 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Language Models Know the Answer Before Decoding
Aug 27, 2025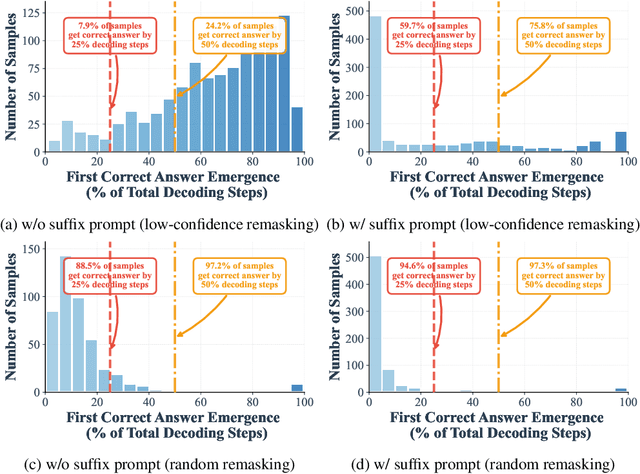
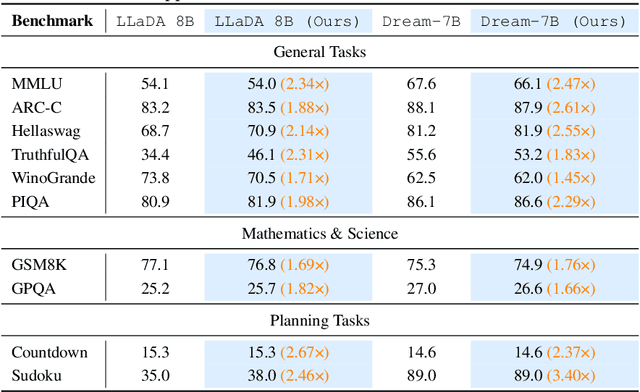
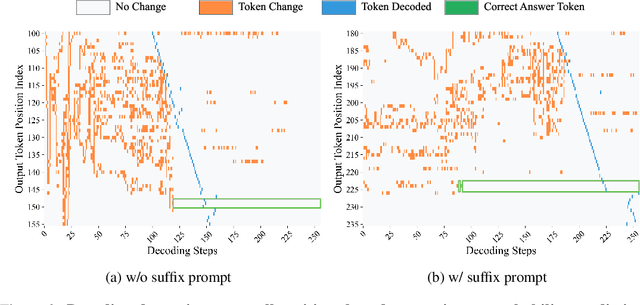
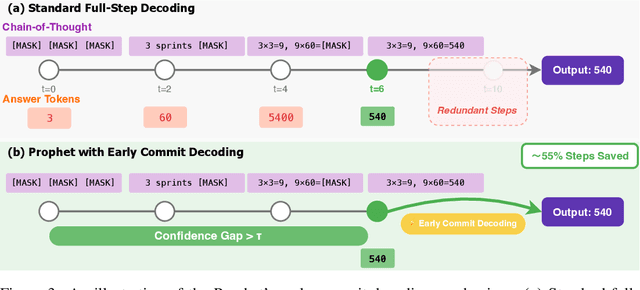
Diffusion language models (DLMs) have recently emerged as an alternative to autoregressive approaches, offering parallel sequence generation and flexible token orders. However, their inference remains slower than that of autoregressive models, primarily due to the cost of bidirectional attention and the large number of refinement steps required for high quality outputs. In this work, we highlight and leverage an overlooked property of DLMs early answer convergence: in many cases, the correct answer can be internally identified by half steps before the final decoding step, both under semi-autoregressive and random remasking schedules. For example, on GSM8K and MMLU, up to 97% and 99% of instances, respectively, can be decoded correctly using only half of the refinement steps. Building on this observation, we introduce Prophet, a training-free fast decoding paradigm that enables early commit decoding. Specifically, Prophet dynamically decides whether to continue refinement or to go "all-in" (i.e., decode all remaining tokens in one step), using the confidence gap between the top-2 prediction candidates as the criterion. It integrates seamlessly into existing DLM implementations, incurs negligible overhead, and requires no additional training. Empirical evaluations of LLaDA-8B and Dream-7B across multiple tasks show that Prophet reduces the number of decoding steps by up to 3.4x while preserving high generation quality. These results recast DLM decoding as a problem of when to stop sampling, and demonstrate that early decode convergence provides a simple yet powerful mechanism for accelerating DLM inference, complementary to existing speedup techniques. Our code is publicly available at https://github.com/pixeli99/Prophet.
