 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Multimodal Agents Really Benefit from Tool Use? A Systematic Study of Capability Gains
Jun 01, 2026Tool-augmented multimodal agents show strong benchmark gains, often taken as evidence that agents have learned to use tools. We argue that this interpretation can be premature: a tool-call trace alone does not show whether the tool supplied answer-critical information. We study two representative ``thinking with images'' agents, Thyme and DeepEyesV2, across real-world understanding, OCR, chart understanding, and mathematical reasoning. Each agent is compared with its Tool-Free counterpart and with a Pure-Text Reasoner trained from the same source pool without tool-calling trajectories. Tool access yields little consistent aggregate improvement, does not reliably reduce generated-token cost, and leaves only a small tool-only solved set: 93% of DeepEyesV2's tool-solved problems and 96% of Thyme's are also solved by at least one non-tool setting. Mechanism ablations further show that the full tool-use loop does not consistently outperform either the tool-call format or the returned execution result alone. In the settings we study, the analyzed agents appear to learn tool-calling patterns more reliably than tool-contributed capabilities, suggesting that evaluation should distinguish tool availability from whether tools actually expand what agents can solve.
A Survey on Large Language Model-Based Social Agents in Game-Theoretic Scenarios
Dec 05, 2024



Game-theoretic scenarios have become pivotal in evaluating the social intelligence of Large Language Model (LLM)-based social agents. While numerous studies have explored these agents in such settings, there is a lack of a comprehensive survey summarizing the current progress. To address this gap, we systematically review existing research on LLM-based social agents within game-theoretic scenarios. Our survey organizes the findings into three core components: Game Framework, Social Agent, and Evaluation Protocol. The game framework encompasses diverse game scenarios, ranging from choice-focusing to communication-focusing games. The social agent part explores agents' preferences, beliefs, and reasoning abilities. The evaluation protocol covers both game-agnostic and game-specific metrics for assessing agent performance. By reflecting on the current research and identifying future research directions, this survey provides insights to advance the development and evaluation of social agents in game-theoretic scenarios.
Deep Reinforcement Learning for Solving Management Problems: Towards A Large Management Mode
Mar 01, 2024



We introduce a deep reinforcement learning (DRL) approach for solving management problems including inventory management, dynamic pricing, and recommendation. This DRL approach has the potential to lead to a large management model based on certain transformer neural network structures, resulting in an artificial general intelligence paradigm for various management tasks. Traditional methods have limitations for solving complex real-world problems, and we demonstrate how DRL can surpass existing heuristic approaches for solving management tasks. We aim to solve the problems in a unified framework, considering the interconnections between different tasks. Central to our methodology is the development of a foundational decision model coordinating decisions across the different domains through generative decision-making. Our experimental results affirm the effectiveness of our DRL-based framework in complex and dynamic business environments. This work opens new pathways for the application of DRL in management problems, highlighting its potential to revolutionize traditional business management.
An Electrocommunication System Using FSK Modulation and Deep Learning Based Demodulation for Underwater Robots
Aug 24, 2020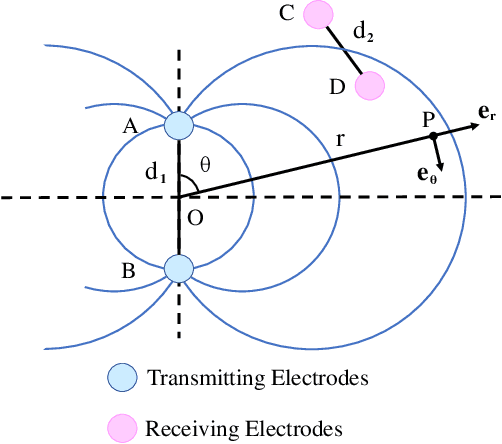
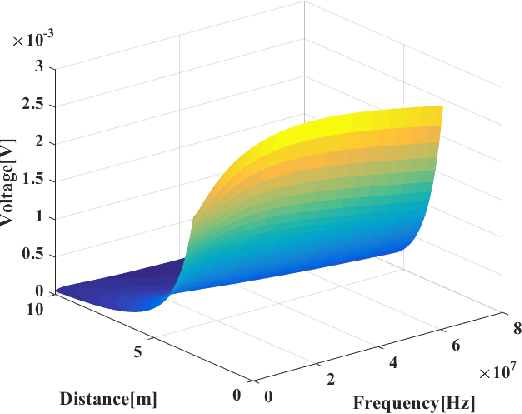
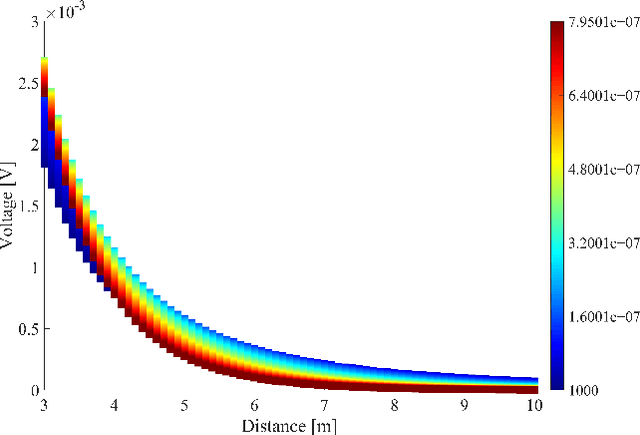
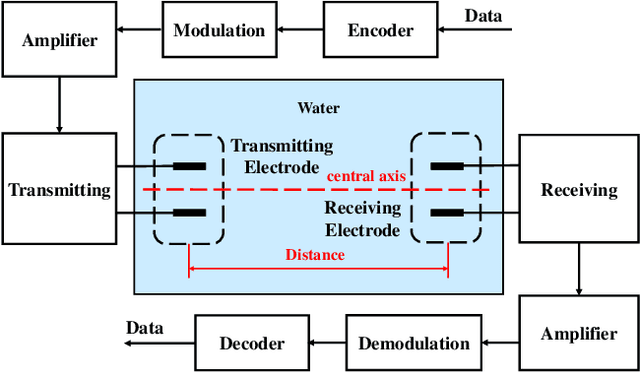
Underwater communication is extremely challenging for small underwater robots which typically have stringent power and size constraints. In our previous work, we developed an artificial electrocommunication system which could be an alternative for the communication of small underwater robots. This paper further presents a new electrocommunication system that utilizes Binary Frequency Shift Keying (2FSK) modulation and deep-learning-based demodulation for underwater robots. We first derive an underwater electrocommunication model that covers both the near-field area and a large transition area outside of the near-field area. 2FSK modulation is adopted to improve the anti-interference ability of the electric signal. A deep learning algorithm is used to demodulate the electric signal by the receiver. Simulations and experiments show that with the same testing condition, the new communication system outperforms the previous system in both the communication distance and the data transmitting rate. In specific, the newly developed communication system achieves stable communication within the distance of 10 m at a data transfer rate of 5 Kbps with a power consumption of less than 0.1 W. The substantial increase in communication distance further improves the possibility of electrocommunication in underwater robotics.