 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Time and Space: Decoupled Spatio-Temporal Alignment for Video Grounding
Apr 09, 2026Spatio-Temporal Video Grounding requires jointly localizing target objects across both temporal and spatial dimensions based on natural language queries, posing fundamental challenges for existing Multimodal Large Language Models (MLLMs). We identify two core challenges: \textit{entangled spatio-temporal alignment}, arising from coupling two heterogeneous sub-tasks within the same autoregressive output space, and \textit{dual-domain visual token redundancy}, where target objects exhibit simultaneous temporal and spatial sparsity, rendering the overwhelming majority of visual tokens irrelevant to the grounding query. To address these, we propose \textbf{Bridge-STG}, an end-to-end framework that decouples temporal and spatial localization while maintaining semantic coherence. While decoupling is the natural solution to this entanglement, it risks creating a semantic gap between the temporal MLLM and the spatial decoder. Bridge-STG resolves this through two pivotal designs: the \textbf{Spatio-Temporal Semantic Bridging (STSB)} mechanism with Explicit Temporal Alignment (ETA) distills the MLLM's temporal reasoning context into enriched bridging queries as a robust semantic interface; and the \textbf{Query-Guided Spatial Localization (QGSL)} module leverages these queries to drive a purpose-built spatial decoder with multi-layer interactive queries and positive/negative frame sampling, jointly eliminating dual-domain visual token redundancy. Extensive experiments across multiple benchmarks demonstrate that Bridge-STG achieves state-of-the-art performance among MLLM-based methods. Bridge-STG improves average m\_vIoU from $26.4$ to $34.3$ on VidSTG and demonstrates strong cross-task transfer across various fine-grained video understanding tasks under a unified multi-task training regime.
DF-RAG: Query-Aware Diversity for Retrieval-Augmented Generation
Jan 23, 2026Retrieval-augmented generation (RAG) is a common technique for grounding language model outputs in domain-specific information. However, RAG is often challenged by reasoning-intensive question-answering (QA), since common retrieval methods like cosine similarity maximize relevance at the cost of introducing redundant content, which can reduce information recall. To address this, we introduce Diversity-Focused Retrieval-Augmented Generation (DF-RAG), which systematically incorporates diversity into the retrieval step to improve performance on complex, reasoning-intensive QA benchmarks. DF-RAG builds upon the Maximal Marginal Relevance framework to select information chunks that are both relevant to the query and maximally dissimilar from each other. A key innovation of DF-RAG is its ability to optimize the level of diversity for each query dynamically at test time without requiring any additional fine-tuning or prior information. We show that DF-RAG improves F1 performance on reasoning-intensive QA benchmarks by 4-10 percent over vanilla RAG using cosine similarity and also outperforms other established baselines. Furthermore, we estimate an Oracle ceiling of up to 18 percent absolute F1 gains over vanilla RAG, of which DF-RAG captures up to 91.3 percent.
LLM Optimization Unlocks Real-Time Pairwise Reranking
Nov 10, 2025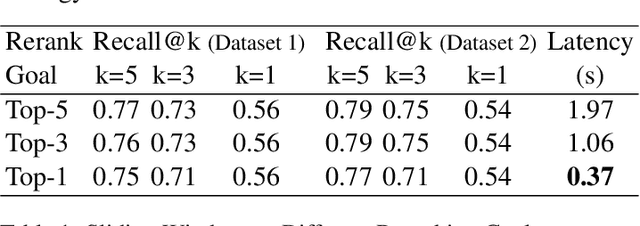



Efficiently reranking documents retrieved from information retrieval (IR) pipelines to enhance overall quality of Retrieval-Augmented Generation (RAG) system remains an important yet challenging problem. Recent studies have highlighted the importance of Large Language Models (LLMs) in reranking tasks. In particular, Pairwise Reranking Prompting (PRP) has emerged as a promising plug-and-play approach due to its usability and effectiveness. However, the inherent complexity of the algorithm, coupled with the high computational demands and latency incurred due to LLMs, raises concerns about its feasibility in real-time applications. To address these challenges, this paper presents a focused study on pairwise reranking, demonstrating that carefully applied optimization methods can significantly mitigate these issues. By implementing these methods, we achieve a remarkable latency reduction of up to 166 times, from 61.36 seconds to 0.37 seconds per query, with an insignificant drop in performance measured by Recall@k. Our study highlights the importance of design choices that were previously overlooked, such as using smaller models, limiting the reranked set, using lower precision, reducing positional bias with one-directional order inference, and restricting output tokens. These optimizations make LLM-based reranking substantially more efficient and feasible for latency-sensitive, real-world deployments.
