 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen Stamped Parts Dataset
Mar 19, 2024



We present the Open Stamped Parts Dataset (OSPD), featuring synthetic and real images of stamped metal sheets for auto manufacturing. The real part images, captured from 7 cameras, consist of 7,980 unlabeled images and 1,680 labeled images. In addition, we have compiled a defect dataset by overlaying synthetically generated masks on 10% of the holes. The synthetic dataset replicates the real manufacturing environment in terms of lighting and part placement relative to the cameras. The synthetic data includes 7,980 training images, 1,680 validation images and 1,680 test images, each with bounding box and segmentation mask annotations around all holes. 10% of the holes in the synthetic data mimic defects generated in the real image dataset. We trained a hole-detection model on the synthetic-OSPD, achieving a modified recall score of 67.2% and a precision of 94.4% . We anticipate researchers in the auto manufacturing and broader machine learning and computer vision communities using OSPD to advance the state of the art in defect detection of stamped holes in the metalsheet stamping process. The dataset is available for download at: https://tinyurl.com/hm6xatd7
Benefits of temporal information for appearance-based gaze estimation
May 24, 2020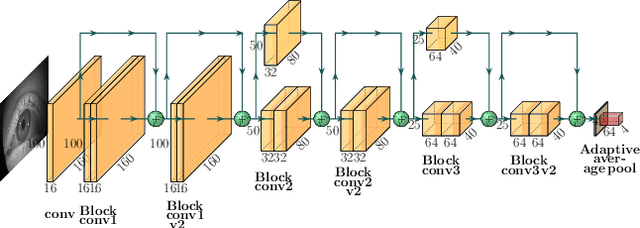
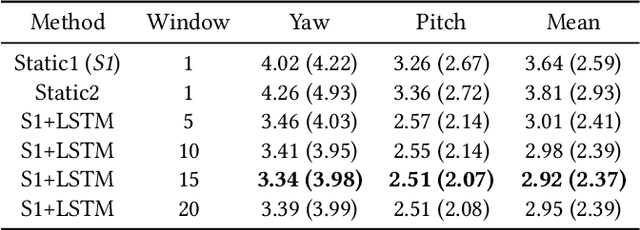
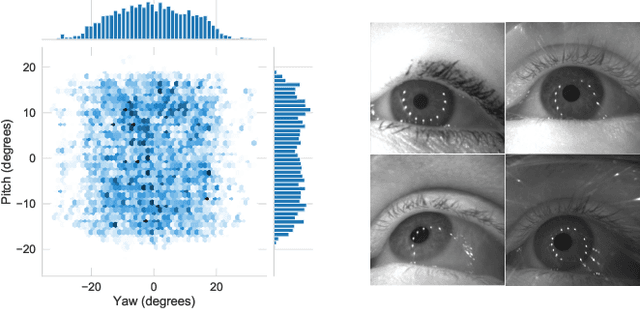
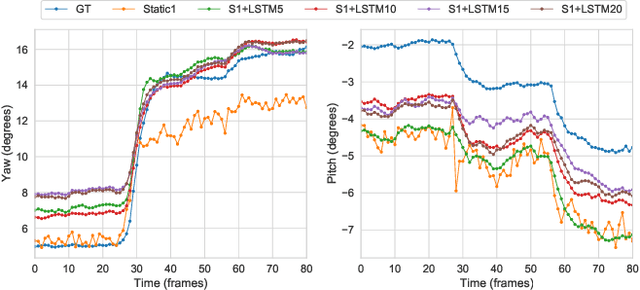
State-of-the-art appearance-based gaze estimation methods, usually based on deep learning techniques, mainly rely on static features. However, temporal trace of eye gaze contains useful information for estimating a given gaze point. For example, approaches leveraging sequential eye gaze information when applied to remote or low-resolution image scenarios with off-the-shelf cameras are showing promising results. The magnitude of contribution from temporal gaze trace is yet unclear for higher resolution/frame rate imaging systems, in which more detailed information about an eye is captured. In this paper, we investigate whether temporal sequences of eye images, captured using a high-resolution, high-frame rate head-mounted virtual reality system, can be leveraged to enhance the accuracy of an end-to-end appearance-based deep-learning model for gaze estimation. Performance is compared against a static-only version of the model. Results demonstrate statistically-significant benefits of temporal information, particularly for the vertical component of gaze.
