 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongCat-Flash-Thinking-2601 Technical Report
Jan 23, 2026We introduce LongCat-Flash-Thinking-2601, a 560-billion-parameter open-source Mixture-of-Experts (MoE) reasoning model with superior agentic reasoning capability. LongCat-Flash-Thinking-2601 achieves state-of-the-art performance among open-source models on a wide range of agentic benchmarks, including agentic search, agentic tool use, and tool-integrated reasoning. Beyond benchmark performance, the model demonstrates strong generalization to complex tool interactions and robust behavior under noisy real-world environments. Its advanced capability stems from a unified training framework that combines domain-parallel expert training with subsequent fusion, together with an end-to-end co-design of data construction, environments, algorithms, and infrastructure spanning from pre-training to post-training. In particular, the model's strong generalization capability in complex tool-use are driven by our in-depth exploration of environment scaling and principled task construction. To optimize long-tailed, skewed generation and multi-turn agentic interactions, and to enable stable training across over 10,000 environments spanning more than 20 domains, we systematically extend our asynchronous reinforcement learning framework, DORA, for stable and efficient large-scale multi-environment training. Furthermore, recognizing that real-world tasks are inherently noisy, we conduct a systematic analysis and decomposition of real-world noise patterns, and design targeted training procedures to explicitly incorporate such imperfections into the training process, resulting in improved robustness for real-world applications. To further enhance performance on complex reasoning tasks, we introduce a Heavy Thinking mode that enables effective test-time scaling by jointly expanding reasoning depth and width through intensive parallel thinking.
VitaBench: Benchmarking LLM Agents with Versatile Interactive Tasks in Real-world Applications
Sep 30, 2025As LLM-based agents are increasingly deployed in real-life scenarios, existing benchmarks fail to capture their inherent complexity of handling extensive information, leveraging diverse resources, and managing dynamic user interactions. To address this gap, we introduce VitaBench, a challenging benchmark that evaluates agents on versatile interactive tasks grounded in real-world settings. Drawing from daily applications in food delivery, in-store consumption, and online travel services, VitaBench presents agents with the most complex life-serving simulation environment to date, comprising 66 tools. Through a framework that eliminates domain-specific policies, we enable flexible composition of these scenarios and tools, yielding 100 cross-scenario tasks (main results) and 300 single-scenario tasks. Each task is derived from multiple real user requests and requires agents to reason across temporal and spatial dimensions, utilize complex tool sets, proactively clarify ambiguous instructions, and track shifting user intent throughout multi-turn conversations. Moreover, we propose a rubric-based sliding window evaluator, enabling robust assessment of diverse solution pathways in complex environments and stochastic interactions. Our comprehensive evaluation reveals that even the most advanced models achieve only 30% success rate on cross-scenario tasks, and less than 50% success rate on others. Overall, we believe VitaBench will serve as a valuable resource for advancing the development of AI agents in practical real-world applications. The code, dataset, and leaderboard are available at https://vitabench.github.io/
MUSE: MCTS-Driven Red Teaming Framework for Enhanced Multi-Turn Dialogue Safety in Large Language Models
Sep 18, 2025As large language models~(LLMs) become widely adopted, ensuring their alignment with human values is crucial to prevent jailbreaks where adversaries manipulate models to produce harmful content. While most defenses target single-turn attacks, real-world usage often involves multi-turn dialogues, exposing models to attacks that exploit conversational context to bypass safety measures. We introduce MUSE, a comprehensive framework tackling multi-turn jailbreaks from both attack and defense angles. For attacks, we propose MUSE-A, a method that uses frame semantics and heuristic tree search to explore diverse semantic trajectories. For defense, we present MUSE-D, a fine-grained safety alignment approach that intervenes early in dialogues to reduce vulnerabilities. Extensive experiments on various models show that MUSE effectively identifies and mitigates multi-turn vulnerabilities. Code is available at \href{https://github.com/yansiyu02/MUSE}{https://github.com/yansiyu02/MUSE}.