A Model Zoo on Phase Transitions in Neural Networks
Apr 25, 2025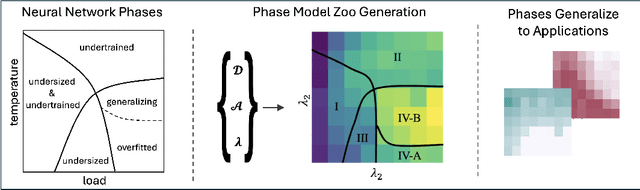
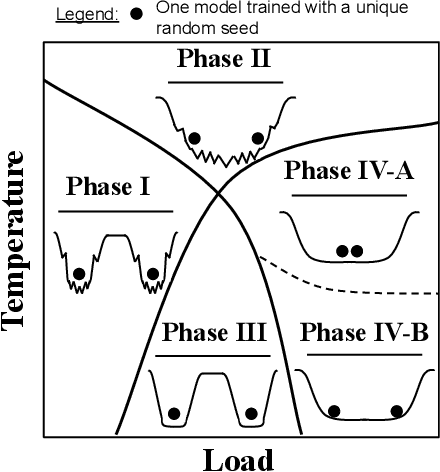

Using the weights of trained Neural Network (NN) models as data modality has recently gained traction as a research field - dubbed Weight Space Learning (WSL). Multiple recent works propose WSL methods to analyze models, evaluate methods, or synthesize weights. Weight space learning methods require populations of trained models as datasets for development and evaluation. However, existing collections of models - called `model zoos' - are unstructured or follow a rudimentary definition of diversity. In parallel, work rooted in statistical physics has identified phases and phase transitions in NN models. Models are homogeneous within the same phase but qualitatively differ from one phase to another. We combine the idea of `model zoos' with phase information to create a controlled notion of diversity in populations. We introduce 12 large-scale zoos that systematically cover known phases and vary over model architecture, size, and datasets. These datasets cover different modalities, such as computer vision, natural language processing, and scientific ML. For every model, we compute loss landscape metrics and validate full coverage of the phases. With this dataset, we provide the community with a resource with a wide range of potential applications for WSL and beyond. Evidence suggests the loss landscape phase plays a role in applications such as model training, analysis, or sparsification. We demonstrate this in an exploratory study of the downstream methods like transfer learning or model weights averaging.
Model Balancing Helps Low-data Training and Fine-tuning
Oct 16, 2024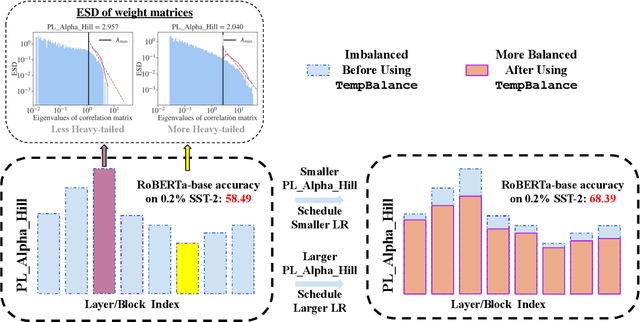

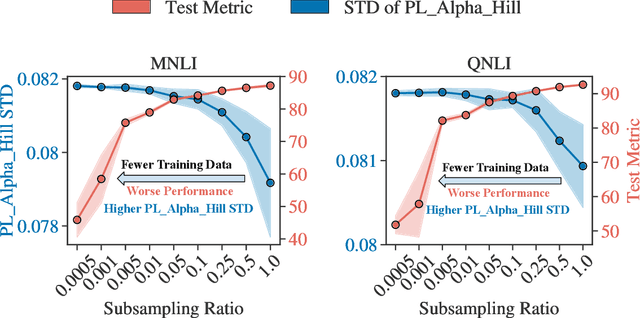
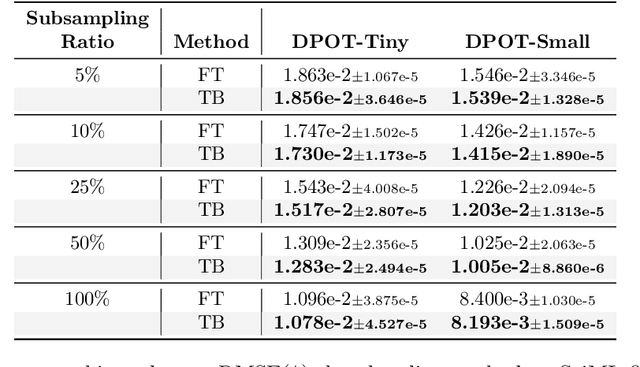
Recent advances in foundation models have emphasized the need to align pre-trained models with specialized domains using small, curated datasets. Studies on these foundation models underscore the importance of low-data training and fine-tuning. This topic, well-known in natural language processing (NLP), has also gained increasing attention in the emerging field of scientific machine learning (SciML). To address the limitations