 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Jun 11, 2025A major challenge for modern AI is to learn to understand the world and learn to act largely by observation. This paper explores a self-supervised approach that combines internet-scale video data with a small amount of interaction data (robot trajectories), to develop models capable of understanding, predicting, and planning in the physical world. We first pre-train an action-free joint-embedding-predictive architecture, V-JEPA 2, on a video and image dataset comprising over 1 million hours of internet video. V-JEPA 2 achieves strong performance on motion understanding (77.3 top-1 accuracy on Something-Something v2) and state-of-the-art performance on human action anticipation (39.7 recall-at-5 on Epic-Kitchens-100) surpassing previous task-specific models. Additionally, after aligning V-JEPA 2 with a large language model, we demonstrate state-of-the-art performance on multiple video question-answering tasks at the 8 billion parameter scale (e.g., 84.0 on PerceptionTest, 76.9 on TempCompass). Finally, we show how self-supervised learning can be applied to robotic planning tasks by post-training a latent action-conditioned world model, V-JEPA 2-AC, using less than 62 hours of unlabeled robot videos from the Droid dataset. We deploy V-JEPA 2-AC zero-shot on Franka arms in two different labs and enable picking and placing of objects using planning with image goals. Notably, this is achieved without collecting any data from the robots in these environments, and without any task-specific training or reward. This work demonstrates how self-supervised learning from web-scale data and a small amount of robot interaction data can yield a world model capable of planning in the physical world.
Fairy: Fast Parallelized Instruction-Guided Video-to-Video Synthesis
Dec 20, 2023



In this paper, we introduce Fairy, a minimalist yet robust adaptation of image-editing diffusion models, enhancing them for video editing applications. Our approach centers on the concept of anchor-based cross-frame attention, a mechanism that implicitly propagates diffusion features across frames, ensuring superior temporal coherence and high-fidelity synthesis. Fairy not only addresses limitations of previous models, including memory and processing speed. It also improves temporal consistency through a unique data augmentation strategy. This strategy renders the model equivariant to affine transformations in both source and target images. Remarkably efficient, Fairy generates 120-frame 512x384 videos (4-second duration at 30 FPS) in just 14 seconds, outpacing prior works by at least 44x. A comprehensive user study, involving 1000 generated samples, confirms that our approach delivers superior quality, decisively outperforming established methods.
OpenEDS2020: Open Eyes Dataset
May 08, 2020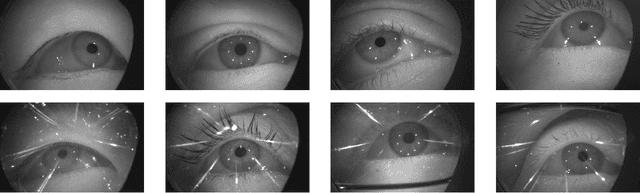

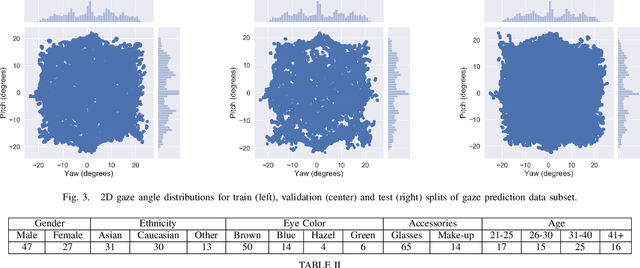
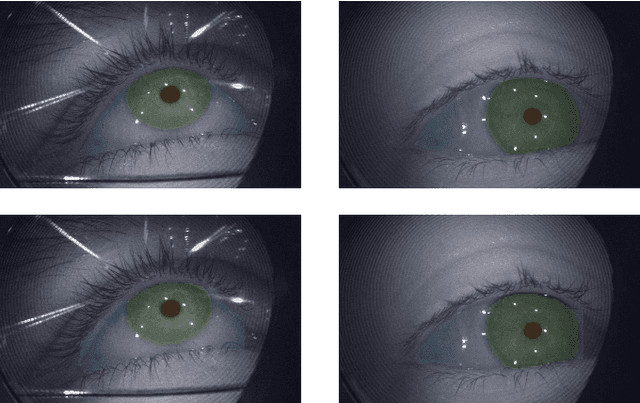
We present the second edition of OpenEDS dataset, OpenEDS2020, a novel dataset of eye-image sequences captured at a frame rate of 100 Hz under controlled illumination, using a virtual-reality head-mounted display mounted with two synchronized eye-facing cameras. The dataset, which is anonymized to remove any personally identifiable information on participants, consists of 80 participants of varied appearance performing several gaze-elicited tasks, and is divided in two subsets: 1) Gaze Prediction Dataset, with up to 66,560 sequences containing 550,400 eye-images and respective gaze vectors, created to foster research in spatio-temporal gaze estimation and prediction approaches; and 2) Eye Segmentation Dataset, consisting of 200 sequences sampled at 5 Hz, with up to 29,500 images, of which 5% contain a semantic segmentation label, devised to encourage the use of temporal information to propagate labels to contiguous frames. Baseline experiments have been evaluated on OpenEDS2020, one for each task, with average angular error of 5.37 degrees when performing gaze prediction on 1 to 5 frames into the future, and a mean intersection over union score of 84.1% for semantic segmentation. As its predecessor, OpenEDS dataset, we anticipate that this new dataset will continue creating opportunities to researchers in eye tracking, machine learning and computer vision communities, to advance the state of the art for virtual reality applications. The dataset is available for download upon request at http://research.fb.com/programs/openeds-2020-challenge/.