OpenEDS2020: Open Eyes Dataset
May 08, 2020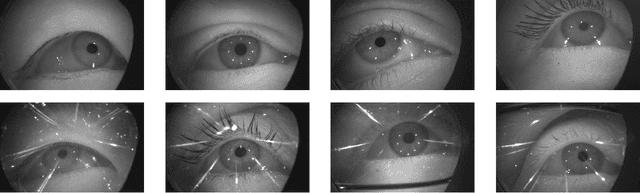

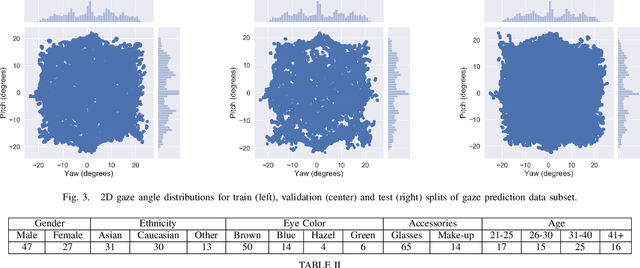
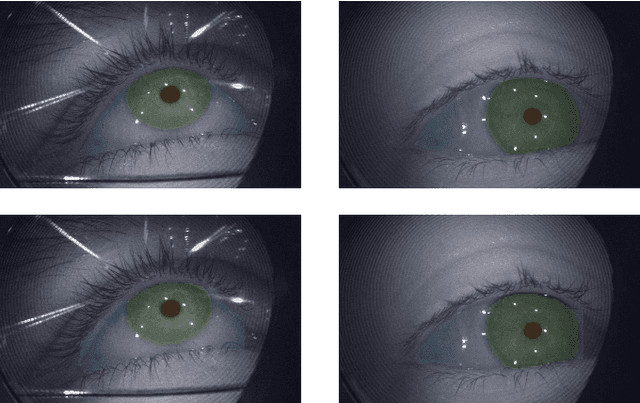
We present the second edition of OpenEDS dataset, OpenEDS2020, a novel dataset of eye-image sequences captured at a frame rate of 100 Hz under controlled illumination, using a virtual-reality head-mounted display mounted with two synchronized eye-facing cameras. The dataset, which is anonymized to remove any personally identifiable information on participants, consists of 80 participants of varied appearance performing several gaze-elicited tasks, and is divided in two subsets: 1) Gaze Prediction Dataset, with up to 66,560 sequences containing 550,400 eye-images and respective gaze vectors, created to foster research in spatio-temporal gaze estimation and prediction approaches; and 2) Eye Segmentation Dataset, consisting of 200 sequences sampled at 5 Hz, with up to 29,500 images, of which 5% contain a semantic segmentation label, devised to encourage the use of temporal information to propagate labels to contiguous frames. Baseline experiments have been evaluated on OpenEDS2020, one for each task, with average angular error of 5.37 degrees when performing gaze prediction on 1 to 5 frames into the future, and a mean intersection over union score of 84.1% for semantic segmentation. As its predecessor, OpenEDS dataset, we anticipate that this new dataset will continue creating opportunities to researchers in eye tracking, machine learning and computer vision communities, to advance the state of the art for virtual reality applications. The dataset is available for download upon request at http://research.fb.com/programs/openeds-2020-challenge/.
