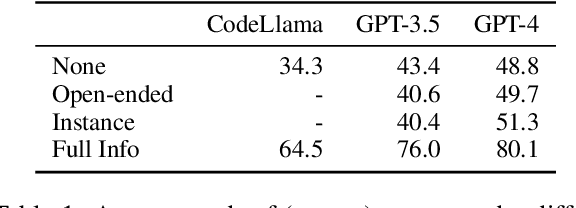
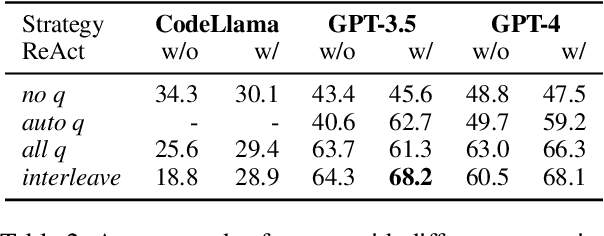
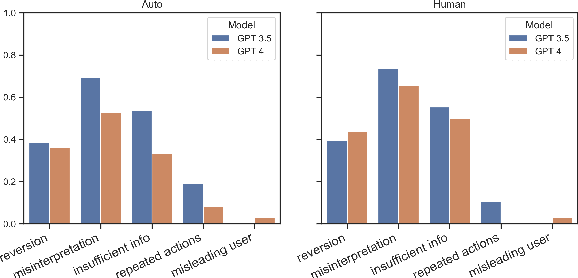
The desire and ability to seek new information strategically are fundamental to human learning but often overlooked in current language agent development. Using a web shopping task as an example, we show that it can be reformulated and solved as a retrieval task without a requirement of interactive information seeking. We then redesign the task to introduce a new role of shopper, serving as a realistically constrained communication channel. The agents in our proposed ChatShop task explore user preferences in open-ended conversation to make informed decisions. Our experiments demonstrate that the proposed task can effectively evaluate the agent's ability to explore and gradually accumulate information through multi-turn interaction. We also show that LLM-simulated shoppers serve as a good proxy to real human shoppers and discover similar error patterns of agents.
Analyzing Task-Encoding Tokens in Large Language Models
Jan 20, 2024In-context learning (ICL) has become an effective solution for few-shot learning in natural language processing. Past work has found that, during this process, representations of the last prompt token are utilized to store task reasoning procedures, thereby explaining the working mechanism of in-context learning. In this paper, we seek to locate and analyze other task-encoding tokens whose representations store task reasoning procedures. Supported by experiments that ablate the representations of different token types, we find that template and stopword tokens are the most prone to be task-encoding tokens. In addition, we demonstrate experimentally that lexical cues, repetition, and text formats are the main distinguishing characteristics of these tokens. Our work provides additional insights into how large language models (LLMs) leverage task reasoning procedures in ICL and suggests that future work may involve using task-encoding tokens to improve the computational efficiency of LLMs at inference time and their ability to handle long sequences.
Dataset and Baseline System for Multi-lingual Extraction and Normalization of Temporal and Numerical Expressions
Mar 31, 2023Temporal and numerical expression understanding is of great importance in many downstream Natural Language Processing (NLP) and Information Retrieval (IR) tasks. However, much previous work covers only a few sub-types and focuses only on entity extraction, which severely limits the usability of identified mentions. In order for such entities to be useful in downstream scenarios, coverage and granularity of sub-types are important; and, even more so, providing resolution into concrete values that can be manipulated. Furthermore, most previous work addresses only a handful of languages. Here we describe a multi-lingual evaluation dataset - NTX - covering diverse temporal and numerical expressions across 14 languages and covering extraction, normalization, and resolution. Along with the dataset we provide a robust rule-based system as a strong baseline for comparisons against other models to be evaluated in this dataset. Data and code are available at \url{https://aka.ms/NTX}.
Pre-training Transformers for Knowledge Graph Completion
Mar 28, 2023Learning transferable representation of knowledge graphs (KGs) is challenging due to the heterogeneous, multi-relational nature of graph structures. Inspired by Transformer-based pretrained language models' success on learning transferable representation for texts, we introduce a novel inductive KG representation model (iHT) for KG completion by large-scale pre-training. iHT consists of a entity encoder (e.g., BERT) and a neighbor-aware relational scoring function both parameterized by Transformers. We first pre-train iHT on a large KG dataset, Wikidata5M. Our approach achieves new state-of-the-art results on matched evaluations, with a relative improvement of more than 25% in mean reciprocal rank over previous SOTA models. When further fine-tuned on smaller KGs with either entity and relational shifts, pre-trained iHT representations are shown to be transferable, significantly improving the performance on FB15K-237 and WN18RR.
