 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExchanging-based Multimodal Fusion with Transformer
Sep 05, 2023



We study the problem of multimodal fusion in this paper. Recent exchanging-based methods have been proposed for vision-vision fusion, which aim to exchange embeddings learned from one modality to the other. However, most of them project inputs of multimodalities into different low-dimensional spaces and cannot be applied to the sequential input data. To solve these issues, in this paper, we propose a novel exchanging-based multimodal fusion model MuSE for text-vision fusion based on Transformer. We first use two encoders to separately map multimodal inputs into different low-dimensional spaces. Then we employ two decoders to regularize the embeddings and pull them into the same space. The two decoders capture the correlations between texts and images with the image captioning task and the text-to-image generation task, respectively. Further, based on the regularized embeddings, we present CrossTransformer, which uses two Transformer encoders with shared parameters as the backbone model to exchange knowledge between multimodalities. Specifically, CrossTransformer first learns the global contextual information of the inputs in the shallow layers. After that, it performs inter-modal exchange by selecting a proportion of tokens in one modality and replacing their embeddings with the average of embeddings in the other modality. We conduct extensive experiments to evaluate the performance of MuSE on the Multimodal Named Entity Recognition task and the Multimodal Sentiment Analysis task. Our results show the superiority of MuSE against other competitors. Our code and data are provided at https://github.com/RecklessRonan/MuSE.
SGPT: Semantic Graphs based Pre-training for Aspect-based Sentiment Analysis
May 26, 2021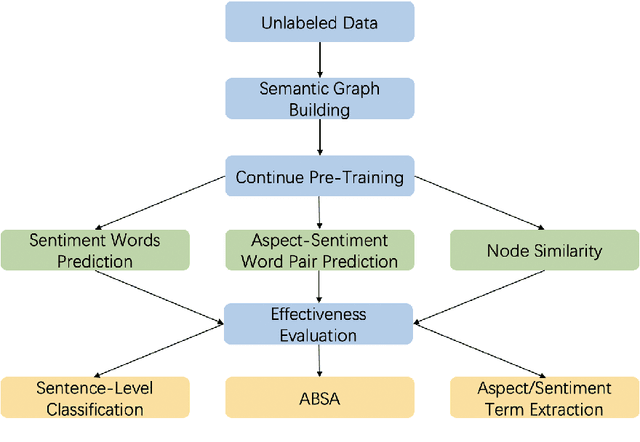
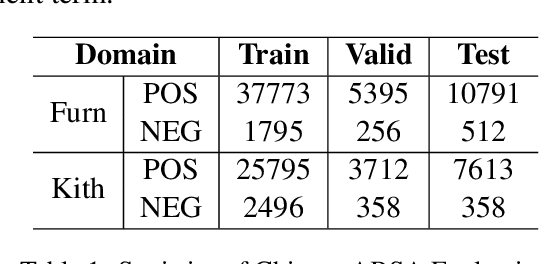
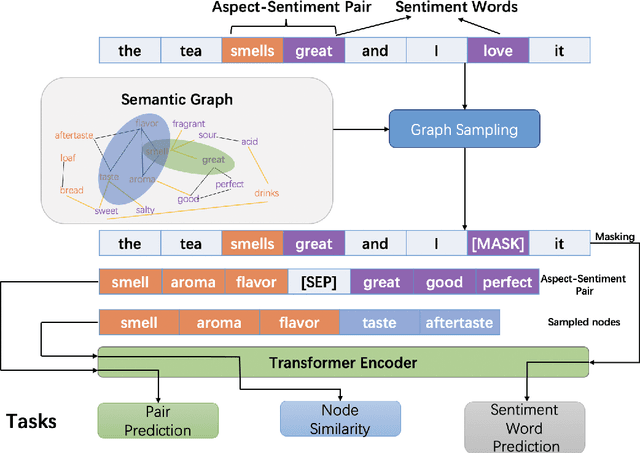
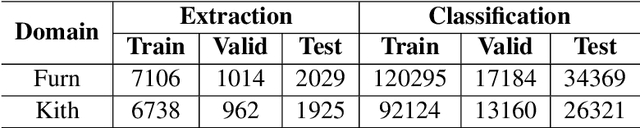
Previous studies show effective of pre-trained language models for sentiment analysis. However, most of these studies ignore the importance of sentimental information for pre-trained models.Therefore, we fully investigate the sentimental information for pre-trained models and enhance pre-trained language models with semantic graphs for sentiment analysis.In particular, we introduce Semantic Graphs based Pre-training(SGPT) using semantic graphs to obtain synonym knowledge for aspect-sentiment pairs and similar aspect/sentiment terms.We then optimize the pre-trained language model with the semantic graphs.Empirical studies on several downstream tasks show that proposed model outperforms strong pre-trained baselines. The results also show the effectiveness of proposed semantic graphs for pre-trained model.