 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStablePDENet: Enhancing Stability of Operator Learning for Solving Differential Equations
Jan 10, 2026Learning solution operators for differential equations with neural networks has shown great potential in scientific computing, but ensuring their stability under input perturbations remains a critical challenge. This paper presents a robust self-supervised neural operator framework that enhances stability through adversarial training while preserving accuracy. We formulate operator learning as a min-max optimization problem, where the model is trained against worst-case input perturbations to achieve consistent performance under both normal and adversarial conditions. We demonstrate that our method not only achieves good performance on standard inputs, but also maintains high fidelity under adversarial perturbed inputs. The results highlight the importance of stability-aware training in operator learning and provide a foundation for developing reliable neural PDE solvers in real-world applications, where input noise and uncertainties are inevitable.
ScienceBoard: Evaluating Multimodal Autonomous Agents in Realistic Scientific Workflows
May 26, 2025



Large Language Models (LLMs) have extended their impact beyond Natural Language Processing, substantially fostering the development of interdisciplinary research. Recently, various LLM-based agents have been developed to assist scientific discovery progress across multiple aspects and domains. Among these, computer-using agents, capable of interacting with operating systems as humans do, are paving the way to automated scientific problem-solving and addressing routines in researchers' workflows. Recognizing the transformative potential of these agents, we introduce ScienceBoard, which encompasses two complementary contributions: (i) a realistic, multi-domain environment featuring dynamic and visually rich scientific workflows with integrated professional software, where agents can autonomously interact via different interfaces to accelerate complex research tasks and experiments; and (ii) a challenging benchmark of 169 high-quality, rigorously validated real-world tasks curated by humans, spanning scientific-discovery workflows in domains such as biochemistry, astronomy, and geoinformatics. Extensive evaluations of agents with state-of-the-art backbones (e.g., GPT-4o, Claude 3.7, UI-TARS) show that, despite some promising results, they still fall short of reliably assisting scientists in complex workflows, achieving only a 15% overall success rate. In-depth analysis further provides valuable insights for addressing current agent limitations and more effective design principles, paving the way to build more capable agents for scientific discovery. Our code, environment, and benchmark are at https://qiushisun.github.io/ScienceBoard-Home/.
Breaking the Data Barrier -- Building GUI Agents Through Task Generalization
Apr 15, 2025Graphical User Interface (GUI) agents offer cross-platform solutions for automating complex digital tasks, with significant potential to transform productivity workflows. However, their performance is often constrained by the scarcity of high-quality trajectory data. To address this limitation, we propose training Vision Language Models (VLMs) on data-rich, reasoning-intensive tasks during a dedicated mid-training stage, and then examine how incorporating these tasks facilitates generalization to GUI planning scenarios. Specifically, we explore a range of tasks with readily available instruction-tuning data, including GUI perception, multimodal reasoning, and textual reasoning. Through extensive experiments across 11 mid-training tasks, we demonstrate that: (1) Task generalization proves highly effective, yielding substantial improvements across most settings. For instance, multimodal mathematical reasoning enhances performance on AndroidWorld by an absolute 6.3%. Remarkably, text-only mathematical data significantly boosts GUI web agent performance, achieving a 5.6% improvement on WebArena and 5.4% improvement on AndroidWorld, underscoring notable cross-modal generalization from text-based to visual domains; (2) Contrary to prior assumptions, GUI perception data - previously considered closely aligned with GUI agent tasks and widely utilized for training - has a comparatively limited impact on final performance; (3) Building on these insights, we identify the most effective mid-training tasks and curate optimized mixture datasets, resulting in absolute performance gains of 8.0% on WebArena and 12.2% on AndroidWorld. Our work provides valuable insights into cross-domain knowledge transfer for GUI agents and offers a practical approach to addressing data scarcity challenges in this emerging field. The code, data and models will be available at https://github.com/hkust-nlp/GUIMid.