MARS2 2025 Challenge on Multimodal Reasoning: Datasets, Methods, Results, Discussion, and Outlook
Sep 17, 2025



This paper reviews the MARS2 2025 Challenge on Multimodal Reasoning. We aim to bring together different approaches in multimodal machine learning and LLMs via a large benchmark. We hope it better allows researchers to follow the state-of-the-art in this very dynamic area. Meanwhile, a growing number of testbeds have boosted the evolution of general-purpose large language models. Thus, this year's MARS2 focuses on real-world and specialized scenarios to broaden the multimodal reasoning applications of MLLMs. Our organizing team released two tailored datasets Lens and AdsQA as test sets, which support general reasoning in 12 daily scenarios and domain-specific reasoning in advertisement videos, respectively. We evaluated 40+ baselines that include both generalist MLLMs and task-specific models, and opened up three competition tracks, i.e., Visual Grounding in Real-world Scenarios (VG-RS), Visual Question Answering with Spatial Awareness (VQA-SA), and Visual Reasoning in Creative Advertisement Videos (VR-Ads). Finally, 76 teams from the renowned academic and industrial institutions have registered and 40+ valid submissions (out of 1200+) have been included in our ranking lists. Our datasets, code sets (40+ baselines and 15+ participants' methods), and rankings are publicly available on the MARS2 workshop website and our GitHub organization page https://github.com/mars2workshop/, where our updates and announcements of upcoming events will be continuously provided.
RMoA: Optimizing Mixture-of-Agents through Diversity Maximization and Residual Compensation
May 30, 2025Although multi-agent systems based on large language models show strong capabilities on multiple tasks, they are still limited by high computational overhead, information loss, and robustness. Inspired by ResNet's residual learning, we propose Residual Mixture-of-Agents (RMoA), integrating residual connections to optimize efficiency and reliability. To maximize information utilization from model responses while minimizing computational costs, we innovatively design an embedding-based diversity selection mechanism that greedily selects responses via vector similarity. Furthermore, to mitigate iterative information degradation, we introduce a Residual Extraction Agent to preserve cross-layer incremental information by capturing inter-layer response differences, coupled with a Residual Aggregation Agent for hierarchical information integration. Additionally, we propose an adaptive termination mechanism that dynamically halts processing based on residual convergence, further improving inference efficiency. RMoA achieves state-of-the-art performance on the benchmarks of across alignment, mathematical reasoning, code generation, and multitasking understanding, while significantly reducing computational overhead. Code is available at https://github.com/mindhunter01/RMoA.
Length Desensitization in Directed Preference Optimization
Sep 10, 2024
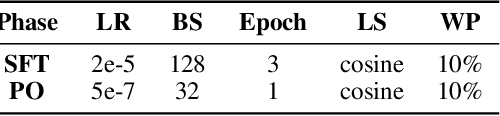

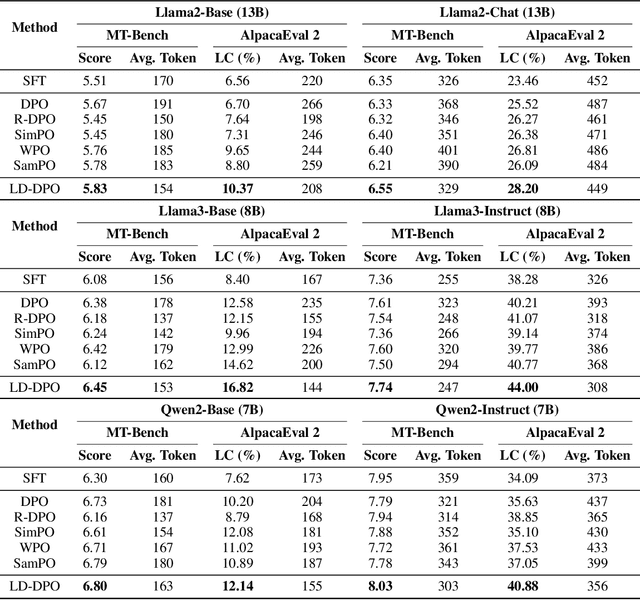
Direct Preference Optimization (DPO) is widely utilized in the Reinforcement Learning from Human Feedback (RLHF) phase to align Large Language Models (LLMs) with human preferences, thereby enhancing both their harmlessness and efficacy. However, it has been observed that DPO tends to over-optimize for verbosity, which can detrimentally affect both performance and user experience. In this paper, we conduct an in-depth theoretical analysis of DPO's optimization objective and reveal a strong correlation between its implicit reward and data length. This correlation misguides the optimization direction, resulting in length sensitivity during the DPO training and leading to verbosity. To address this issue, we propose a length-desensitization improvement method for DPO, termed LD-DPO. The proposed method aims to desensitize DPO to data length by decoupling explicit length preference, which is relatively insignificant, from the other implicit