of low-data training and fine-tuning, we draw inspiration from Heavy-Tailed Self-Regularization (HT-SR) theory, analyzing the shape of empirical spectral densities (ESDs) and revealing an imbalance in training quality across different model layers. To mitigate this issue, we adapt a recently proposed layer-wise learning rate scheduler, TempBalance, which effectively balances training quality across layers and enhances low-data training and fine-tuning for both NLP and SciML tasks. Notably, TempBalance demonstrates increasing performance gains as the amount of available tuning data decreases. Comparative analyses further highlight the effectiveness of TempBalance and its adaptability as an "add-on" method for improving model performance.
AlphaPruning: Using Heavy-Tailed Self Regularization Theory for Improved Layer-wise Pruning of Large Language Models
Oct 14, 2024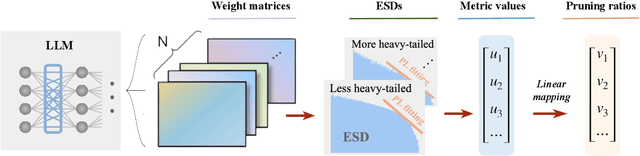
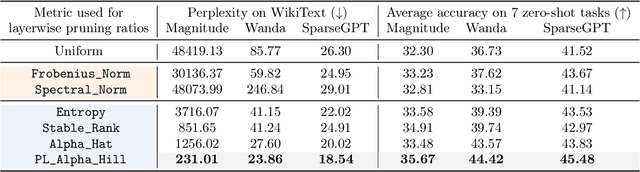
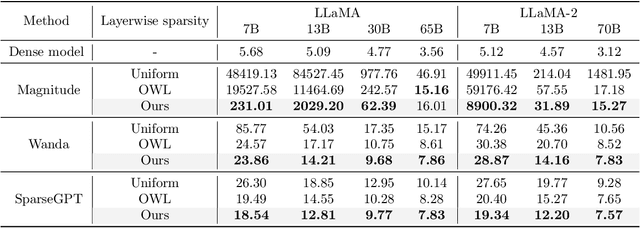
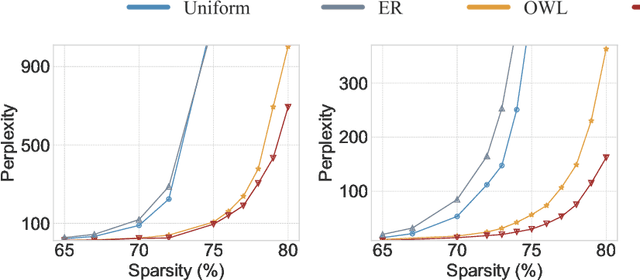
Recent work on pruning large language models (LLMs) has shown that one can eliminate a large number of parameters without compromising performance, making pruning a promising strategy to reduce LLM model size. Existing LLM pruning strategies typically assign uniform pruning ratios across layers, limiting overall pruning ability; and recent work on layerwise pruning of LLMs is often based on heuristics that can easily lead to suboptimal performance. In this paper, we leverage Heavy-Tailed Self-Regularization (HT-SR) Theory, in particular the shape of empirical spectral densities (ESDs) of weight matrices, to design improved layerwise pruning ratios for LLMs. Our analysis reveals a wide variability in how well-trained, and thus relatedly how prunable, different layers of an LLM are. Based on this, we propose AlphaPruning, which uses shape metrics to allocate layerwise sparsity ratios in a more theoretically principled manner. AlphaPruning can be used in conjunction with multiple existing LLM pruning methods. Our empirical results show that AlphaPruning prunes LLaMA-7B to 80% sparsity while maintaining reasonable perplexity, marking a first in the literature on LLMs. We have open-sourced our code at https://github.com/haiquanlu/AlphaPruning.