A Tale of Two Linkings: Dynamically Gating between Schema Linking and Structural Linking for Text-to-SQL Parsing
Sep 30, 2020
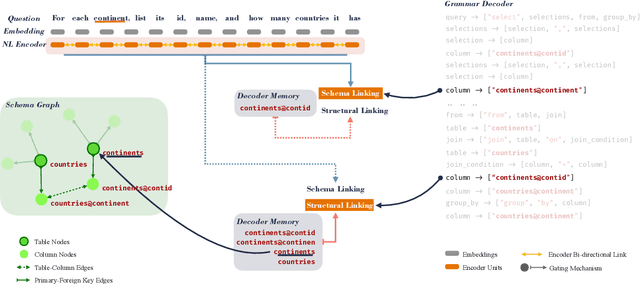
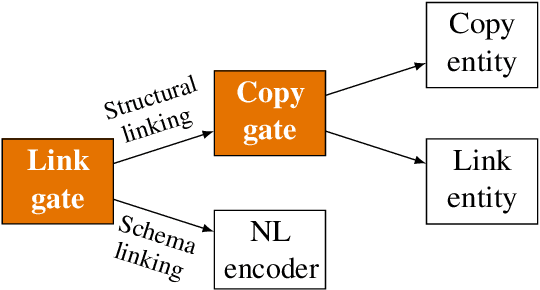

In Text-to-SQL semantic parsing, selecting the correct entities (tables and columns) to output is both crucial and challenging; the parser is required to connect the natural language (NL) question and the current SQL prediction with the structured world, i.e., the database. We formulate two linking processes to address this challenge: schema linking which links explicit NL mentions to the database and structural linking which links the entities in the output SQL with their structural relationships in the database schema. Intuitively, the effects of these two linking processes change based on the entity being generated, thus we propose to dynamically choose between them using a gating mechanism. Integrating the proposed method with two graph neural network based semantic parsers together with BERT representations demonstrates substantial gains in parsing accuracy on the challenging Spider dataset. Analyses show that our method helps to enhance the structure of the model output when generating complicated SQL queries and offers explainable predictions.
HittER: Hierarchical Transformers for Knowledge Graph Embeddings
Aug 28, 2020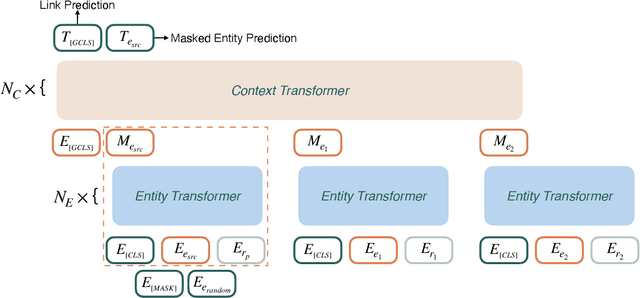
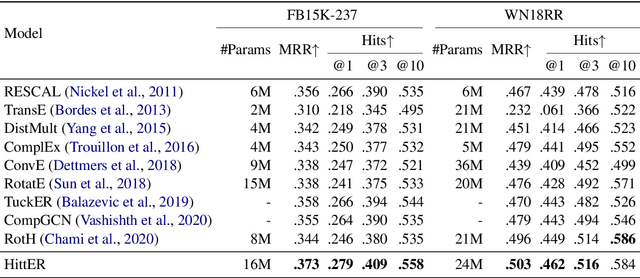
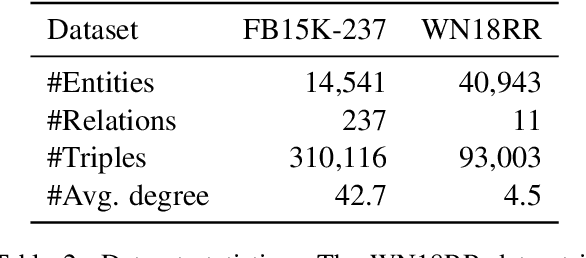
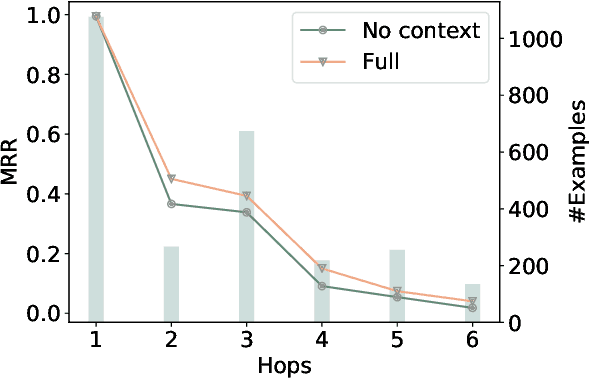
This paper examines the challenging problem of learning representations of entities and relations in a complex multi-relational knowledge graph. We propose HittER, a Hierarchical Transformer model to jointly learn Entity-relation composition and Relational contextualization based on a source entity's neighborhood. Our proposed model consists of two different Transformer blocks: the bottom block extracts features of each entity-relation pair in the local neighborhood of the source entity and the top block aggregates the relational information from the outputs of the bottom block. We further design a masked entity prediction task to balance information from the relational context and the source entity itself. Evaluated on the task of link prediction, our approach achieves new state-of-the-art results on two standard benchmark datasets FB15K-237 and WN18RR.