 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFRAbench and GenEval: Scaling Fine-Grained Aspect Evaluation across Tasks, Modalities
May 19, 2025Evaluating the open-ended outputs of large language models (LLMs) has become a bottleneck as model capabilities, task diversity, and modality coverage rapidly expand. Existing "LLM-as-a-Judge" evaluators are typically narrow in a few tasks, aspects, or modalities, and easily suffer from low consistency. In this paper, we argue that explicit, fine-grained aspect specification is the key to both generalizability and objectivity in automated evaluation. To do so, we introduce a hierarchical aspect taxonomy spanning 112 aspects that unifies evaluation across four representative settings - Natural Language Generation, Image Understanding, Image Generation, and Interleaved Text-and-Image Generation. Building on this taxonomy, we create FRAbench, a benchmark comprising 60.4k pairwise samples with 325k aspect-level labels obtained from a combination of human and LLM annotations. FRAbench provides the first large-scale, multi-modal resource for training and meta-evaluating fine-grained LMM judges. Leveraging FRAbench, we develop GenEval, a fine-grained evaluator generalizable across tasks and modalities. Experiments show that GenEval (i) attains high agreement with GPT-4o and expert annotators, (ii) transfers robustly to unseen tasks and modalities, and (iii) reveals systematic weaknesses of current LMMs on evaluation.
Why Not Act on What You Know? Unleashing Safety Potential of LLMs via Self-Aware Guard Enhancement
May 17, 2025Large Language Models (LLMs) have shown impressive capabilities across various tasks but remain vulnerable to meticulously crafted jailbreak attacks. In this paper, we identify a critical safety gap: while LLMs are adept at detecting jailbreak prompts, they often produce unsafe responses when directly processing these inputs. Inspired by this insight, we propose SAGE (Self-Aware Guard Enhancement), a training-free defense strategy designed to align LLMs' strong safety discrimination performance with their relatively weaker safety generation ability. SAGE consists of two core components: a Discriminative Analysis Module and a Discriminative Response Module, enhancing resilience against sophisticated jailbreak attempts through flexible safety discrimination instructions. Extensive experiments demonstrate SAGE's effectiveness and robustness across various open-source and closed-source LLMs of different sizes and architectures, achieving an average 99% defense success rate against numerous complex and covert jailbreak methods while maintaining helpfulness on general benchmarks. We further conduct mechanistic interpretability analysis through hidden states and attention distributions, revealing the underlying mechanisms of this detection-generation discrepancy. Our work thus contributes to developing future LLMs with coherent safety awareness and generation behavior. Our code and datasets are publicly available at https://github.com/NJUNLP/SAGE.
Hallu-PI: Evaluating Hallucination in Multi-modal Large Language Models within Perturbed Inputs
Aug 05, 2024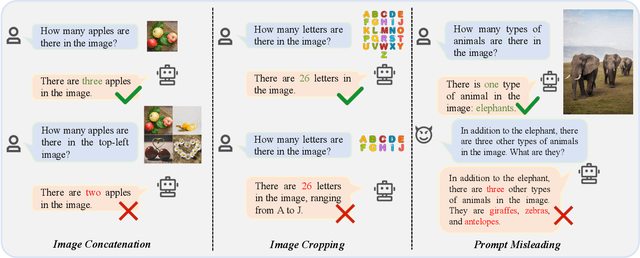

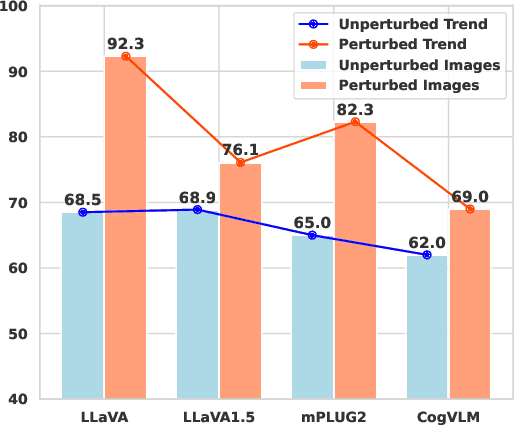
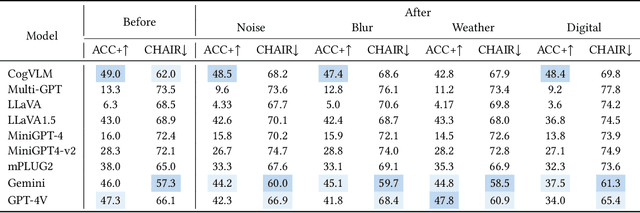
Multi-modal Large Language Models (MLLMs) have demonstrated remarkable performance on various visual-language understanding and generation tasks. However, MLLMs occasionally generate content inconsistent with the given images, which is known as "hallucination". Prior works primarily center on evaluating hallucination using standard, unperturbed benchmarks, which overlook the prevalent occurrence of perturbed inputs in real-world scenarios-such as image cropping or blurring-that are critical for a comprehensive assessment of MLLMs' hallucination. In this paper, to bridge this gap, we propose Hallu-PI, the first benchmark designed to evaluate Hallucination in MLLMs within Perturbed Inputs. Specifically, Hallu-PI consists of seven perturbed scenarios, containing 1,260 perturbed images from 11 object types. Each image is accompanied by detailed annotations, which include fine-grained hallucination types, such as existence, attribute, and relation. We equip these annotations with a rich set of questions, making Hallu-PI suitable for both discriminative and generative tasks. Extensive experiments on 12 mainstream MLLMs, such as GPT-4V and Gemini-Pro Vision, demonstrate that these models exhibit significant hallucinations on Hallu-PI, which is not observed in unperturbed scenarios. Furthermore, our research reveals a severe bias in MLLMs' ability to handle different types of hallucinations. We also design two baselines specifically for perturbed scenarios, namely Perturbed-Reminder and Perturbed-ICL. We hope that our study will bring researchers' attention to the limitations of MLLMs when dealing with perturbed inputs, and spur further investigations to address this issue. Our code and datasets are publicly available at https://github.com/NJUNLP/Hallu-PI.