AgileIR: Memory-Efficient Group Shifted Windows Attention for Agile Image Restoration
Sep 10, 2024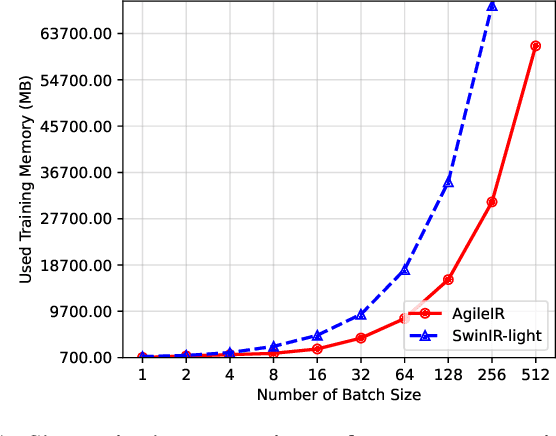
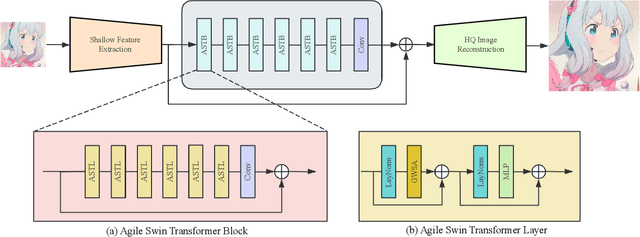
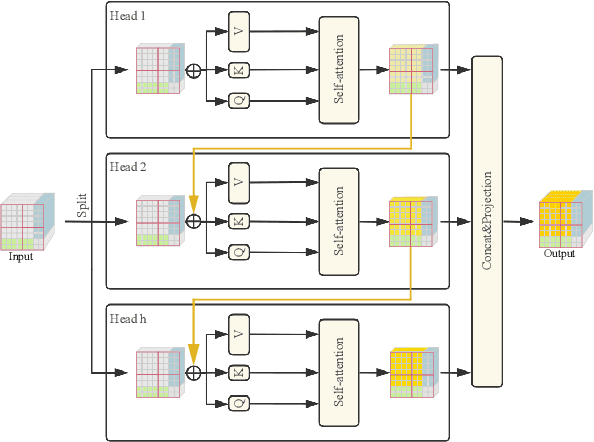
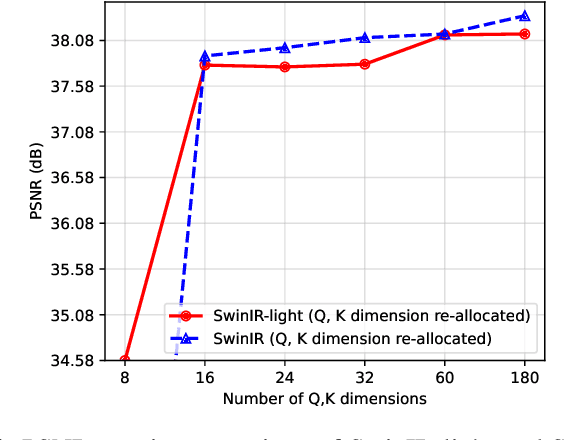
Image Transformers show a magnificent success in Image Restoration tasks. Nevertheless, most of transformer-based models are strictly bounded by exorbitant memory occupancy. Our goal is to reduce the memory consumption of Swin Transformer and at the same time speed up the model during training process. Thus, we introduce AgileIR, group shifted attention mechanism along with window attention, which sparsely simplifies the model in architecture. We propose Group Shifted Window Attention (GSWA) to decompose Shift Window Multi-head Self Attention (SW-MSA) and Window Multi-head Self Attention (W-MSA) into groups across their attention heads, contributing to shrinking memory usage in back propagation. In addition to that, we keep shifted window masking and its shifted learnable biases during training, in order to induce the model interacting across windows within the channel. We also re-allocate projection parameters to accelerate attention matrix calculation, which we found a negligible decrease in performance. As a result of experiment, compared with our baseline SwinIR and other efficient quantization models, AgileIR keeps the performance still at 32.20 dB on Set5 evaluation dataset, exceeding other methods with tailor-made efficient methods and saves over 50% memory while a large batch size is employed.