OpenEDS: Open Eye Dataset
May 17, 2019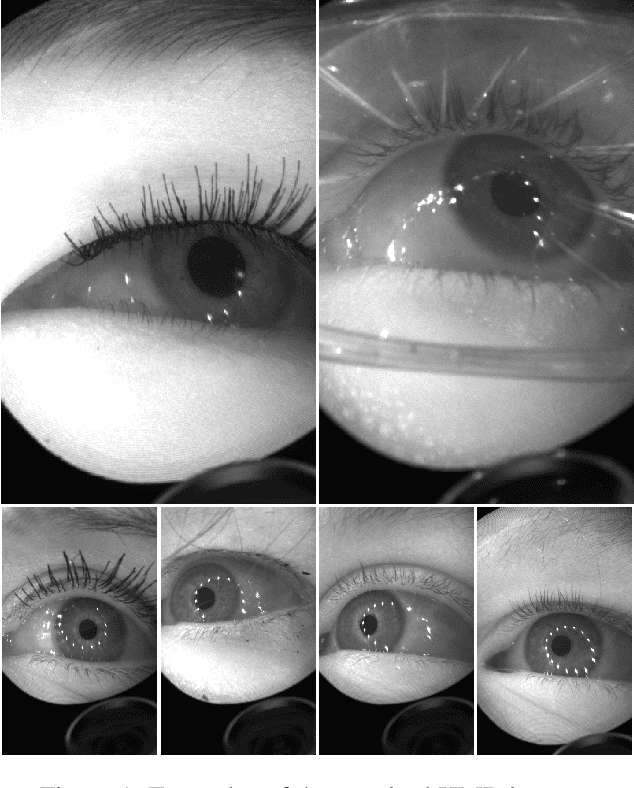

We present a large scale data set, OpenEDS: Open Eye Dataset, of eye-images captured using a virtual-reality (VR) head mounted display mounted with two synchronized eyefacing cameras at a frame rate of 200 Hz under controlled illumination. This dataset is compiled from video capture of the eye-region collected from 152 individual participants and is divided into four subsets: (i) 12,759 images with pixel-level annotations for key eye-regions: iris, pupil and sclera (ii) 252,690 unlabelled eye-images, (iii) 91,200 frames from randomly selected video sequence of 1.5 seconds in duration and (iv) 143 pairs of left and right point cloud data compiled from corneal topography of eye regions collected from a subset, 143 out of 152, participants in the study. A baseline experiment has been evaluated on OpenEDS for the task of semantic segmentation of pupil, iris, sclera and background, with the mean intersectionover-union (mIoU) of 98.3 %. We anticipate that OpenEDS will create opportunities to researchers in the eye tracking community and the broader machine learning and computer vision community to advance the state of eye-tracking for VR applications. The dataset is available for download upon request at https://research.fb.com/programs/openeds-challenge
Deep Recurrent Neural Networks for seizure detection and early seizure detection systems
Jun 10, 2017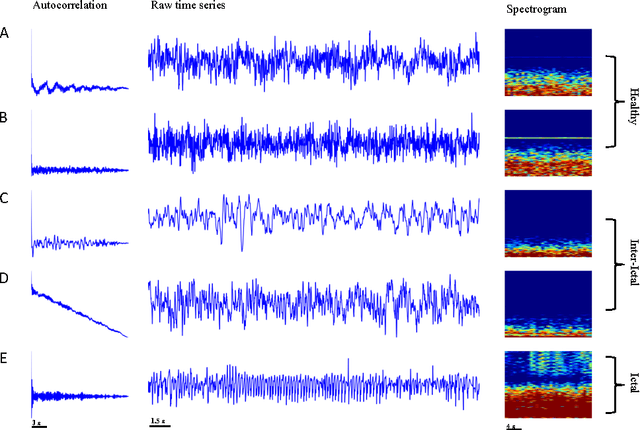
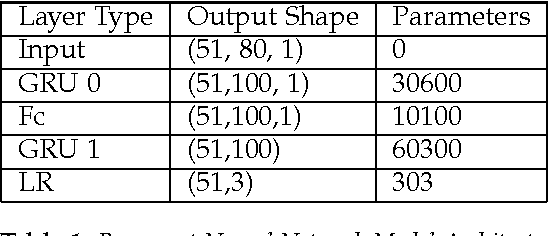
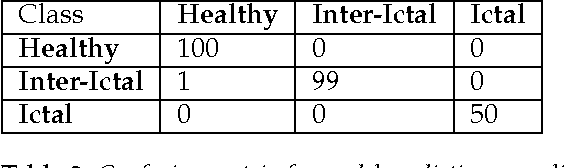
Epilepsy is common neurological diseases, affecting about 0.6-0.8 % of world population. Epileptic patients suffer from chronic unprovoked seizures, which can result in broad spectrum of debilitating medical and social consequences. Since seizures, in general, occur infrequently and are unpredictable, automated seizure detection systems are recommended to screen for seizures during long-term electroencephalogram (EEG) recordings. In addition, systems for early seizure detection can lead to the development of new types of intervention systems that are designed to control or shorten the duration of seizure events. In this article, we investigate the utility of recurrent neural networks (RNNs) in designing seizure detection and early seizure detection systems. We propose a deep learning framework via the use of Gated Recurrent Unit (GRU) RNNs for seizure detection. We use publicly available data in order to evaluate our method and demonstrate very promising evaluation results with overall accuracy close to 100 %. We also systematically investigate the application of our method for early seizure warning systems. Our method can detect about 98% of seizure events within the first 5 seconds of the overall epileptic seizure duration.
