 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLength Desensitization in Directed Preference Optimization
Paper and Code


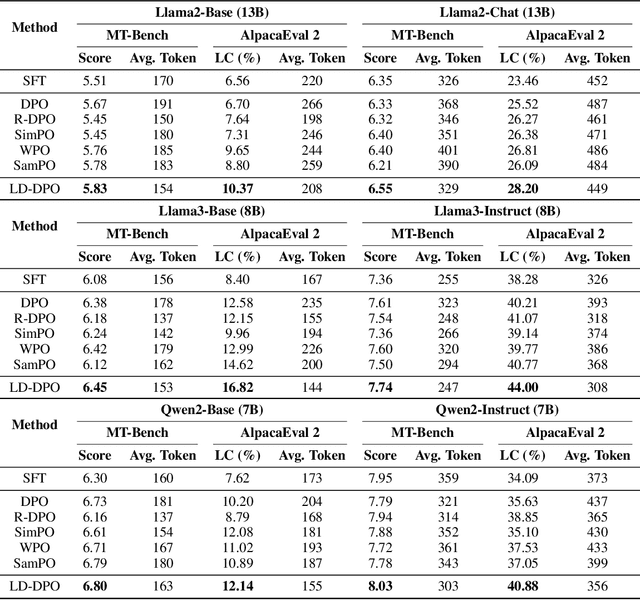
Direct Preference Optimization (DPO) is widely utilized in the Reinforcement Learning from Human Feedback (RLHF) phase to align Large Language Models (LLMs) with human preferences, thereby enhancing both their harmlessness and efficacy. However, it has been observed that DPO tends to over-optimize for verbosity, which can detrimentally affect both performance and user experience. In this paper, we conduct an in-depth theoretical analysis of DPO's optimization objective and reveal a strong correlation between its implicit reward and data length. This correlation misguides the optimization direction, resulting in length sensitivity during the DPO training and leading to verbosity. To address this issue, we propose a length-desensitization improvement method for DPO, termed LD-DPO. The proposed method aims to desensitize DPO to data length by decoupling explicit length preference, which is relatively insignificant, from the other implicit preferences, thereby enabling more effective learning of the intrinsic preferences. We utilized two settings (Base and Instruct) of Llama2-13B, Llama3-8B, and Qwen2-7B for experimental validation on various benchmarks including MT-Bench and AlpacaEval 2. The experimental results indicate that LD-DPO consistently outperforms DPO and other baseline methods, achieving more concise responses with a 10-40\% reduction in length compared to DPO. We conducted in-depth experimental analyses to demonstrate that LD-DPO can indeed achieve length desensitization and align the model more closely with human-real preferences.