 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Dataset-Dispersion Perspective on Reconstruction Versus Recognition in Single-View 3D Reconstruction Networks
Nov 30, 2021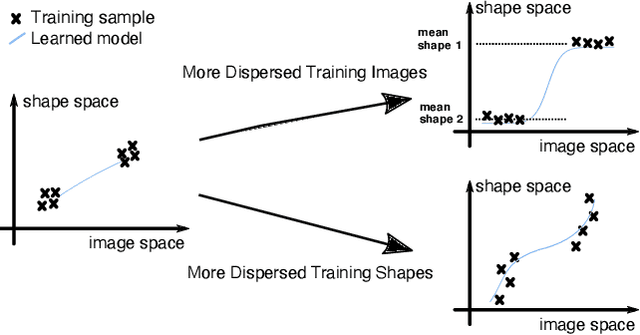
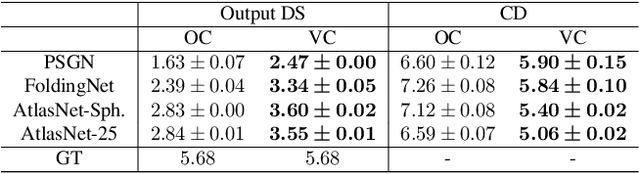
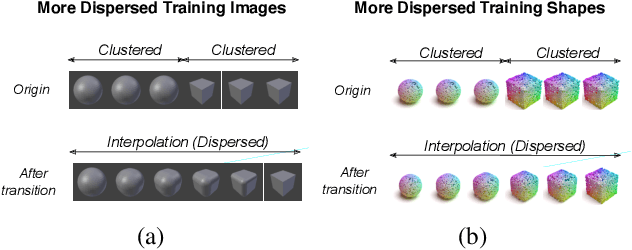
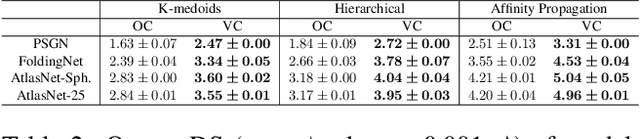
Neural networks (NN) for single-view 3D reconstruction (SVR) have gained in popularity. Recent work points out that for SVR, most cutting-edge NNs have limited performance on reconstructing unseen objects because they rely primarily on recognition (i.e., classification-based methods) rather than shape reconstruction. To understand this issue in depth, we provide a systematic study on when and why NNs prefer recognition to reconstruction and vice versa. Our finding shows that a leading factor in determining recognition versus reconstruction is how dispersed the training data is. Thus, we introduce the dispersion score, a new data-driven metric, to quantify this leading factor and study its effect on NNs. We hypothesize that NNs are biased toward recognition when training images are more dispersed and training shapes are less dispersed. Our hypothesis is supported and the dispersion score is proved effective through our experiments on synthetic and benchmark datasets. We show that the proposed metric is a principal way to analyze reconstruction quality and provides novel information in addition to the conventional reconstruction score.
OpenEDS: Open Eye Dataset
May 17, 2019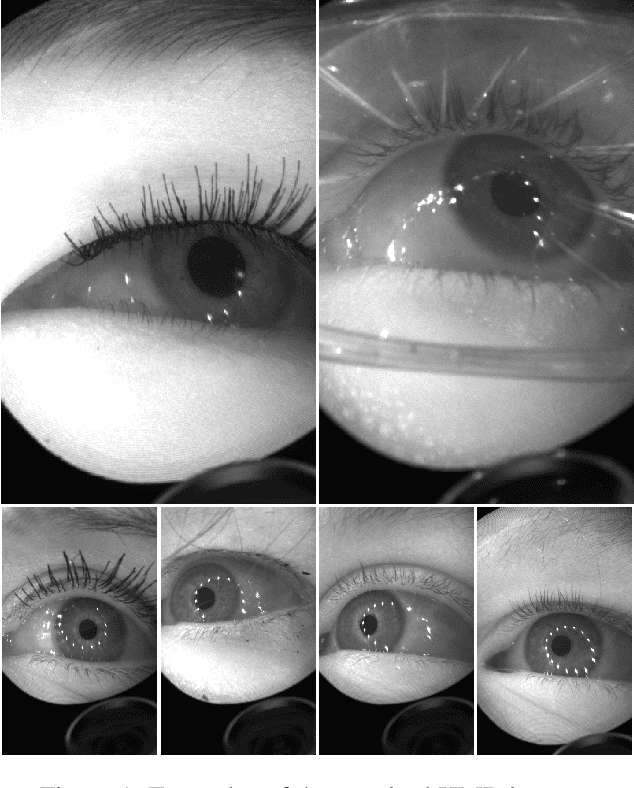
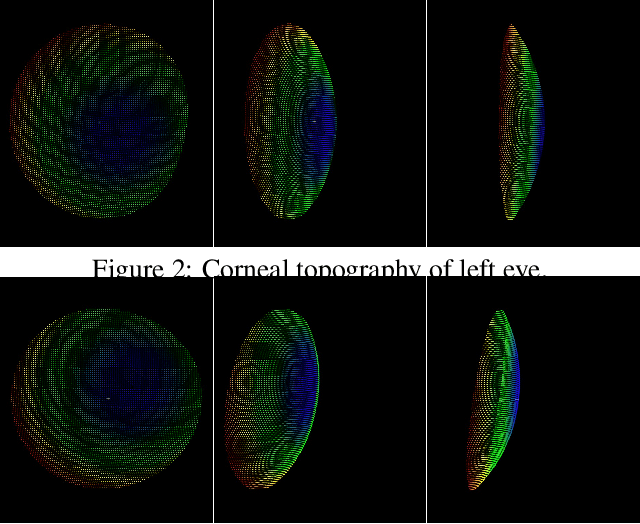

We present a large scale data set, OpenEDS: Open Eye Dataset, of eye-images captured using a virtual-reality (VR) head mounted display mounted with two synchronized eyefacing cameras at a frame rate of 200 Hz under controlled illumination. This dataset is compiled from video capture of the eye-region collected from 152 individual participants and is divided into four subsets: (i) 12,759 images with pixel-level annotations for key eye-regions: iris, pupil and sclera (ii) 252,690 unlabelled eye-images, (iii) 91,200 frames from randomly selected video sequence of 1.5 seconds in duration and (iv) 143 pairs of left and right point cloud data compiled from corneal topography of eye regions collected from a subset, 143 out of 152, participants in the study. A baseline experiment