 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCFPFormer: Feature-pyramid like Transformer Decoder for Segmentation and Detection
Apr 23, 2024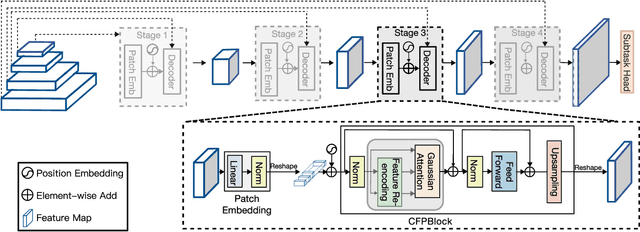
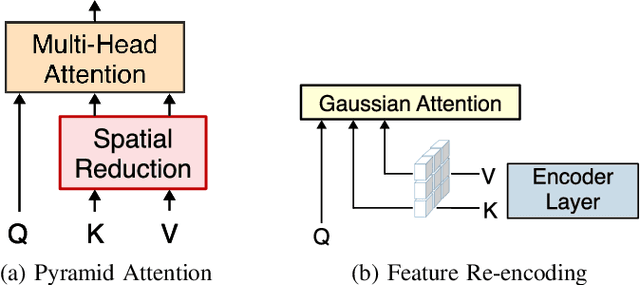
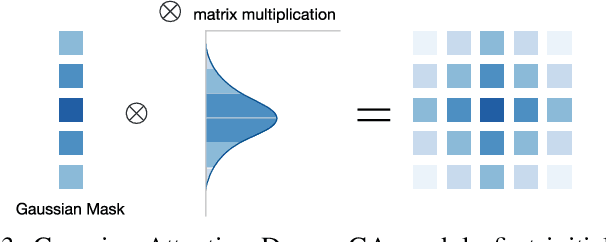
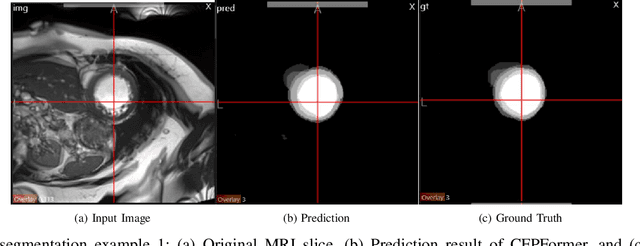
Feature pyramids have been widely adopted in convolutional neural networks (CNNs) and transformers for tasks like medical image segmentation and object detection. However, the currently existing models generally focus on the Encoder-side Transformer to extract features, from which decoder improvement can bring further potential with well-designed architecture. We propose CFPFormer, a novel decoder block that integrates feature pyramids and transformers. Specifically, by leveraging patch embedding, cross-layer feature concatenation, and Gaussian attention mechanisms, CFPFormer enhances feature extraction capabilities while promoting generalization across diverse tasks. Benefiting from Transformer structure and U-shaped Connections, our introduced model gains the ability to capture long-range dependencies and effectively up-sample feature maps. Our model achieves superior performance in detecting small objects compared to existing methods. We evaluate CFPFormer on medical image segmentation datasets and object detection benchmarks (VOC 2007, VOC2012, MS-COCO), demonstrating its effectiveness and versatility. On the ACDC Post-2017-MICCAI-Challenge online test set, our model reaches exceptionally impressive accuracy, and performed well compared with the original decoder setting in Synapse multi-organ segmentation dataset.