 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgileIR: Memory-Efficient Group Shifted Windows Attention for Agile Image Restoration
Sep 10, 2024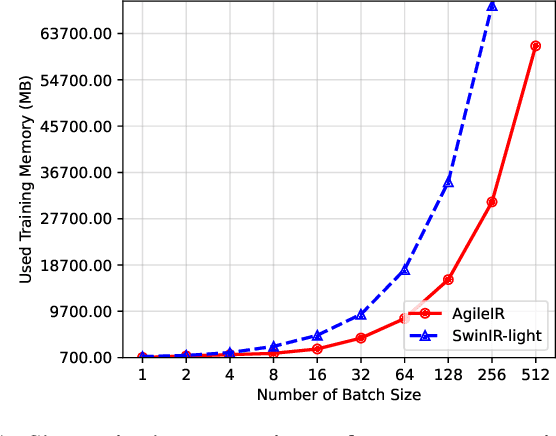
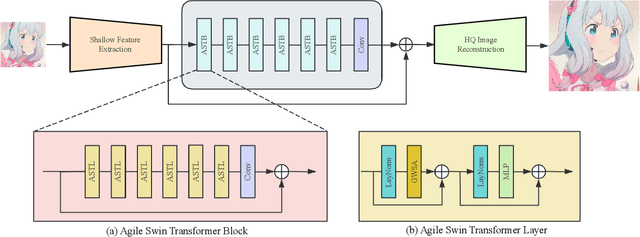
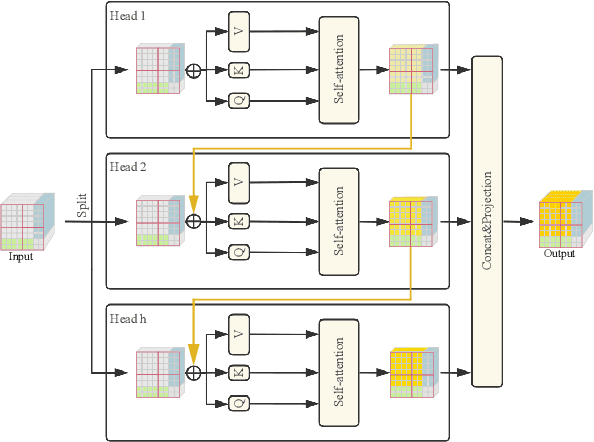
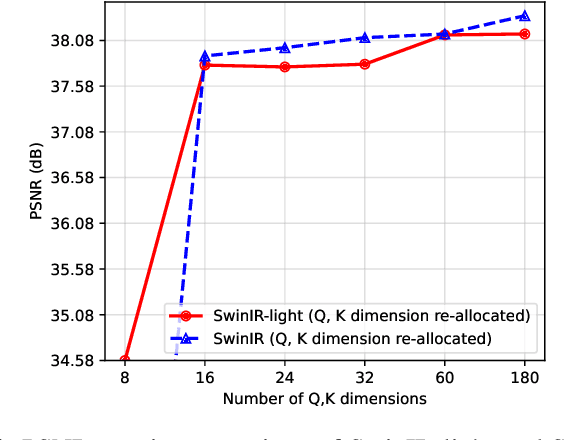
Image Transformers show a magnificent success in Image Restoration tasks. Nevertheless, most of transformer-based models are strictly bounded by exorbitant memory occupancy. Our goal is to reduce the memory consumption of Swin Transformer and at the same time speed up the model during training process. Thus, we introduce AgileIR, group shifted attention mechanism along with window attention, which sparsely simplifies the model in architecture. We propose Group Shifted Window Attention (GSWA) to decompose Shift Window Multi-head Self Attention (SW-MSA) and Window Multi-head Self Attention (W-MSA) into groups across their attention heads, contributing to shrinking memory usage in back propagation. In addition to that, we keep shifted window masking and its shifted learnable biases during training, in order to induce the model interacting across windows within the channel. We also re-allocate projection parameters to accelerate attention matrix calculation, which we found a negligible decrease in performance. As a result of experiment, compared with our baseline SwinIR and other efficient quantization models, AgileIR keeps the performance still at 32.20 dB on Set5 evaluation dataset, exceeding other methods with tailor-made efficient methods and saves over 50% memory while a large batch size is employed.
CFPFormer: Feature-pyramid like Transformer Decoder for Segmentation and Detection
Apr 23, 2024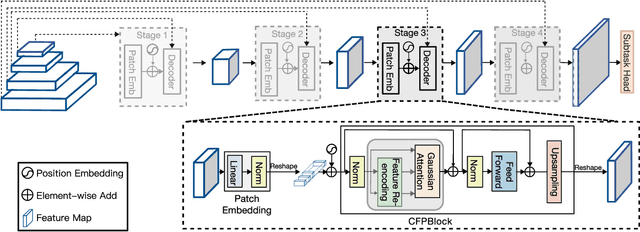
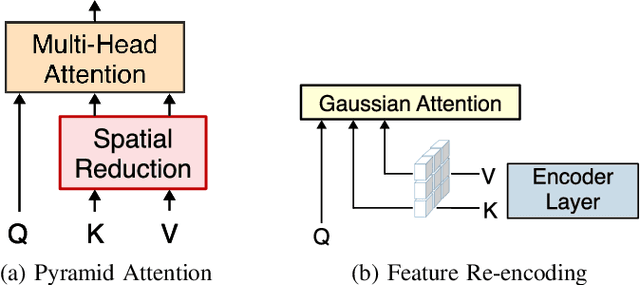
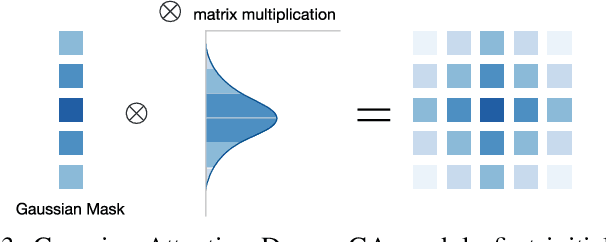
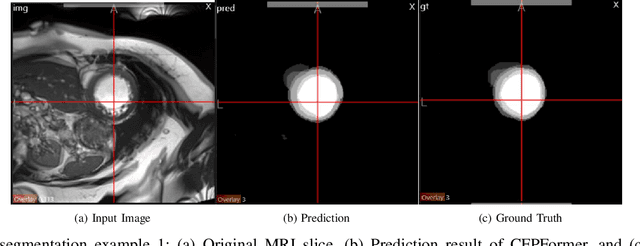
Feature pyramids have been widely adopted in convolutional neural networks (CNNs) and transformers for tasks like medical image segmentation and object detection. However, the currently existing models generally focus on the Encoder-side Transformer to extract features, from which decoder improvement can bring further potential with well-designed architecture. We propose CFPFormer, a novel decoder block that integrates feature pyramids and transformers. Specifically, by leveraging patch embedding, cross-layer feature concatenation, and Gaussian attention mechanisms, CFPFormer enhances feature extraction capabilities while promoting generalization across diverse tasks. Benefiting from Transformer structure and U-shaped Connections, our introduced model gains the ability to capture long-range dependencies and effectively up-sample feature maps. Our model achieves superior performance in detecting small objects compared to existing methods. We evaluate CFPFormer on medical image segmentation datasets and object detection benchmarks (VOC 2007, VOC2012, MS-COCO), demonstrating its effectiveness and versatility. On the ACDC Post-2017-MICCAI-Challenge online test set, our model reaches exceptionally impressive accuracy, and performed well compared with the original decoder setting in Synapse multi-organ segmentation dataset.