 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnce-For-All: A Train-Once and Select-Anytime Framework for Multimodal Instruction Tuning
May 26, 2026Multimodal instruction tuning is the de facto recipe for adapting vision language models (VLMs), yet instruction data are highly redundant, making data selection critical for training efficiency. Existing methods derive selection signals from a specific model or dataset, so whenever the target model or candidate pool changes, the criteria must be recomputed from scratch at substantial cost. To address this, we propose OFA, a data selection framework that trains a reusable selector once and applies it to any dataset or model without recomputation. OFA clusters multimodal instructions in a frozen CLIP space, derives pseudo labels from the cluster structure, and trains a lightweight selector for only a few epochs; samples on which this selector is least confident are selected as the most informative. Once trained, the frozen selector transfers directly across datasets and model scales. The selector is trained once on LLaVA-665K and applied both to LLaVA-665K itself and, without any retraining, to the unseen Vision-Flan-186K. Selecting only 15% of the data, OFA achieves 98.3% of full data performance across 10 downstream benchmarks; on the smaller Vision-Flan-186K, the transferred selector surpasses full data training by 10.6%, confirming that the learned signal generalizes to datasets never seen during selector training. The same selected subsets benefit VLMs at both Qwen2.5-VL-3B and LLaVA-v1.5-7B without per model recomputation, decoupling selection from the target model. These results demonstrate that a single, transferable selector provides an effective and reusable solution for efficient multimodal instruction tuning.
Evo-Depth: A Lightweight Depth-Enhanced Vision-Language-Action Model
May 14, 2026Vision-Language-Action models have emerged as a promising paradigm for robotic manipulation by unifying perception, language grounding, and action generation. However, they often struggle in scenarios requiring precise spatial understanding, as current VLA models primarily rely on 2D visual representations that lack depth information and detailed spatial relationships. While recent approaches incorporate explicit 3D inputs such as depth maps or point clouds to address this issue, they often increase system complexity, require additional sensors, and remain vulnerable to sensing noise and reconstruction errors. Another line of work explores implicit 3D-aware spatial modeling directly from RGB observations without extra sensors, but it often relies on large geometry foundation models, resulting in higher training and deployment costs. To address these challenges, we propose Evo-Depth, a lightweight depth-enhanced VLA framework that enhances spatially grounded manipulation without relying on additional sensing hardware or compromising deployment efficiency. Evo-Depth employs a lightweight Implicit Depth Encoding Module to extract compact depth features from multi-view RGB images. These features are incorporated into vision-language representations through a Spatial Enhancement Module via depth-aware modulation, enabling efficient spatial-semantic enhancement. A Progressive Alignment Training strategy is further introduced to align the resulting depth-enhanced representations with downstream action learning. With only 0.9B parameters, Evo-Depth achieves superior performance across four simulation benchmarks. In real-world experiments, Evo-Depth attains the highest average success rate while also exhibiting the smallest model size, lowest GPU memory usage, and highest inference frequency among compared methods.
VisNec: Measuring and Leveraging Visual Necessity for Multimodal Instruction Tuning
Mar 01, 2026The effectiveness of multimodal instruction tuning depends not only on dataset scale, but critically on whether training samples genuinely require visual reasoning. However, existing instruction datasets often contain a substantial portion of visually redundant samples (solvable from text alone), as well as multimodally misaligned supervision that can degrade learning. To address this, we propose VisNec (Visual Necessity Score), a principled data selection framework that measures the marginal contribution of visual input during instruction tuning. By comparing predictive loss with and without visual context, VisNec identifies whether a training instance is vision-critical, redundant, or misaligned. To preserve task diversity, we combine VisNec with semantic clustering and select high-necessity samples within each cluster. Across 10 downstream benchmarks, training on only 15% of the LLaVA-665K dataset selected by VisNec achieves 100.2% of full-data performance. On the smaller Vision-Flan-186K dataset, our selection not only further reduces data size but also surpasses full-data training by 15.8%. These results demonstrate that measuring and leveraging visual necessity provides an effective solution for both efficient and robust multimodal instruction tuning. Codes and selected subsets will be released upon acceptance.
