 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSharpness-diversity tradeoff: improving flat ensembles with SharpBalance
Jul 17, 2024



Recent studies on deep ensembles have identified the sharpness of the local minima of individual learners and the diversity of the ensemble members as key factors in improving test-time performance. Building on this, our study investigates the interplay between sharpness and diversity within deep ensembles, illustrating their crucial role in robust generalization to both in-distribution (ID) and out-of-distribution (OOD) data. We discover a trade-off between sharpness and diversity: minimizing the sharpness in the loss landscape tends to diminish the diversity of individual members within the ensemble, adversely affecting the ensemble's improvement. The trade-off is justified through our theoretical analysis and verified empirically through extensive experiments. To address the issue of reduced diversity, we introduce SharpBalance, a novel training approach that balances sharpness and diversity within ensembles. Theoretically, we show that our training strategy achieves a better sharpness-diversity trade-off. Empirically, we conducted comprehensive evaluations in various data sets (CIFAR-10, CIFAR-100, TinyImageNet) and showed that SharpBalance not only effectively improves the sharpness-diversity trade-off, but also significantly improves ensemble performance in ID and OOD scenarios.
Deep Reinforcement Learning for Solving Management Problems: Towards A Large Management Mode
Mar 01, 2024



We introduce a deep reinforcement learning (DRL) approach for solving management problems including inventory management, dynamic pricing, and recommendation. This DRL approach has the potential to lead to a large management model based on certain transformer neural network structures, resulting in an artificial general intelligence paradigm for various management tasks. Traditional methods have limitations for solving complex real-world problems, and we demonstrate how DRL can surpass existing heuristic approaches for solving management tasks. We aim to solve the problems in a unified framework, considering the interconnections between different tasks. Central to our methodology is the development of a foundational decision model coordinating decisions across the different domains through generative decision-making. Our experimental results affirm the effectiveness of our DRL-based framework in complex and dynamic business environments. This work opens new pathways for the application of DRL in management problems, highlighting its potential to revolutionize traditional business management.
Improving Generalization in Task-oriented Dialogues with Workflows and Action Plans
Jun 02, 2023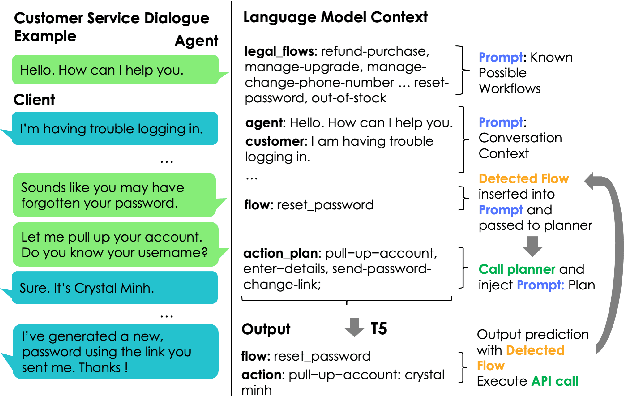