preferences, thereby enabling more effective learning of the intrinsic preferences. We utilized two settings (Base and Instruct) of Llama2-13B, Llama3-8B, and Qwen2-7B for experimental validation on various benchmarks including MT-Bench and AlpacaEval 2. The experimental results indicate that LD-DPO consistently outperforms DPO and other baseline methods, achieving more concise responses with a 10-40\% reduction in length compared to DPO. We conducted in-depth experimental analyses to demonstrate that LD-DPO can indeed achieve length desensitization and align the model more closely with human-real preferences.
A Survey of Neural Code Intelligence: Paradigms, Advances and Beyond
Mar 21, 2024Neural Code Intelligence -- leveraging deep learning to understand, generate, and optimize code -- holds immense potential for transformative impacts on the whole society. Bridging the gap between Natural Language and Programming Language, this domain has drawn significant attention from researchers in both research communities over the past few years. This survey presents a systematic and chronological review of the advancements in code intelligence, encompassing over 50 representative models and their variants, more than 20 categories of tasks, and an extensive coverage of over 680 related works. We follow the historical progression to trace the paradigm shifts across different research phases (e.g., from modeling code with recurrent neural networks to the era of Large Language Models). Concurrently, we highlight the major technical transitions in models, tasks, and evaluations spanning through different stages. For applications, we also observe a co-evolving shift. It spans from initial endeavors to tackling specific scenarios, through exploring a diverse array of tasks during its rapid expansion, to currently focusing on tackling increasingly complex and varied real-world challenges. Building on our examination of the developmental trajectories, we further investigate the emerging synergies between code intelligence and broader machine intelligence, uncovering new cross-domain opportunities and illustrating the substantial influence of code intelligence across various domains. Finally, we delve into both the opportunities and challenges associated with this field, alongside elucidating our insights on the most promising research directions. An ongoing, dynamically updated project and resources associated with this survey have been released at https://github.com/QiushiSun/NCISurvey.
Learning to Check: Unleashing Potentials for Self-Correction in Large Language Models
Feb 23, 2024



Large language models (LLMs) have made significant strides in reasoning capabilities, with ongoing efforts to refine their reasoning through self-correction. However, recent studies suggest that self-correction can be limited or even counterproductive without external accurate knowledge, raising questions about the limits and effectiveness of self-correction. In this paper, we aim to enhance LLM's self-checking capabilities by meticulously designing training data, thereby improving the accuracy of self-correction. We conduct a detailed analysis of error types in mathematical reasoning and develop a tailored prompt, termed "Step CoT Check". Then we construct a checking-correction dataset for training models. After integrating the original CoT data and checking-correction data for training, we observe that models could improve their self-checking capabilities, thereby enhancing their self-correction capacity and eliminating the need for external feedback or ground truth labels to ascertain the endpoint of correction. We compare the performance of models fine-tuned with the "Step CoT Check" prompt against those refined using other promps within the context of checking-correction data. The "Step CoT Check" outperforms the other two check formats in model with lager parameters, providing more precise feedback thus achieving a higher rate of correctness. For reproducibility, all the datasets and codes are provided in https://github.com/bammt/Learn-to-check.