When Vision Meets Texts in Listwise Reranking
Jan 28, 2026Recent advancements in information retrieval have highlighted the potential of integrating visual and textual information, yet effective reranking for image-text documents remains challenging due to the modality gap and scarcity of aligned datasets. Meanwhile, existing approaches often rely on large models (7B to 32B parameters) with reasoning-based distillation, incurring unnecessary computational overhead while primarily focusing on textual modalities. In this paper, we propose Rank-Nexus, a multimodal image-text document reranker that performs listwise qualitative reranking on retrieved lists incorporating both images and texts. To bridge the modality gap, we introduce a progressive cross-modal training strategy. We first train modalities separately: leveraging abundant text reranking data, we distill knowledge into the text branch. For images, where data is scarce, we construct distilled pairs from multimodal large language model (MLLM) captions on image retrieval benchmarks. Subsequently, we distill a joint image-text reranking dataset. Rank-Nexus achieves outstanding performance on text reranking benchmarks (TREC, BEIR) and the challenging image reranking benchmark (INQUIRE, MMDocIR), using only a lightweight 2B pretrained visual-language model. This efficient design ensures strong generalization across diverse multimodal scenarios without excessive parameters or reasoning overhead.
Evo-1: Lightweight Vision-Language-Action Model with Preserved Semantic Alignment
Nov 06, 2025Vision-Language-Action (VLA) models have emerged as a powerful framework that unifies perception, language, and control, enabling robots to perform diverse tasks through multimodal understanding. However, current VLA models typically contain massive parameters and rely heavily on large-scale robot data pretraining, leading to high computational costs during training, as well as limited deployability for real-time inference. Moreover, most training paradigms often degrade the perceptual representations of the vision-language backbone, resulting in overfitting and poor generalization to downstream tasks. In this work, we present Evo-1, a lightweight VLA model that reduces computation and improves deployment efficiency, while maintaining strong performance without pretraining on robot data. Evo-1 builds on a native multimodal Vision-Language model (VLM), incorporating a novel cross-modulated