Overcoming Challenges in Fixed Point Training of Deep Convolutional Networks
Jul 08, 2016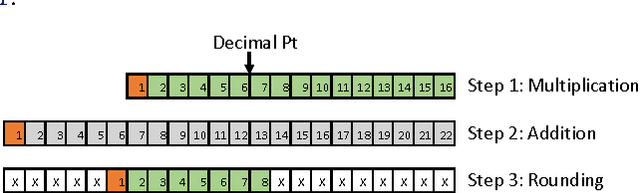
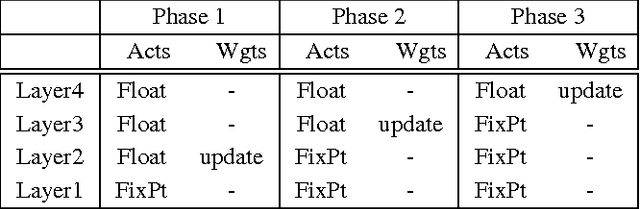
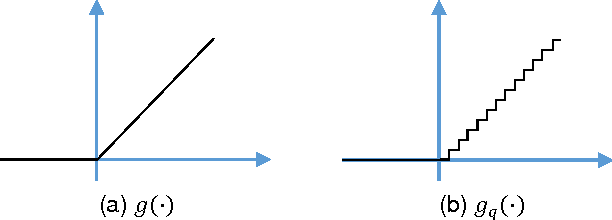
It is known that training deep neural networks, in particular, deep convolutional networks, with aggressively reduced numerical precision is challenging. The stochastic gradient descent algorithm becomes unstable in the presence of noisy gradient updates resulting from arithmetic with limited numeric precision. One of the well-accepted solutions facilitating the training of low precision fixed point networks is stochastic rounding. However, to the best of our knowledge, the source of the instability in training neural networks with noisy gradient updates has not been well investigated. This work is an attempt to draw a theoretical connection between low numerical precision and training algorithm stability. In doing so, we will also propose and verify through experiments methods that are able to improve the training performance of deep convolutional networks in fixed point.
Improving performance of recurrent neural network with relu nonlinearity
Jun 23, 2016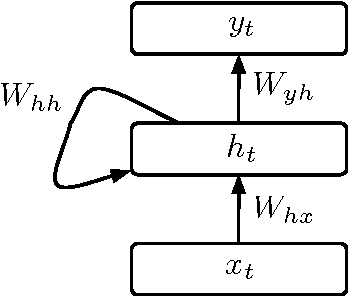

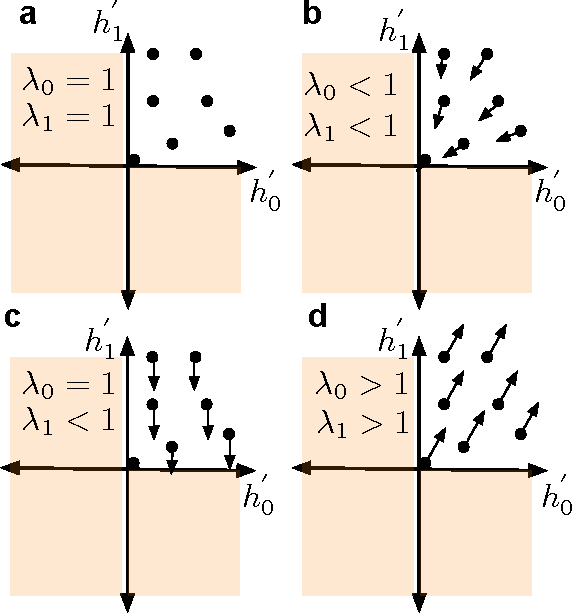
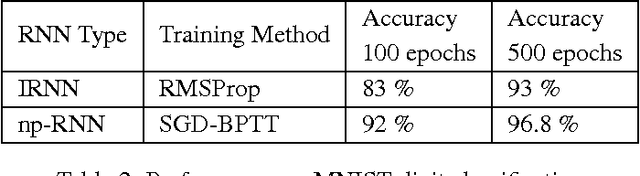
In recent years significant progress has been made in successfully training recurrent neural networks (RNNs) on sequence learning problems involving long range temporal dependencies. The progress has been made on three fronts: (a) Algorithmic improvements involving sophisticated optimization techniques, (b) network design involving complex hidden layer nodes and specialized recurrent layer connections and (c) weight initialization methods. In this paper, we focus on recently proposed weight initialization with identity matrix for the recurrent weights in a RNN. This initialization is specifically proposed for hidden nodes with Rectified Linear Unit (ReLU) non linearity. We offer a simple dynamical systems perspective on weight initialization process, which allows us to propose a modified weight initialization strategy. We show that this initialization technique leads to successfully training RNNs composed of ReLUs. We demonstrate that our proposal produces comparable or better solution for three toy problems involving long range temporal structure: the addition problem, the multiplication problem and the MNIST classification problem using sequence of pixels. In addition, we present results for a benchmark action recognition problem.
