 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREACT 2026: The Fourth Multiple Appropriate Facial Reaction Generation Challenge: Personalised MAFRG and Appropriate EEG Reaction Prediction
Jun 06, 2026In dyadic interactions, various human facial reactions could be appropriate for responding to each human speaker behaviour. Following the successful organisation of the REACT 2023, 2024 and 2025 challenge series, a body of generative deep learning (DL) models have been developed for the problem of multiple appropriate facial reaction generation (MAFRG). This year, we propose the REACT 2026 challenge encouraging the development and benchmarking of Machine Learning (ML) models that can generate multiple personalised, appropriate, diverse, realistic and synchronised human-style facial reactions expressed by a specific human listener for responding to each given speaker behaviour. As a key of the challenge, we continuously provide challenge participants with MARS dataset introduced by REACT 2025 but additionally provide individual-level Big-Five personality labels and EEG recordings. This introduces a new one-to-many personalised facial reaction generation setting combining human expressive behavioural, affective and neurophysiological signals, which remains largely unexplored in current dyadic interaction modelling. This paper also presents the challenge guidelines and new baselines on the four proposed sub-challenges: Offline generic and personalised MAFRG as well as Online generic and personalised MAFRG, respectively, which are publicly available at https://github.com/reactmultimodalchallenge/baseline_react2026.
Enhancing Personality Recognition by Comparing the Predictive Power of Traits, Facets, and Nuances
Feb 05, 2026Personality is a complex, hierarchical construct typically assessed through item-level questionnaires aggregated into broad trait scores. Personality recognition models aim to infer personality traits from different sources of behavioral data. However, reliance on broad trait scores as ground truth, combined with limited training data, poses challenges for generalization, as similar trait scores can manifest through diverse, context dependent behaviors. In this work, we explore the predictive impact of the more granular hierarchical levels of the Big-Five Personality Model, facets and nuances, to enhance personality recognition from audiovisual interaction data. Using the UDIVA v0.5 dataset, we trained a transformer-based model including cross-modal (audiovisual) and cross-subject (dyad-aware) attention mechanisms. Results show that nuance-level models consistently outperform facet and trait-level models, reducing mean squared error by up to 74% across interaction scenarios.
REACT 2025: the Third Multiple Appropriate Facial Reaction Generation Challenge
May 22, 2025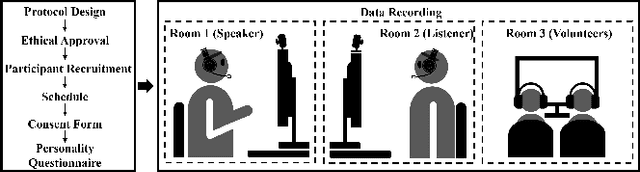

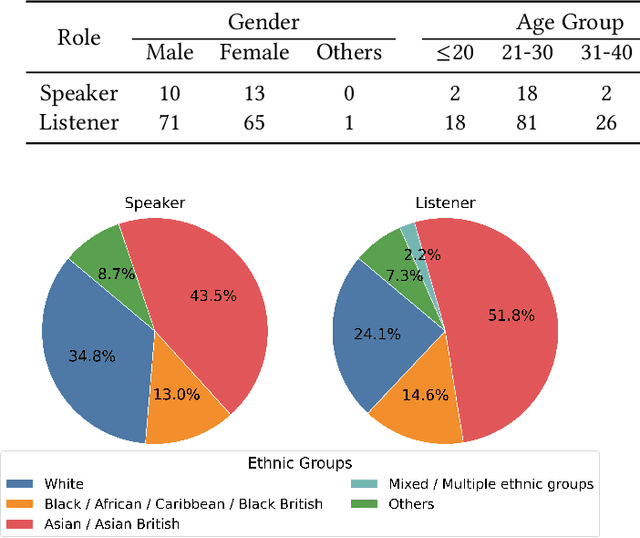
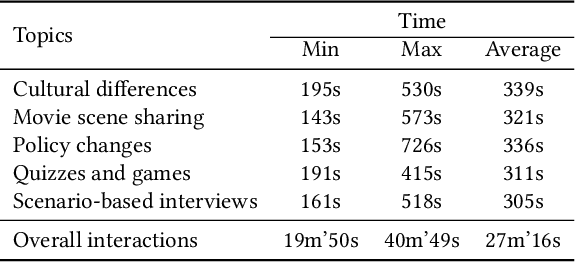