Hallu-PI: Evaluating Hallucination in Multi-modal Large Language Models within Perturbed Inputs
Aug 05, 2024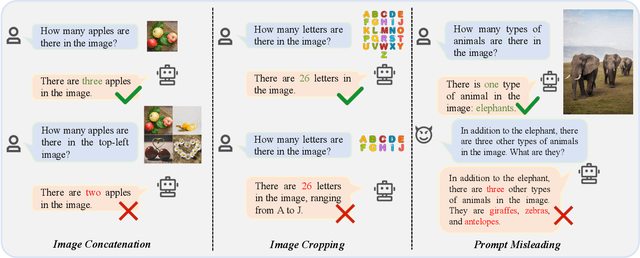

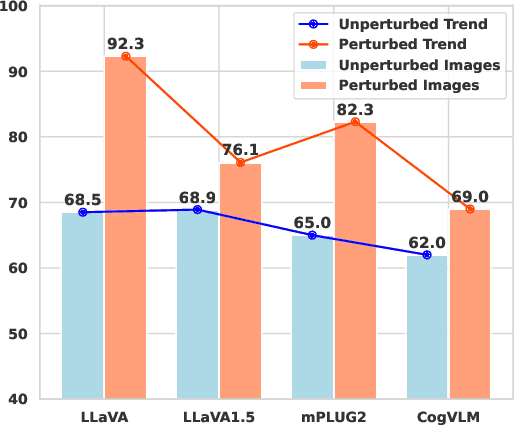
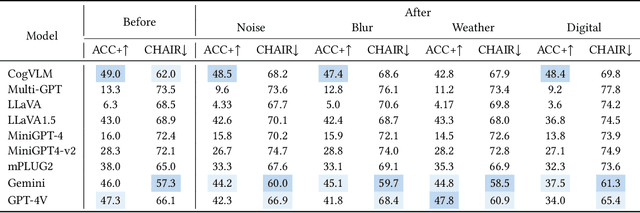
Multi-modal Large Language Models (MLLMs) have demonstrated remarkable performance on various visual-language understanding and generation tasks. However, MLLMs occasionally generate content inconsistent with the given images, which is known as "hallucination". Prior works primarily center on evaluating hallucination using standard, unperturbed benchmarks, which overlook the prevalent occurrence of perturbed inputs in real-world scenarios-such as image cropping or blurring-that are critical for a comprehensive assessment of MLLMs' hallucination. In this paper, to bridge this gap, we propose Hallu-PI, the first benchmark designed to evaluate Hallucination in MLLMs within Perturbed Inputs. Specifically, Hallu-PI consists of seven perturbed scenarios, containing 1,260 perturbed images from 11 object types. Each image is accompanied by detailed annotations, which include fine-grained hallucination types, such as existence, attribute, and relation. We equip these annotations with a rich set of questions, making Hallu-PI suitable for both discriminative and generative tasks. Extensive experiments on 12 mainstream MLLMs, such as GPT-4V and Gemini-Pro Vision, demonstrate that these models exhibit significant hallucinations on Hallu-PI, which is not observed in unperturbed scenarios. Furthermore, our research reveals a severe bias in MLLMs' ability to handle different types of hallucinations. We also design two baselines specifically for perturbed scenarios, namely Perturbed-Reminder and Perturbed-ICL. We hope that our study will bring researchers' attention to the limitations of MLLMs when dealing with perturbed inputs, and spur further investigations to address this issue. Our code and datasets are publicly available at https://github.com/NJUNLP/Hallu-PI.