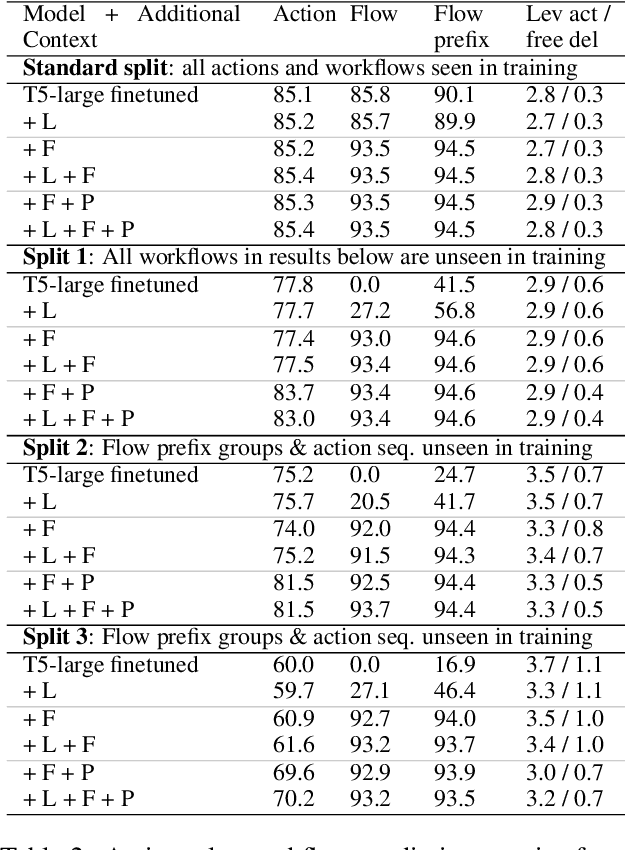
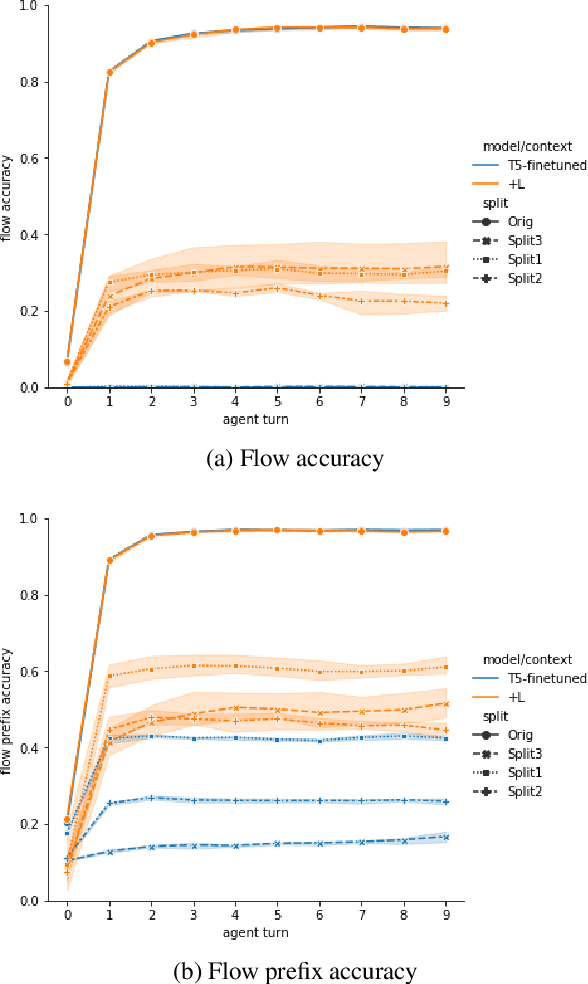
Task-oriented dialogue is difficult in part because it involves understanding user intent, collecting information from the user, executing API calls, and generating helpful and fluent responses. However, for complex tasks one must also correctly do all of these things over multiple steps, and in a specific order. While large pre-trained language models can be fine-tuned end-to-end to create multi-step task-oriented dialogue agents that generate fluent text, our experiments confirm that this approach alone cannot reliably perform new multi-step tasks that are unseen during training. To address these limitations, we augment the dialogue contexts given to \textmd{text2text} transformers with known \textit{valid workflow names} and \textit{action plans}. Action plans consist of sequences of actions required to accomplish a task, and are encoded as simple sequences of keywords (e.g. verify-identity, pull-up-account, reset-password, etc.). We perform extensive experiments on the Action-Based Conversations Dataset (ABCD) with T5-small, base and large models, and show that such models: a) are able to more readily generalize to unseen workflows by following the provided plan, and b) are able to generalize to executing unseen actions if they are provided in the plan. In contrast, models are unable to fully accomplish new multi-step tasks when they are not provided action plan information, even when given new valid workflow names.
Egocentric Planning for Scalable Embodied Task Achievement
Jun 02, 2023Embodied agents face significant challenges when tasked with performing actions in diverse environments, particularly in generalizing across object types and executing suitable actions to accomplish tasks. Furthermore, agents should exhibit robustness, minimizing the execution of illegal actions. In this work, we present Egocentric Planning, an innovative approach that combines symbolic planning and Object-oriented POMDPs to solve tasks in complex environments, harnessing existing models for visual perception and natural language processing. We evaluated our approach in ALFRED, a simulated environment designed for domestic tasks, and demonstrated its high scalability, achieving an impressive 36.07% unseen success rate in the ALFRED benchmark and winning the ALFRED challenge at CVPR Embodied AI workshop. Our method requires reliable perception and the specification or learning of a symbolic description of the preconditions and effects of the agent's actions, as well as what object types reveal information about others. It is capable of naturally scaling to solve new tasks beyond ALFRED, as long as they can be solved using the available skills. This work offers a solid baseline for studying end-to-end and hybrid methods that aim to generalize to new tasks, including recent approaches relying on LLMs, but often struggle to scale to long sequences of actions or produce robust plans for novel tasks.
pyRDDLGym: From RDDL to Gym Environments
Nov 14, 2022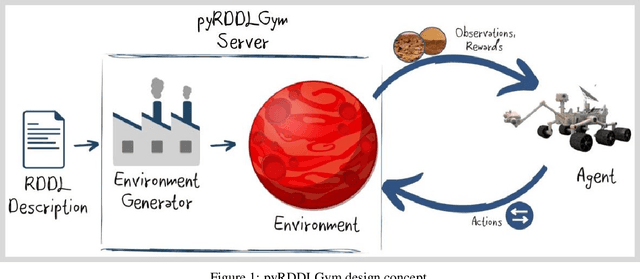