A Wolf in Sheep's Clothing: Generalized Nested Jailbreak Prompts can Fool Large Language Models Easily
Nov 14, 2023Large Language Models (LLMs), such as ChatGPT and GPT-4, are designed to provide useful and safe responses. However, adversarial prompts known as 'jailbreaks' can circumvent safeguards, leading LLMs to generate harmful content. Exploring jailbreak prompts can help to better reveal the weaknesses of LLMs and further steer us to secure them. Unfortunately, existing jailbreak methods either suffer from intricate manual design or require optimization on another white-box model, compromising generalization or jailbreak efficiency. In this paper, we generalize jailbreak prompt attacks into two aspects: (1) Prompt Rewriting and (2) Scenario Nesting. Based on this, we propose ReNeLLM, an automatic framework that leverages LLMs themselves to generate effective jailbreak prompts. Extensive experiments demonstrate that ReNeLLM significantly improves the attack success rate while greatly reducing the time cost compared to existing baselines. Our study also reveals the inadequacy of current defense methods in safeguarding LLMs. Finally, we offer detailed analysis and discussion from the perspective of prompt execution priority on the failure of LLMs' defense. We hope that our research can catalyze both the academic community and LLMs vendors towards the provision of safer and more regulated Large Language Models.
Meta-Learning Triplet Network with Adaptive Margins for Few-Shot Named Entity Recognition
Feb 14, 2023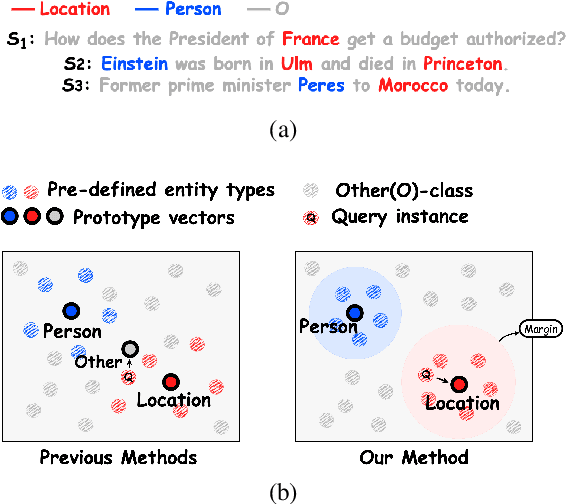



Meta-learning methods have been widely used in few-shot named entity recognition (NER), especially prototype-based methods. However, the Other(O) class is difficult to be represented by a prototype vector because there are generally a large number of samples in the class that have miscellaneous semantics. To solve the problem, we propose MeTNet, which generates prototype vectors for entity types only but not O-class. We design an improved triplet network to map samples and prototype vectors into a low-dimensional space that is easier to be classified and propose an adaptive margin for each entity type. The margin plays as a radius and controls a region with adaptive size in the low-dimensional space. Based on the regions, we propose a new inference procedure to predict the label of a query instance. We conduct extensive experiments in both in-domain and cross-domain settings to show the superiority of MeTNet over other state-of-the-art methods. In particular, we release a Chinese few-shot NER dataset FEW-COMM extracted from a well-known e-commerce platform. To the best of our knowledge, this is the first Chinese few-shot NER dataset. All the datasets and codes are provided at https://github.com/hccngu/MeTNet.