AlphaLoRA: Assigning LoRA Experts Based on Layer Training Quality
Oct 14, 2024Parameter-efficient fine-tuning methods, such as Low-Rank Adaptation (LoRA), are known to enhance training efficiency in Large Language Models (LLMs). Due to the limited parameters of LoRA, recent studies seek to combine LoRA with Mixture-of-Experts (MoE) to boost performance across various tasks. However, inspired by the observed redundancy in traditional MoE structures, previous studies identify similar redundancy among LoRA experts within the MoE architecture, highlighting the necessity for non-uniform allocation of LoRA experts across different layers. In this paper, we leverage Heavy-Tailed Self-Regularization (HT-SR) Theory to design a fine-grained allocation strategy. Our analysis reveals that the number of experts per layer correlates with layer training quality, which exhibits significant variability across layers. Based on this, we introduce AlphaLoRA, a theoretically principled and training-free method for allocating LoRA experts to further mitigate redundancy. Experiments on three models across ten language processing and reasoning benchmarks demonstrate that AlphaLoRA achieves comparable or superior performance over all baselines. Our code is available at https://github.com/morelife2017/alphalora.
Sharpness-diversity tradeoff: improving flat ensembles with SharpBalance
Jul 17, 2024



Recent studies on deep ensembles have identified the sharpness of the local minima of individual learners and the diversity of the ensemble members as key factors in improving test-time performance. Building on this, our study investigates the interplay between sharpness and diversity within deep ensembles, illustrating their crucial role in robust generalization to both in-distribution (ID) and out-of-distribution (OOD) data. We discover a trade-off between sharpness and diversity: minimizing the sharpness in the loss landscape tends to diminish the diversity of individual members within the ensemble, adversely affecting the ensemble's improvement. The trade-off is justified through our theoretical analysis and verified empirically through extensive experiments. To address the issue of reduced diversity, we introduce SharpBalance, a novel training approach that balances sharpness and diversity within ensembles. Theoretically, we show that our training strategy achieves a better sharpness-diversity trade-off. Empirically, we conducted comprehensive evaluations in various data sets (CIFAR-10, CIFAR-100, TinyImageNet) and showed that SharpBalance not only effectively improves the sharpness-diversity trade-off, but also significantly improves ensemble performance in ID and OOD scenarios.
MD tree: a model-diagnostic tree grown on loss landscape
Jun 24, 2024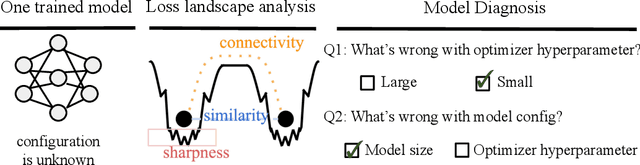
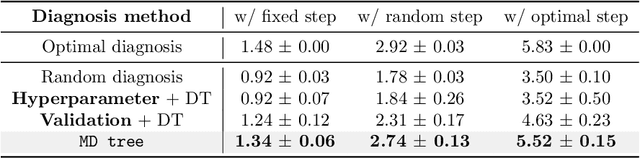
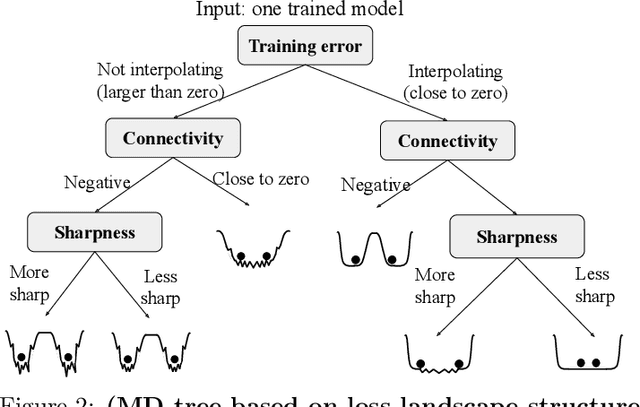
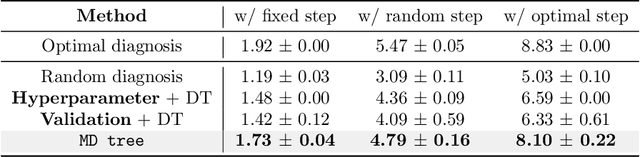
This paper considers "model diagnosis", which we formulate as a classification problem. Given a pre-trained neural network (NN), the goal is to predict the source of failure from a set of failure modes (such as a wrong hyperparameter, inadequate model size, and insufficient data) without knowing the training configuration of the pre-trained NN. The conventional diagnosis approach uses training and validation errors to determine whether the model is underfitting or overfitting. However, we show that rich information about NN performance is encoded in the optimization loss landscape, which provides more actionable insights than validation-based measurements. Therefore, we propose a diagnosis method called MD tree based on loss landscape metrics and experimentally demonstrate its advantage over classical validation-based approaches. We verify the effectiveness of MD tree in multiple practical scenarios: (1) use several models trained on one dataset to diagnose a model trained on another dataset, essentially a few-shot dataset transfer problem; (2) use small models (or models trained with small data) to diagnose big models (or models trained with big data), essentially a scale transfer problem. In a dataset transfer task, MD tree achieves an accuracy of 87.7%, outperforming validation-based approaches by 14.88%. Our code is available at https://github.com/YefanZhou/ModelDiagnosis.