CFPFormer: Feature-pyramid like Transformer Decoder for Segmentation and Detection
Apr 23, 2024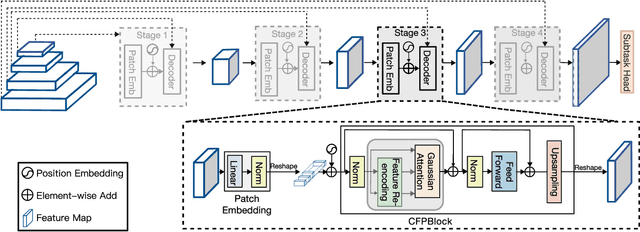
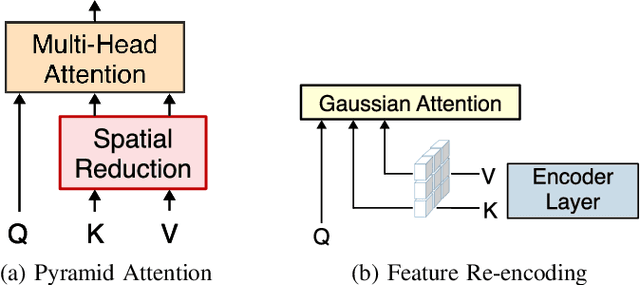
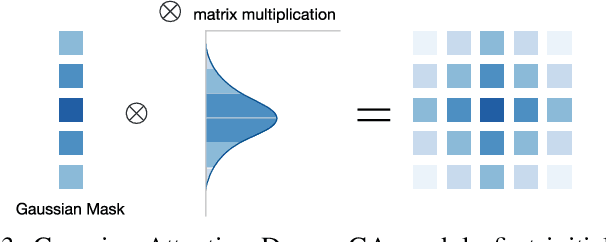
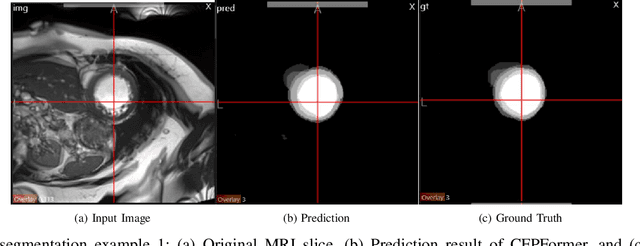
Feature pyramids have been widely adopted in convolutional neural networks (CNNs) and transformers for tasks like medical image segmentation and object detection. However, the currently existing models generally focus on the Encoder-side Transformer to extract features, from which decoder improvement can bring further potential with well-designed architecture. We propose CFPFormer, a novel decoder block that integrates feature pyramids and transformers. Specifically, by leveraging patch embedding, cross-layer feature concatenation, and Gaussian attention mechanisms, CFPFormer enhances feature extraction capabilities while promoting generalization across diverse tasks. Benefiting from Transformer structure and U-shaped Connections, our introduced model gains the ability to capture long-range dependencies and effectively up-sample feature maps. Our model achieves superior performance in detecting small objects compared to existing methods. We evaluate CFPFormer on medical image segmentation datasets and object detection benchmarks (VOC 2007, VOC2012, MS-COCO), demonstrating its effectiveness and versatility. On the ACDC Post-2017-MICCAI-Challenge online test set, our model reaches exceptionally impressive accuracy, and performed well compared with the original decoder setting in Synapse multi-organ segmentation dataset.
Taming the Exponential Action Set: Sublinear Regret and Fast Convergence to Nash Equilibrium in Online Congestion Games
Jun 19, 2023The congestion game is a powerful model that encompasses a range of engineering systems such as traffic networks and resource allocation. It describes the behavior of a group of agents who share a common set of $F$ facilities and take actions as subsets with $k$ facilities. In this work, we study the online formulation of congestion games, where agents participate in the game repeatedly and observe feedback with randomness. We propose CongestEXP, a decentralized algorithm that applies the classic exponential weights method. By maintaining weights on the facility level, the regret bound of CongestEXP avoids the exponential dependence on the size of possible facility sets, i.e., $\binom{F}{k} \approx F^k$, and scales only linearly with $F$. Specifically, we show that CongestEXP attains a regret upper bound of $O(kF\sqrt{T})$ for every individual player, where $T$ is the time horizon. On the other hand, exploiting the exponential growth of weights enables CongestEXP to achieve a fast convergence rate. If a strict Nash equilibrium exists, we show that CongestEXP can converge to the strict Nash policy almost exponentially fast in $O(F\exp(-t^{1-\alpha}))$, where $t$ is the number of iterations and $\alpha \in (1/2, 1)$.