diffusion transformer along with an optimized integration module, together forming an effective architecture. We further introduce a two-stage training paradigm that progressively aligns action with perception, preserving the representations of the VLM. Notably, with only 0.77 billion parameters, Evo-1 achieves state-of-the-art results on the Meta-World and RoboTwin suite, surpassing the previous best models by 12.4% and 6.9%, respectively, and also attains a competitive result of 94.8% on LIBERO. In real-world evaluations, Evo-1 attains a 78% success rate with high inference frequency and low memory overhead, outperforming all baseline methods. We release code, data, and model weights to facilitate future research on lightweight and efficient VLA models.
Enhancing Large Language Models' Situated Faithfulness to External Contexts
Oct 18, 2024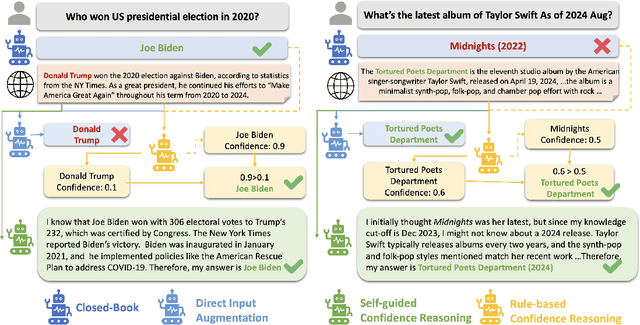
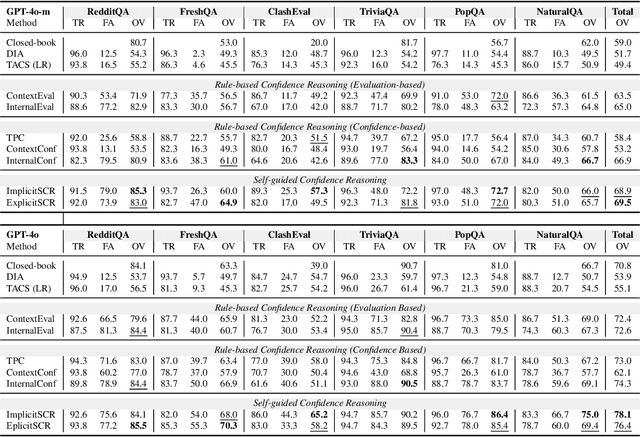
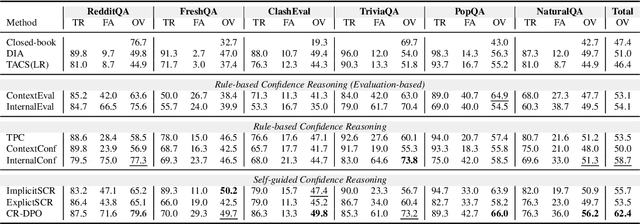

Large Language Models (LLMs) are often augmented with external information as contexts, but this external information can sometimes be inaccurate or even intentionally misleading. We argue that robust LLMs should demonstrate situated faithfulness, dynamically calibrating their trust in external information based on their confidence in the internal knowledge and the external context. To benchmark this capability, we evaluate LLMs across several QA datasets, including a newly created dataset called RedditQA featuring in-the-wild incorrect contexts sourced from Reddit posts. We show that when provided with both correct and incorrect contexts, both open-source and proprietary models tend to overly rely on external information, regardless of its factual accuracy. To enhance situated faithfulness, we propose two approaches: Self-Guided Confidence Reasoning (SCR) and Rule-Based Confidence Reasoning (RCR). SCR enables models to self-access the confidence of external information relative to their own internal knowledge to produce the most accurate answer. RCR, in contrast, extracts explicit confidence signals from the LLM and determines the final answer using predefined rules. Our results show that for LLMs with strong reasoning capabilities, such as GPT-4o and GPT-4o mini, SCR outperforms RCR, achieving improvements of up to 24.2% over a direct input augmentation baseline. Conversely, for a smaller model like Llama-3-8B, RCR outperforms SCR. Fine-tuning SCR with our