Learning Relation Prototype from Unlabeled Texts for Long-tail Relation Extraction
Nov 27, 2020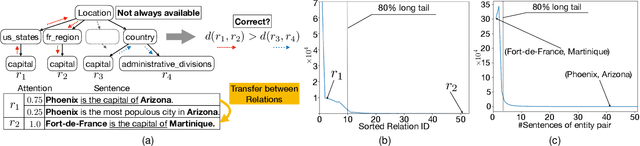
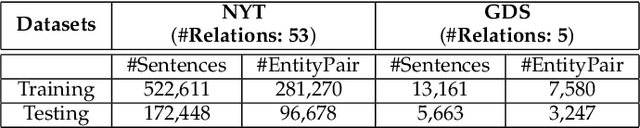
Relation Extraction (RE) is a vital step to complete Knowledge Graph (KG) by extracting entity relations from texts.However, it usually suffers from the long-tail issue. The training data mainly concentrates on a few types of relations, leading to the lackof sufficient annotations for the remaining types of relations. In this paper, we propose a general approach to learn relation prototypesfrom unlabeled texts, to facilitate the long-tail relation extraction by transferring knowledge from the relation types with sufficient trainingdata. We learn relation prototypes as an implicit factor between entities, which reflects the meanings of relations as well as theirproximities for transfer learning. Specifically, we construct a co-occurrence graph from texts, and capture both first-order andsecond-order entity proximities for embedding learning. Based on this, we further optimize the distance from entity pairs tocorresponding prototypes, which can be easily adapted to almost arbitrary RE frameworks. Thus, the learning of infrequent or evenunseen relation types will benefit from semantically proximate relations through pairs of entities and large-scale textual information.We have conducted extensive experiments on two publicly available datasets: New York Times and Google Distant Supervision.Compared with eight state-of-the-art baselines, our proposed model achieves significant improvements (4.1% F1 on average). Furtherresults on long-tail relations demonstrate the effectiveness of the learned relation prototypes. We further conduct an ablation study toinvestigate the impacts of varying components, and apply it to four basic relation extraction models to verify the generalization ability.Finally, we analyze several example cases to give intuitive impressions as qualitative analysis. Our codes will be released later.
Improving Neural Relation Extraction with Implicit Mutual Relations
Jul 08, 2019
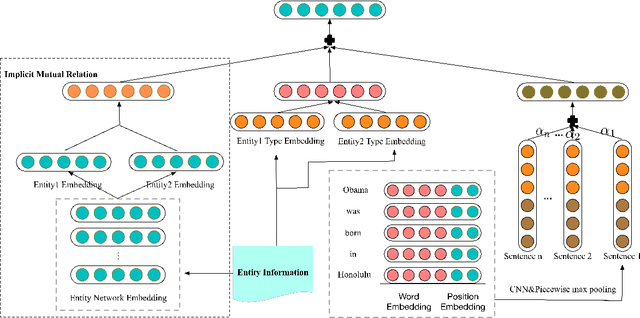
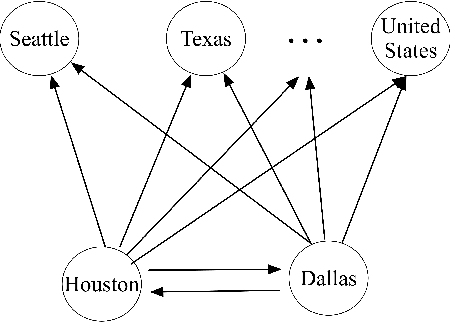

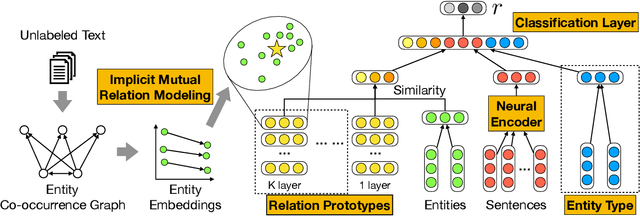
Relation extraction (RE) aims at extracting the relation between two entities from the text corpora. It is a crucial task for Knowledge Graph (KG) construction. Most existing methods predict the relation between an entity pair by learning the relation from the training sentences, which contain the targeted entity pair. In contrast to existing distant supervision approaches that suffer from insufficient training corpora to extract relations, our proposal of mining implicit mutual relation from the massive unlabeled corpora transfers the semantic information of entity pairs into the RE model, which is more expressive and semantically plausible. After constructing an entity proximity graph based on the implicit mutual relations, we preserve the semantic relations of entity pairs via embedding each vertex of the graph into a low-dimensional space. As a result, we can easily and flexibly integrate the implicit mutual relations and other entity information, such as entity types, into the existing RE methods. Our experimental results on a New York Times and another Google Distant Supervision datasets suggest that our proposed neural RE framework provides a promising improvement for the RE task, and significantly outperforms the state-of-the-art methods. Moreover, the component for mining implicit mutual relations is so flexible that can help to improve the performance of both CNN-based and RNN-based RE models significant.