Fixed Point Quantization of Deep Convolutional Networks
Jun 02, 2016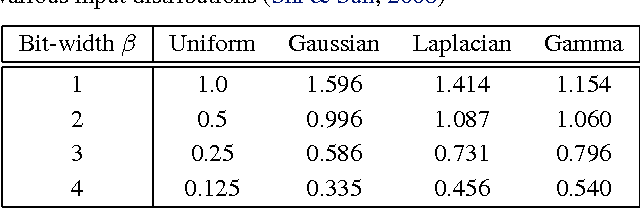
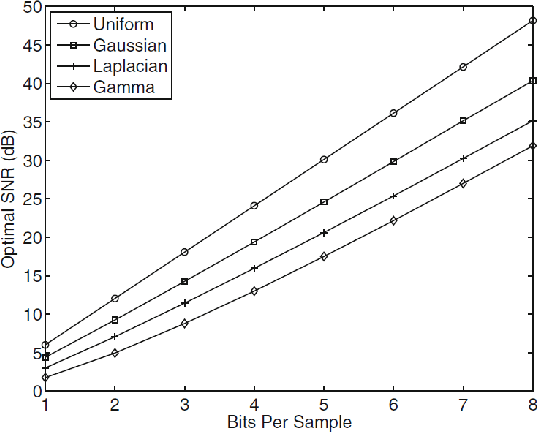
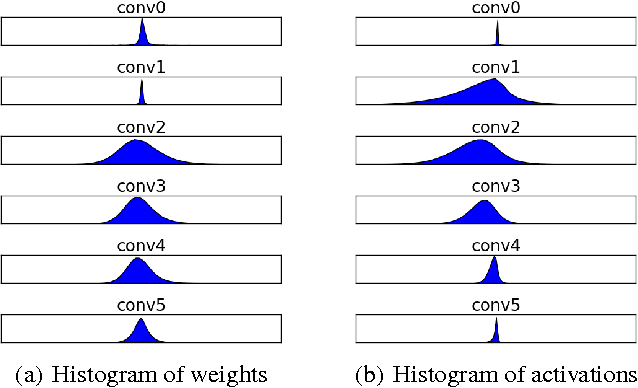
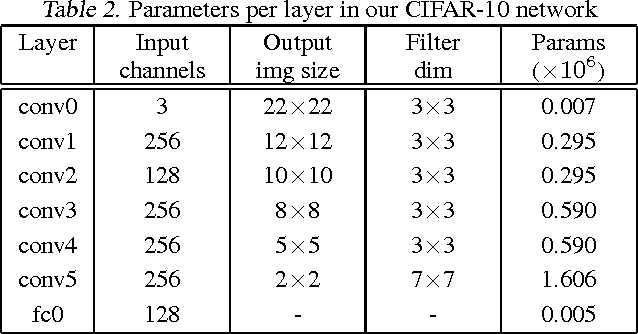
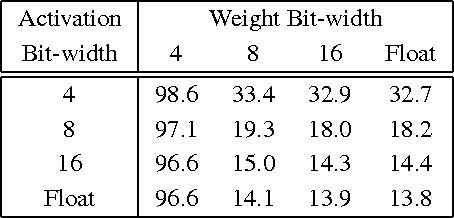
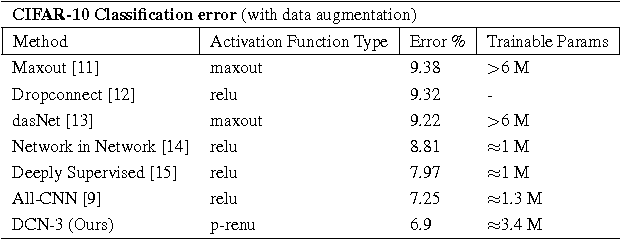
In recent years increasingly complex architectures for deep convolution networks (DCNs) have been proposed to boost the performance on image recognition tasks. However, the gains in performance have come at a cost of substantial increase in computation and model storage resources. Fixed point implementation of DCNs has the potential to alleviate some of these complexities and facilitate potential deployment on embedded hardware. In this paper, we propose a quantizer design for fixed point implementation of DCNs. We formulate and solve an optimization problem to identify optimal fixed point bit-width allocation across DCN layers. Our experiments show that in comparison to equal bit-width settings, the fixed point DCNs with optimized bit width allocation offer >20% reduction in the model size without any loss in accuracy on CIFAR-10 benchmark. We also demonstrate that fine-tuning can further enhance the accuracy of fixed point DCNs beyond that of the original floating point model. In doing so, we report a new state-of-the-art fixed point performance of 6.78% error-rate on CIFAR-10 benchmark.