proposed Confidence Reasoning Direct Preference Optimization (CR-DPO) method improves performance on both seen and unseen datasets, yielding an average improvement of 8.9% on Llama-3-8B. In addition to quantitative results, we offer insights into the relative strengths of SCR and RCR. Our findings highlight promising avenues for improving situated faithfulness in LLMs. The data and code are released.
AgileIR: Memory-Efficient Group Shifted Windows Attention for Agile Image Restoration
Sep 10, 2024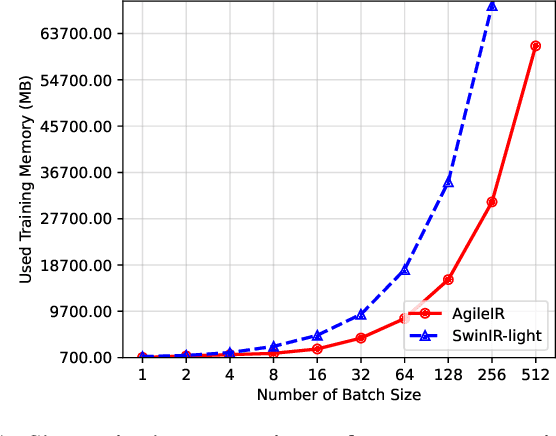
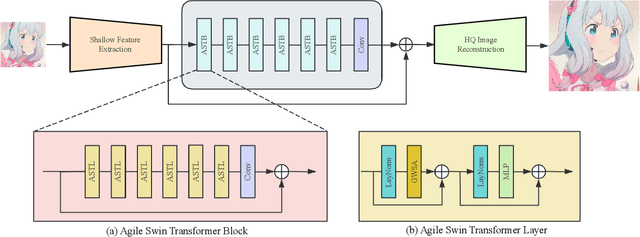
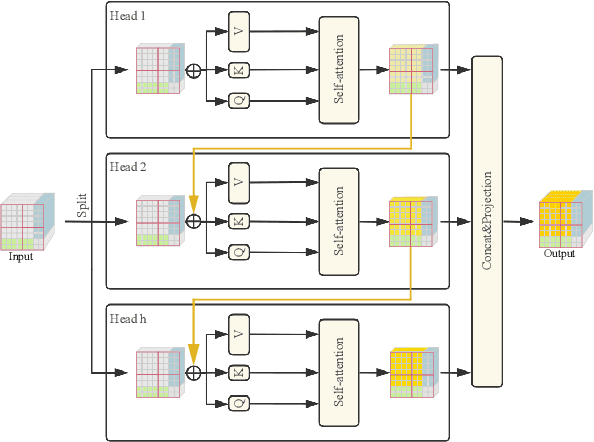
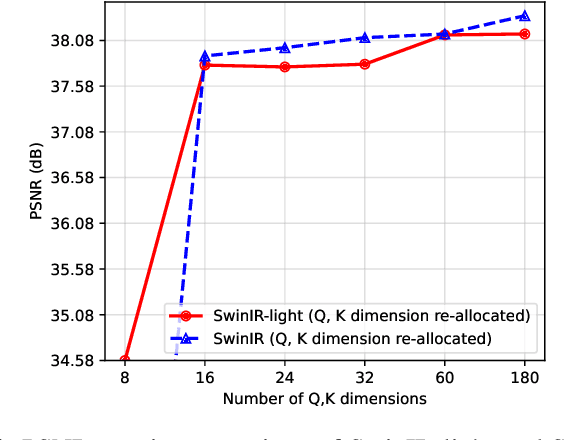
Image Transformers show a magnificent success in Image Restoration tasks. Nevertheless, most of transformer-based models are strictly bounded by exorbitant memory occupancy. Our goal is to reduce the memory consumption of Swin Transformer and at the same time speed up the model during training process. Thus, we introduce AgileIR, group shifted attention mechanism along with window attention, which sparsely simplifies the model in architecture. We propose Group Shifted Window Attention (GSWA) to decompose Shift Window Multi-head Self Attention (SW-MSA) and Window Multi-head Self Attention (W-MSA) into groups across their attention heads, contributing to shrinking memory usage in back propagation. In addition to that, we keep shifted window masking and its shifted learnable biases during training, in order to induce the model interacting across windows within the channel. We also re-allocate projection parameters to accelerate attention matrix calculation, which we found a negligible decrease in performance. As a result of experiment, compared with our baseline SwinIR and other efficient quantization models, AgileIR keeps the performance still at 32.20 dB on Set5 evaluation dataset, exceeding other methods with tailor-made efficient methods and saves over 50% memory while a large batch size is employed.
CFPFormer: Feature-pyramid like Transformer Decoder for Segmentation and Detection
Apr 23, 2024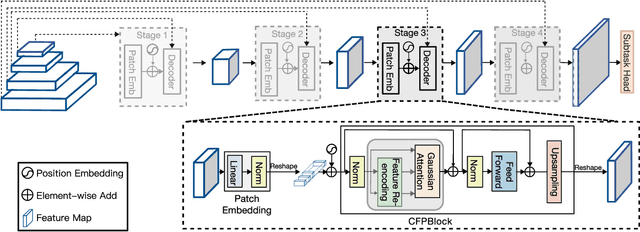
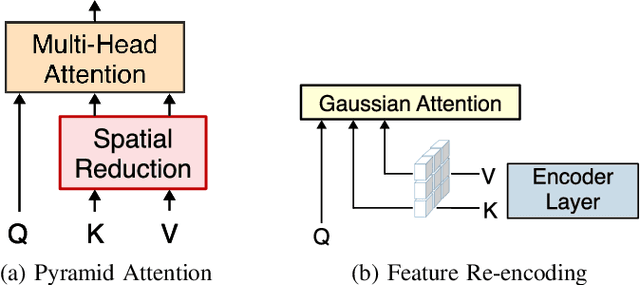
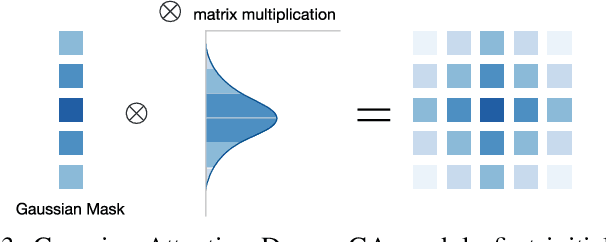
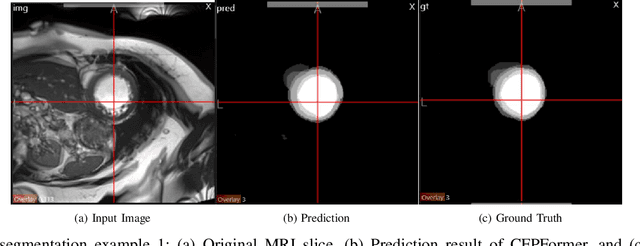