has been evaluated on OpenEDS for the task of semantic segmentation of pupil, iris, sclera and background, with the mean intersectionover-union (mIoU) of 98.3 %. We anticipate that OpenEDS will create opportunities to researchers in the eye tracking community and the broader machine learning and computer vision community to advance the state of eye-tracking for VR applications. The dataset is available for download upon request at https://research.fb.com/programs/openeds-challenge
The Impact of Quantity of Training Data on Recognition of Eating Gestures
Dec 11, 2018
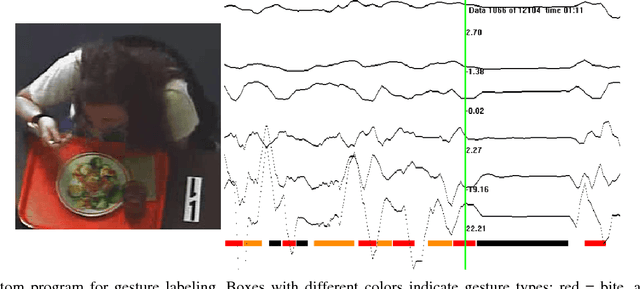
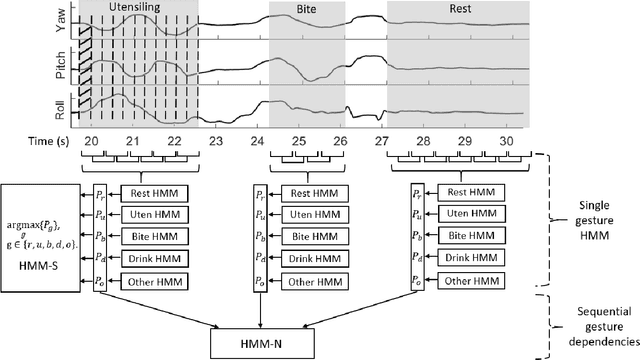
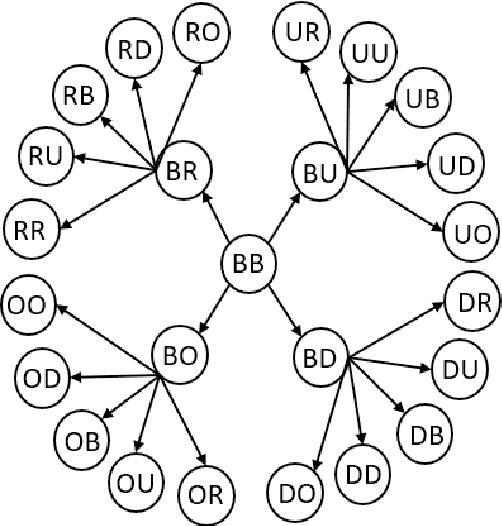
This paper considers the problem of recognizing eating gestures by tracking wrist motion. Eating gestures can have large variability in motion depending on the subject, utensil, and type of food or beverage being consumed. Previous works have shown viable proofs-of-concept of recognizing eating gestures in laboratory settings with small numbers of subjects and food types, but it is unclear how well these methods would work if tested on a larger population in natural settings. As more subjects, locations and foods are tested, a larger amount of motion variability could cause a decrease in recognition accuracy. To explore this issue, this paper describes the collection and annotation of 51,614 eating gestures taken by 269 subjects eating a meal in a cafeteria. Experiments are described that explore the complexity of hidden Markov models (HMMs) and the amount of training data needed to adequately capture the motion variability across this large data set. Results found that HMMs needed a complexity of 13 states and 5 Gaussians to reach a plateau in accuracy, signifying that a minimum of 65 samples per gesture type are needed. Results also found that 500 training samples per gesture type were needed to identify the point of diminishing returns in recognition accuracy. Overall, the findings provide evidence that the size a data set typically used to demonstrate a laboratory proofs-of-concept may not be sufficiently large enough to capture all the motion variability that could be expected in transitioning to deployment with a larger population. Our data set, which is 1-2 orders of magnitude larger than all data sets tested in previous works, is being made publicly available.