We present pyRDDLGym, a Python framework for auto-generation of OpenAI Gym environments from RDDL declerative description. The discrete time step evolution of variables in RDDL is described by conditional probability functions, which fits naturally into the Gym step scheme. Furthermore, since RDDL is a lifted description, the modification and scaling up of environments to support multiple entities and different configurations becomes trivial rather than a tedious process prone to errors. We hope that pyRDDLGym will serve as a new wind in the reinforcement learning community by enabling easy and rapid development of benchmarks due to the unique expressive power of RDDL. By providing explicit access to the model in the RDDL description, pyRDDLGym can also facilitate research on hybrid approaches for learning from interaction while leveraging model knowledge. We present the design and built-in examples of pyRDDLGym, and the additions made to the RDDL language that were incorporated into the framework.
Robustness-Driven Exploration with Probabilistic Metric Temporal Logic
Dec 03, 2019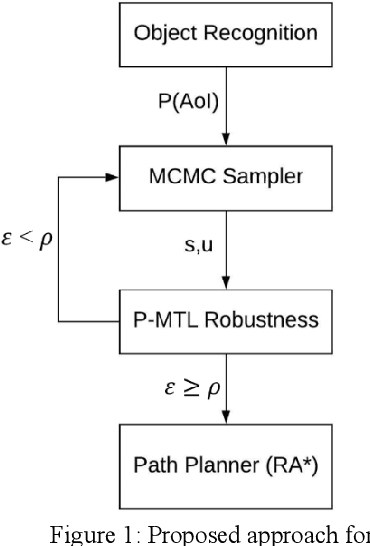
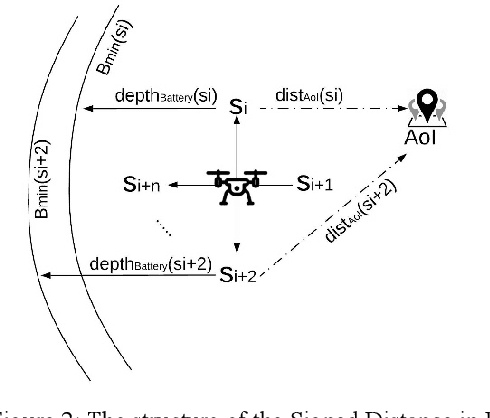
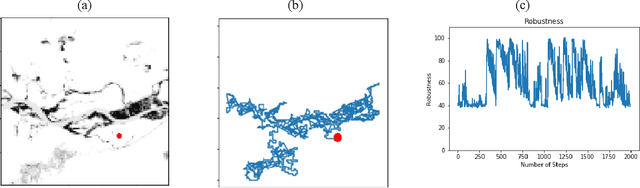

The ability to perform autonomous exploration is essential for unmanned aerial vehicles (UAV) operating in unstructured or unknown environments where it is hard or even impossible to describe the environment beforehand. However, algorithms for autonomous exploration often focus on optimizing time and coverage in a greedy fashion. That type of exploration can collect irrelevant data and wastes time navigating areas with no important information. In this paper, we propose a method for exploiting the discovered knowledge about the environment while exploring it by relying on a theory of robustness based on Probabilistic Metric Temporal Logic (P-MTL) as applied to offline verification and online control of hybrid systems. By maximizing the satisfaction of the predefined P-MTL specifications of the exploration problem, the robustness values guide the UAV towards areas with more interesting information to gain. We use Markov Chain Monte Carlo to solve the P-MTL constraints. We demonstrate the effectiveness of the proposed approach by simulating autonomous exploration over Amazonian rainforest where our approach is used to detect areas occupied by illegal Artisanal Small-scale Gold Mining (ASGM) activities. The results show that our approach outperform a greedy exploration approach (Autonomous Exploration Planner) by 38% in terms of ASGM coverage.