Genius: A Generalizable and Purely Unsupervised Self-Training Framework For Advanced Reasoning
Apr 11, 2025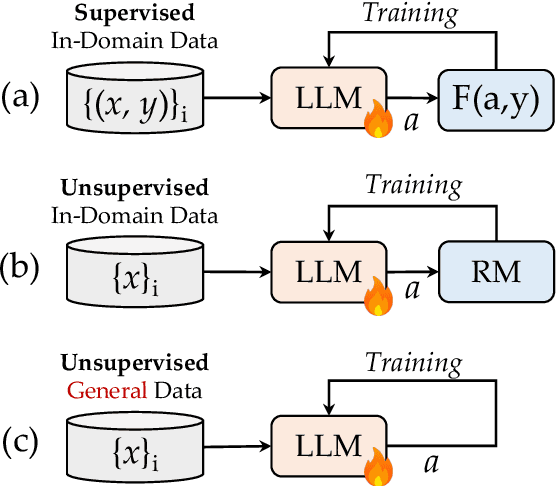
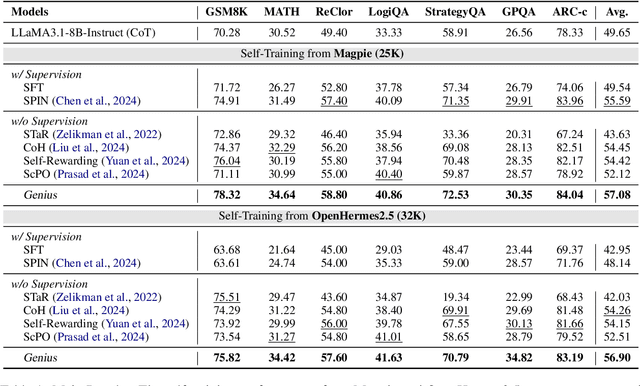
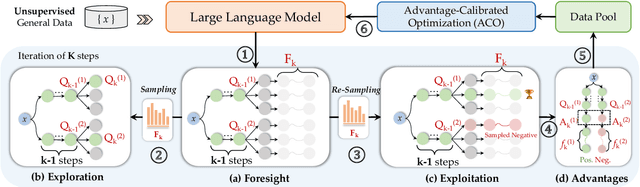

Advancing LLM reasoning skills has captivated wide interest. However, current post-training techniques rely heavily on supervisory signals, such as outcome supervision or auxiliary reward models, which face the problem of scalability and high annotation costs. This motivates us to enhance LLM reasoning without the need for external supervision. We introduce a generalizable and purely unsupervised self-training framework, named Genius. Without external auxiliary, Genius requires to seek the optimal response sequence in a stepwise manner and optimize the LLM. To explore the potential steps and exploit the optimal ones, Genius introduces a stepwise foresight re-sampling strategy to sample and estimate the step value by simulating future outcomes. Further, we recognize that the unsupervised setting inevitably induces the intrinsic noise and uncertainty. To provide a robust optimization, we propose an advantage-calibrated optimization (ACO) loss function to mitigate estimation inconsistencies. Combining these techniques together, Genius provides an advanced initial step towards self-improve LLM reasoning with general queries and without supervision, revolutionizing reasoning scaling laws given the vast availability of general queries. The code will be released at https://github.com/xufangzhi/Genius.
$φ$-Decoding: Adaptive Foresight Sampling for Balanced Inference-Time Exploration and Exploitation
Mar 17, 2025Inference-time optimization scales computation to derive deliberate reasoning steps for effective performance. While previous search-based strategies address the short-sightedness of auto-regressive generation, the vast search space leads to excessive exploration and insufficient exploitation. To strike an efficient balance to derive the optimal step, we frame the decoding strategy as foresight sampling, leveraging simulated future steps to obtain globally optimal step estimation. Built on it, we propose a novel decoding strategy, named $\phi$-Decoding. To provide a precise and expressive estimation of step value, $\phi$-Decoding approximates two distributions via foresight and clustering. Sampling from the joint distribution, the optimal steps can be selected for exploitation. To support adaptive computation allocation, we propose in-width and in-depth pruning strategies, featuring a light-weight solution to achieve inference efficiency. Extensive experiments across seven benchmarks show $\phi$-Decoding outperforms strong baselines in both performance and efficiency. Additional analysis demonstrates its generalization across various LLMs and scalability across a wide range of computing budgets. The code will be released at https://github.com/xufangzhi/phi-Decoding, and the open-source PyPI package is coming soon.