Mining Point Cloud Local Structures by Kernel Correlation and Graph Pooling
Apr 03, 2018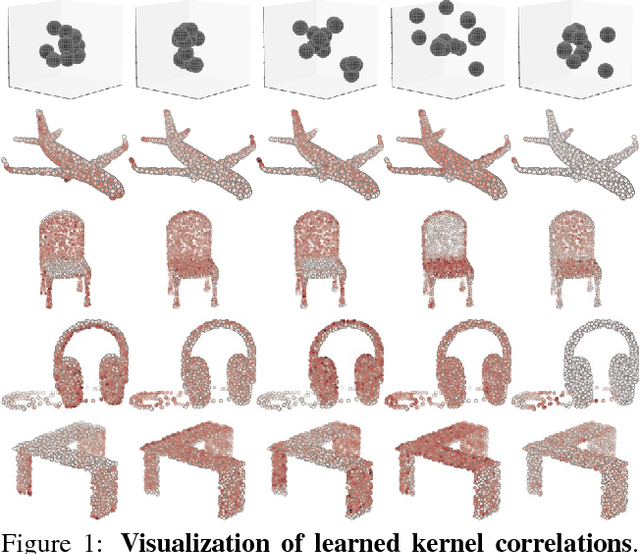
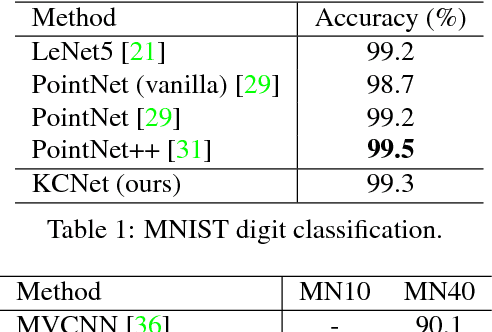
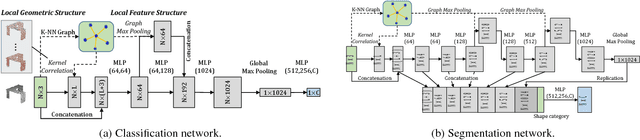
Unlike on images, semantic learning on 3D point clouds using a deep network is challenging due to the naturally unordered data structure. Among existing works, PointNet has achieved promising results by directly learning on point sets. However, it does not take full advantage of a point's local neighborhood that contains fine-grained structural information which turns out to be helpful towards better semantic learning. In this regard, we present two new operations to improve PointNet with a more efficient exploitation of local structures. The first one focuses on local 3D geometric structures. In analogy to a convolution kernel for images, we define a point-set kernel as a set of learnable 3D points that jointly respond to a set of neighboring data points according to their geometric affinities measured by kernel correlation, adapted from a similar technique for point cloud registration. The second one exploits local high-dimensional feature structures by recursive feature aggregation on a nearest-neighbor-graph computed from 3D positions. Experiments show that our network can efficiently capture local information and robustly achieve better performances on major datasets. Our code is available at http://www.merl.com/research/license#KCNet
FoldingNet: Point Cloud Auto-encoder via Deep Grid Deformation
Apr 03, 2018



Recent deep networks that directly handle points in a point set, e.g., PointNet, have been state-of-the-art for supervised learning tasks on point clouds such as classification and segmentation. In this work, a novel end-to-end deep auto-encoder is proposed to address unsupervised learning challenges on point clouds. On the encoder side, a graph-based enhancement is enforced to promote local structures on top of PointNet. Then, a novel folding-based decoder deforms a canonical 2D grid onto the underlying 3D object surface of a point cloud, achieving low reconstruction errors even for objects with delicate structures. The proposed decoder only uses about 7% parameters of a decoder with fully-connected neural networks, yet leads to a more discriminative representation that achieves higher linear SVM classification accuracy than the benchmark. In addition, the proposed decoder structure is shown, in theory, to be a generic architecture that is able to reconstruct an arbitrary point cloud from a 2D grid. Our code is available at http://www.merl.com/research/license#FoldingNet