Hyper-parameter optimization of Deep Convolutional Networks for object recognition
May 17, 2015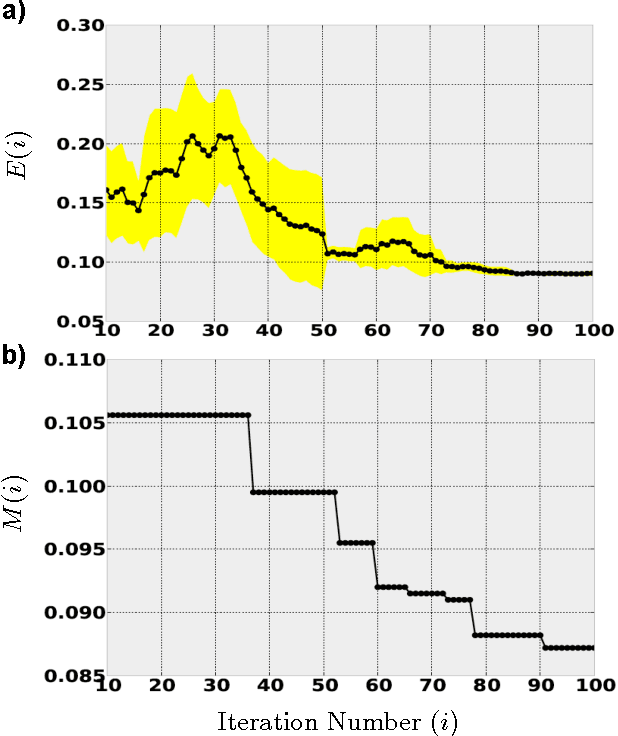
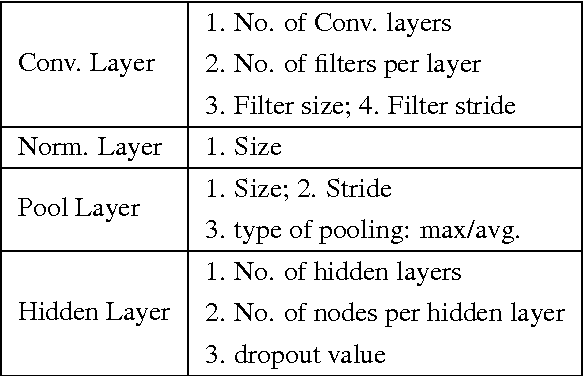
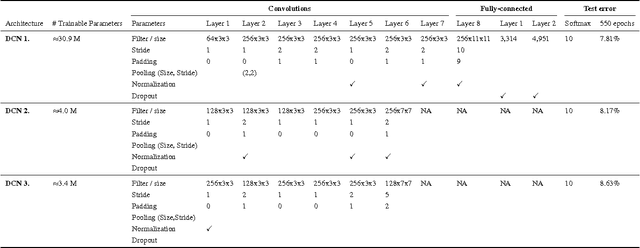
Recently sequential model based optimization (SMBO) has emerged as a promising hyper-parameter optimization strategy in machine learning. In this work, we investigate SMBO to identify architecture hyper-parameters of deep convolution networks (DCNs) object recognition. We propose a simple SMBO strategy that starts from a set of random initial DCN architectures to generate new architectures, which on training perform well on a given dataset. Using the proposed SMBO strategy we are able to identify a number of DCN architectures that produce results that are comparable to state-of-the-art results on object recognition benchmarks.