BioMaze: Benchmarking and Enhancing Large Language Models for Biological Pathway Reasoning
Feb 23, 2025The applications of large language models (LLMs) in various biological domains have been explored recently, but their reasoning ability in complex biological systems, such as pathways, remains underexplored, which is crucial for predicting biological phenomena, formulating hypotheses, and designing experiments. This work explores the potential of LLMs in pathway reasoning. We introduce BioMaze, a dataset with 5.1K complex pathway problems derived from real research, covering various biological contexts including natural dynamic changes, disturbances, additional intervention conditions, and multi-scale research targets. Our evaluation of methods such as CoT and graph-augmented reasoning, shows that LLMs struggle with pathway reasoning, especially in perturbed systems. To address this, we propose PathSeeker, an LLM agent that enhances reasoning through interactive subgraph-based navigation, enabling a more effective approach to handling the complexities of biological systems in a scientifically aligned manner. The dataset and code are available at https://github.com/zhao-ht/BioMaze.
A Survey on Large Language Model-Based Social Agents in Game-Theoretic Scenarios
Dec 05, 2024



Game-theoretic scenarios have become pivotal in evaluating the social intelligence of Large Language Model (LLM)-based social agents. While numerous studies have explored these agents in such settings, there is a lack of a comprehensive survey summarizing the current progress. To address this gap, we systematically review existing research on LLM-based social agents within game-theoretic scenarios. Our survey organizes the findings into three core components: Game Framework, Social Agent, and Evaluation Protocol. The game framework encompasses diverse game scenarios, ranging from choice-focusing to communication-focusing games. The social agent part explores agents' preferences, beliefs, and reasoning abilities. The evaluation protocol covers both game-agnostic and game-specific metrics for assessing agent performance. By reflecting on the current research and identifying future research directions, this survey provides insights to advance the development and evaluation of social agents in game-theoretic scenarios.
Non-myopic Generation of Language Models for Reasoning and Planning
Oct 28, 2024



Large Language Models have demonstrated remarkable abilities in reasoning and planning by breaking down complex problems into sequential steps. Despite their success in various domains like mathematical problem-solving and coding, LLMs face challenges in ensuring reliable and optimal planning due to their inherent myopic nature of autoregressive decoding. This paper revisits LLM reasoning from an optimal-control perspective, proposing a novel method, Predictive-Decoding, that leverages Model Predictive Control to enhance planning accuracy. By re-weighting LLM distributions based on foresight trajectories, Predictive-Decoding aims to mitigate early errors and promote non-myopic planning. Our experiments show significant improvements in a wide range of tasks for math, coding, and agents. Furthermore, Predictive-Decoding demonstrates computational efficiency, outperforming search baselines with reduced computational resources. This study provides insights into optimizing LLM planning capabilities.
Non-myopic Generation of Language Model for Reasoning and Planning
Oct 23, 2024Large Language Models have demonstrated remarkable abilities in reasoning and planning by breaking down complex problems into sequential steps. Despite their success in various domains like mathematical problem-solving and coding, LLMs face challenges in ensuring reliable and optimal planning due to their inherent myopic nature of autoregressive decoding. This paper revisits LLM reasoning from an optimal-control perspective, proposing a novel method, Predictive-Decoding, that leverages Model Predictive Control to enhance planning accuracy. By re-weighting LLM distributions based on foresight trajectories, Predictive-Decoding aims to mitigate early errors and promote non-myopic planning. Our experiments show significant improvements in a wide range of tasks for math, coding, and agents. Furthermore, Predictive-Decoding demonstrates computational efficiency, outperforming search baselines with reduced computational resources. This study provides insights into optimizing LLM planning capabilities.
Instruction-Based Molecular Graph Generation with Unified Text-Graph Diffusion Model
Aug 19, 2024Recent advancements in computational chemistry have increasingly focused on synthesizing molecules based on textual instructions. Integrating graph generation with these instructions is complex, leading most current methods to use molecular sequences with pre-trained large language models. In response to this challenge, we propose a novel framework, named $\textbf{UTGDiff (Unified Text-Graph Diffusion Model)}$, which utilizes language models for discrete graph diffusion to generate molecular graphs from instructions. UTGDiff features a unified text-graph transformer as the denoising network, derived from pre-trained language models and minimally modified to process graph data through attention bias. Our experimental results demonstrate that UTGDiff consistently outperforms sequence-based baselines in tasks involving instruction-based molecule generation and editing, achieving superior performance with fewer parameters given an equivalent level of pretraining corpus. Our code is availble at https://github.com/ran1812/UTGDiff.