Feature pyramids have been widely adopted in convolutional neural networks (CNNs) and transformers for tasks like medical image segmentation and object detection. However, the currently existing models generally focus on the Encoder-side Transformer to extract features, from which decoder improvement can bring further potential with well-designed architecture. We propose CFPFormer, a novel decoder block that integrates feature pyramids and transformers. Specifically, by leveraging patch embedding, cross-layer feature concatenation, and Gaussian attention mechanisms, CFPFormer enhances feature extraction capabilities while promoting generalization across diverse tasks. Benefiting from Transformer structure and U-shaped Connections, our introduced model gains the ability to capture long-range dependencies and effectively up-sample feature maps. Our model achieves superior performance in detecting small objects compared to existing methods. We evaluate CFPFormer on medical image segmentation datasets and object detection benchmarks (VOC 2007, VOC2012, MS-COCO), demonstrating its effectiveness and versatility. On the ACDC Post-2017-MICCAI-Challenge online test set, our model reaches exceptionally impressive accuracy, and performed well compared with the original decoder setting in Synapse multi-organ segmentation dataset.
AccidentBlip2: Accident Detection With Multi-View MotionBlip2
Apr 19, 2024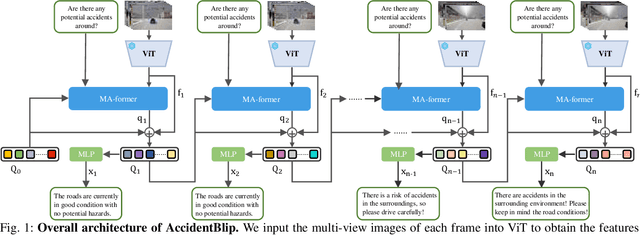
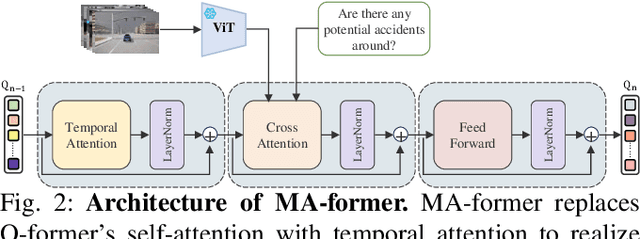
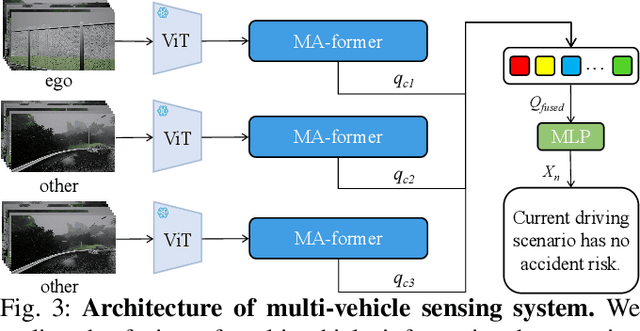

Multimodal Large Language Models (MLLMs) have shown outstanding capabilities in many areas of multimodal reasoning. Therefore, we use the reasoning ability of Multimodal Large Language Models for environment description and scene understanding in complex transportation environments. In this paper, we propose AccidentBlip2, a multimodal large language model that can predict in real time whether an accident risk will occur. Our approach involves feature extraction based on the temporal scene of the six-view surround view graphs and temporal inference using the temporal blip framework through the vision transformer. We then input the generated temporal token into the MLLMs for inference to determine whether an accident will occur or not. Since AccidentBlip2 does not rely on any BEV images and LiDAR, the number of inference parameters and the inference cost of MLLMs can be significantly reduced, and it also does not incur a large training overhead during training. AccidentBlip2 outperforms existing solutions on the DeepAccident dataset and can also provide a reference solution for end-to-end automated driving accident prediction.