Fast SVM training using approximate extreme points
Apr 04, 2013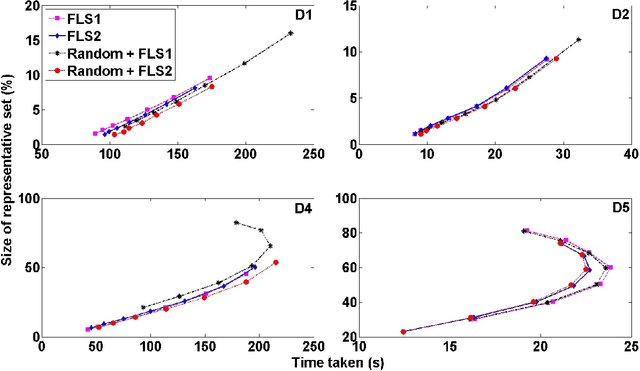
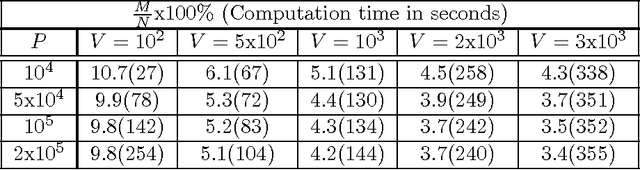
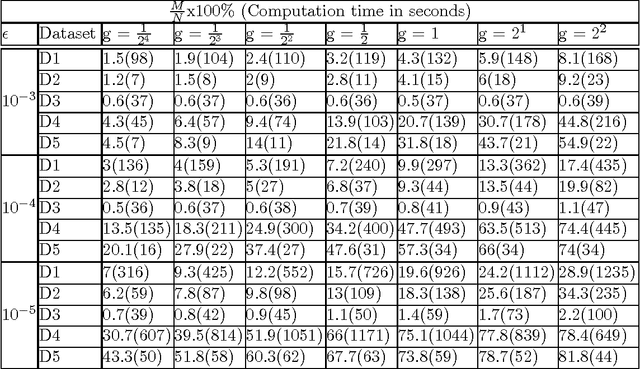
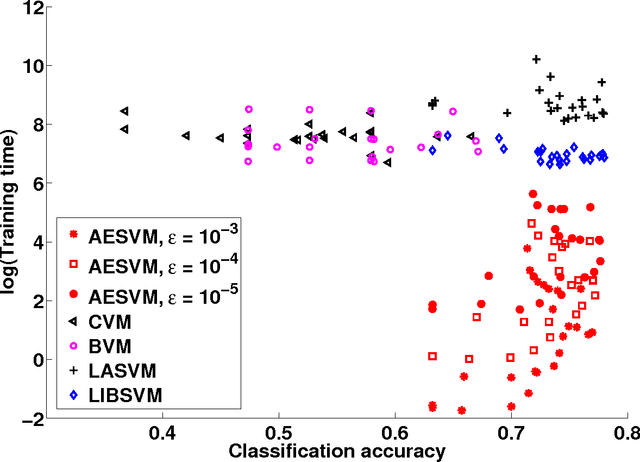
Applications of non-linear kernel Support Vector Machines (SVMs) to large datasets is seriously hampered by its excessive training time. We propose a modification, called the approximate extreme points support vector machine (AESVM), that is aimed at overcoming this burden. Our approach relies on conducting the SVM optimization over a carefully selected subset, called the representative set, of the training dataset. We present analytical results that indicate the similarity of AESVM and SVM solutions. A linear time algorithm based on convex hulls and extreme points is used to compute the representative set in kernel space. Extensive computational experiments on nine datasets compared AESVM to LIBSVM \citep{LIBSVM}, CVM \citep{Tsang05}, BVM \citep{Tsang07}, LASVM \citep{Bordes05}, $\text{SVM}^{\text{perf}}$ \citep{Joachims09}, and the random features method \citep{rahimi07}. Our AESVM implementation was found to train much faster than the other methods, while its classification accuracy was similar to that of LIBSVM in all cases. In particular, for a seizure detection dataset, AESVM training was almost $10^3$ times faster than LIBSVM and LASVM and more than forty times faster than CVM and BVM. Additionally, AESVM also gave competitively fast classification times.