OS-Copilot: Towards Generalist Computer Agents with Self-Improvement
Feb 15, 2024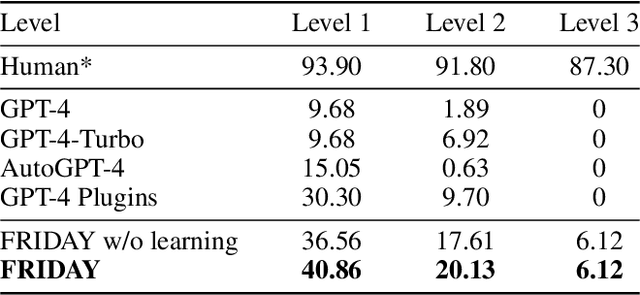
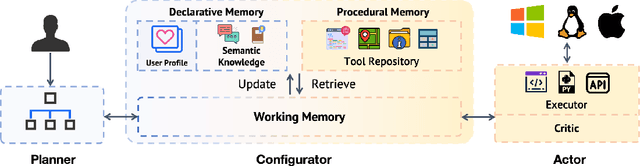

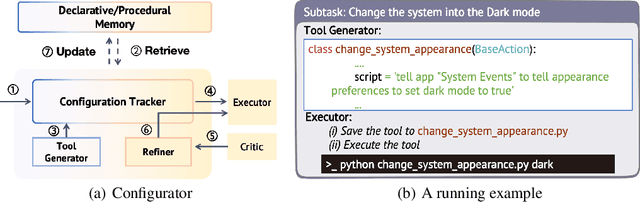
Autonomous interaction with the computer has been a longstanding challenge with great potential, and the recent proliferation of large language models (LLMs) has markedly accelerated progress in building digital agents. However, most of these agents are designed to interact with a narrow domain, such as a specific software or website. This narrow focus constrains their applicability for general computer tasks. To this end, we introduce OS-Copilot, a framework to build generalist agents capable of interfacing with comprehensive elements in an operating system (OS), including the web, code terminals, files, multimedia, and various third-party applications. We use OS-Copilot to create FRIDAY, a self-improving embodied agent for automating general computer tasks. On GAIA, a general AI assistants benchmark, FRIDAY outperforms previous methods by 35%, showcasing strong generalization to unseen applications via accumulated skills from previous tasks. We also present numerical and quantitative evidence that FRIDAY learns to control and self-improve on Excel and Powerpoint with minimal supervision. Our OS-Copilot framework and empirical findings provide infrastructure and insights for future research toward more capable and general-purpose computer agents.
DialCoT Meets PPO: Decomposing and Exploring Reasoning Paths in Smaller Language Models
Oct 23, 2023Chain-of-Thought (CoT) prompting has proven to be effective in enhancing the reasoning capabilities of Large Language Models (LLMs) with at least 100 billion parameters. However, it is ineffective or even detrimental when applied to reasoning tasks in Smaller Language Models (SLMs) with less than 10 billion parameters. To address this limitation, we introduce Dialogue-guided Chain-of-Thought (DialCoT) which employs a dialogue format to generate intermediate reasoning steps, guiding the model toward the final answer. Additionally, we optimize the model's reasoning path selection using the Proximal Policy Optimization (PPO) algorithm, further enhancing its reasoning capabilities. Our method offers several advantages compared to previous approaches. Firstly, we transform the process of solving complex reasoning questions by breaking them down into a series of simpler sub-questions, significantly reducing the task difficulty and making it more suitable for SLMs. Secondly, we optimize the model's reasoning path selection through the PPO algorithm. We conduct comprehensive experiments on four arithmetic reasoning datasets, demonstrating that our method achieves significant performance improvements compared to state-of-the-art competitors.