Temperature Balancing, Layer-wise Weight Analysis, and Neural Network Training
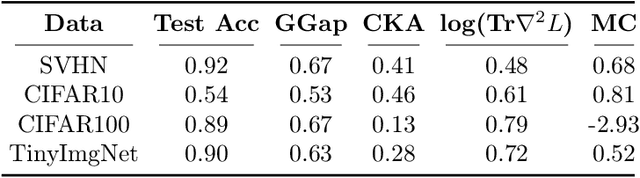
Dec 01, 2023Regularization in modern machine learning is crucial, and it can take various forms in algorithmic design: training set, model family, error function, regularization terms, and optimizations. In particular, the learning rate, which can be interpreted as a temperature-like parameter within the statistical mechanics of learning, plays a crucial role in neural network training. Indeed, many widely adopted training strategies basically just define the decay of the learning rate over time. This process can be interpreted as decreasing a temperature, using either a global learning rate (for the entire model) or a learning rate that varies for each parameter. This paper proposes TempBalance, a straightforward yet effective layer-wise learning rate method. TempBalance is based on Heavy-Tailed Self-Regularization (HT-SR) Theory, an approach which characterizes the implicit self-regularization of different layers in trained models. We demonstrate the efficacy of using HT-SR-motivated metrics to guide the scheduling and balancing of temperature across all network layers during model training, resulting in improved performance during testing. We implement TempBalance on CIFAR10, CIFAR100, SVHN, and TinyImageNet datasets using ResNets, VGGs, and WideResNets with various depths and widths. Our results show that TempBalance significantly outperforms ordinary SGD and carefully-tuned spectral norm regularization. We also show that TempBalance outperforms a number of state-of-the-art optimizers and learning rate schedulers.
A Three-regime Model of Network Pruning
May 28, 2023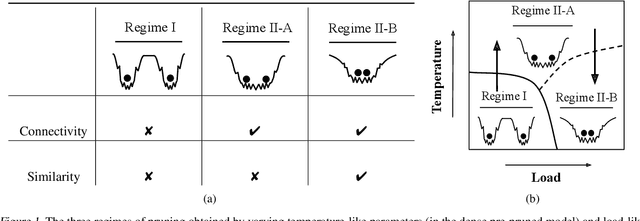
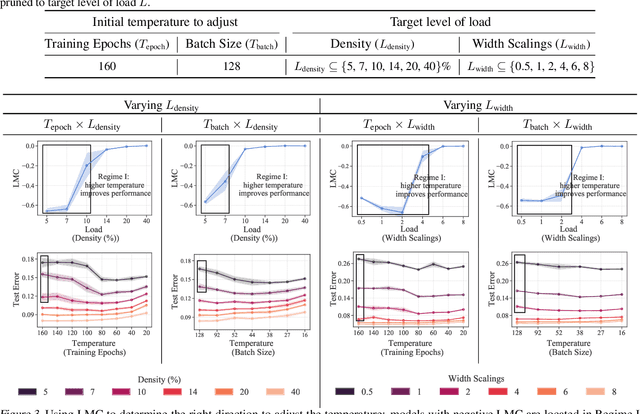
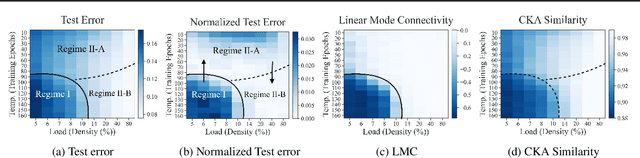

Recent work has highlighted the complex influence training hyperparameters, e.g., the number of training epochs, can have on the prunability of machine learning models. Perhaps surprisingly, a systematic approach to predict precisely how adjusting a specific hyperparameter will affect prunability remains elusive. To address this gap, we introduce a phenomenological model grounded in the statistical mechanics of learning. Our approach uses temperature-like and load-like parameters to model the impact of neural network (NN) training hyperparameters on pruning performance. A key empirical result we identify is a sharp transition phenomenon: depending on the value of a load-like parameter in the pruned model, increasing the value of a temperature-like parameter in the pre-pruned model may either enhance or impair subsequent pruning performance. Based on this transition, we build a three-regime model by taxonomizing the global structure of the pruned NN loss landscape. Our model reveals that the dichotomous effect of high temperature is associated with transitions between distinct types of global structures in the post-pruned model. Based on our results, we present three case-studies: 1) determining whether to increase or decrease a hyperparameter for improved pruning; 2) selecting the best model to prune from a family of models; and 3) tuning the hyperparameter of the Sharpness Aware Minimization method for better pruning performance.
A Dataset-Dispersion Perspective on Reconstruction Versus Recognition in Single-View 3D Reconstruction Networks
Nov 30, 2021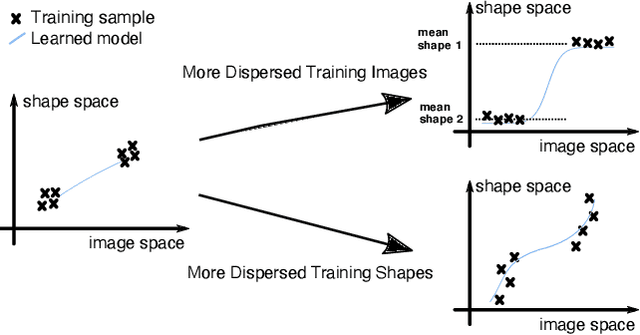
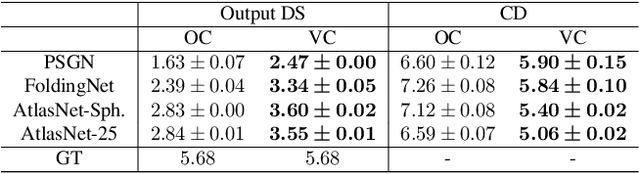
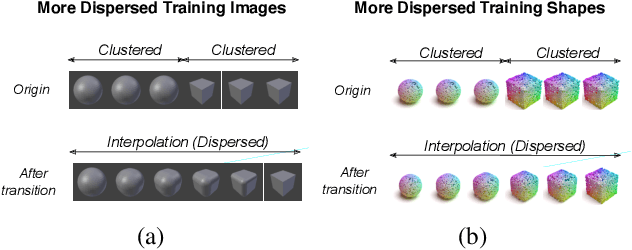
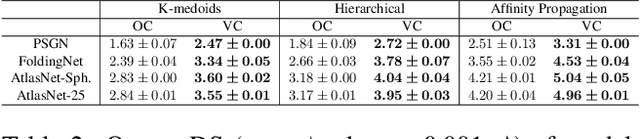
Neural networks (NN) for single-view 3D reconstruction (SVR) have gained in popularity. Recent work points out that for SVR, most cutting-edge NNs have limited performance on reconstructing unseen objects because they rely primarily on recognition (i.e., classification-based methods) rather than shape reconstruction. To understand this issue in depth, we provide a systematic study on when and why NNs prefer recognition to reconstruction and vice versa. Our finding shows that a leading factor in determining recognition versus reconstruction is how dispersed the training data is. Thus, we introduce the dispersion score, a new data-driven metric, to quantify this leading factor and study its effect on NNs. We hypothesize that NNs are biased toward recognition when training images are more dispersed and training shapes are less dispersed. Our hypothesis is supported and the dispersion score is proved effective through our experiments on synthetic and benchmark datasets. We show that the proposed metric is a principal way to analyze reconstruction quality and provides novel information in addition to the conventional reconstruction score.