In dyadic interactions, a broad spectrum of human facial reactions might be appropriate for responding to each human speaker behaviour. Following the successful organisation of the REACT 2023 and REACT 2024 challenges, we are proposing the REACT 2025 challenge encouraging the development and benchmarking of Machine Learning (ML) models that can be used to generate multiple appropriate, diverse, realistic and synchronised human-style facial reactions expressed by human listeners in response to an input stimulus (i.e., audio-visual behaviours expressed by their corresponding speakers). As a key of the challenge, we provide challenge participants with the first natural and large-scale multi-modal MAFRG dataset (called MARS) recording 137 human-human dyadic interactions containing a total of 2856 interaction sessions covering five different topics. In addition, this paper also presents the challenge guidelines and the performance of our baselines on the two proposed sub-challenges: Offline MAFRG and Online MAFRG, respectively. The challenge baseline code is publicly available at https://github.com/reactmultimodalchallenge/baseline_react2025
From Sparse Signal to Smooth Motion: Real-Time Motion Generation with Rolling Prediction Models
Apr 07, 2025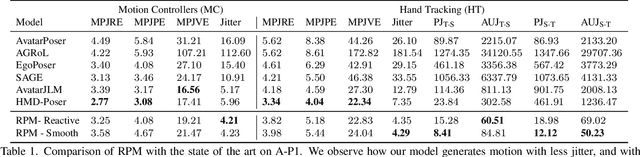
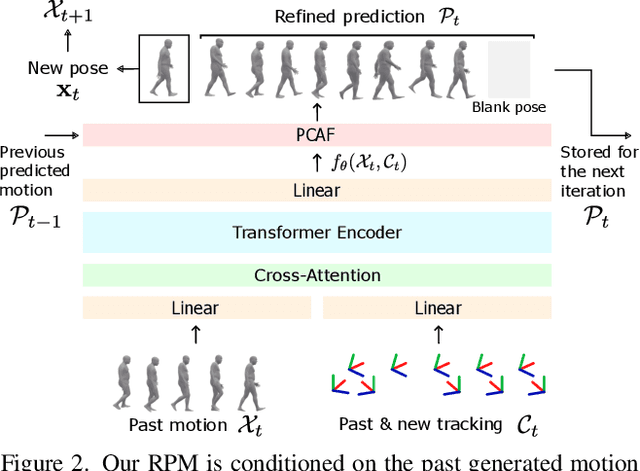
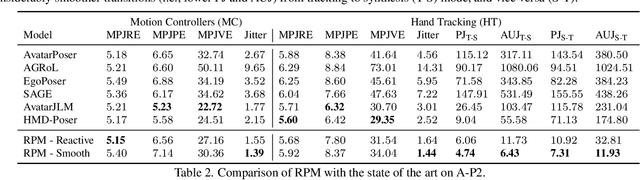
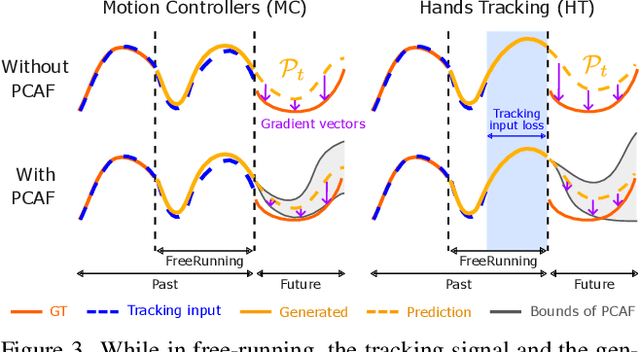
In extended reality (XR), generating full-body motion of the users is important to understand their actions, drive their virtual avatars for social interaction, and convey a realistic sense of presence. While prior works focused on spatially sparse and always-on input signals from motion controllers, many XR applications opt for vision-based hand tracking for reduced user friction and better immersion. Compared to controllers, hand tracking signals are less accurate and can even be missing for an extended period of time. To handle such unreliable inputs, we present Rolling Prediction Model (RPM), an online and real-time approach that generates smooth full-body motion from temporally and spatially sparse input signals. Our model generates 1) accurate motion that matches the inputs (i.e., tracking mode) and 2) plausible motion when inputs are missing (i.e., synthesis mode). More importantly, RPM generates seamless transitions from tracking to synthesis, and vice versa. To demonstrate the practical importance of handling noisy and missing inputs, we present GORP, the first dataset of realistic sparse inputs from a commercial virtual reality (VR) headset with paired high quality body motion ground truth. GORP provides >14 hours of VR gameplay data from 28 people using motion controllers (spatially sparse) and hand tracking (spatially and temporally sparse). We benchmark RPM against the state of the art on both synthetic data and GORP to highlight how we can bridge the gap for real-world applications with a realistic dataset and by handling unreliable input signals. Our code, pretrained models, and GORP dataset are available in the project webpage.
MixerMDM: Learnable Composition of Human Motion Diffusion Models
Apr 01, 2025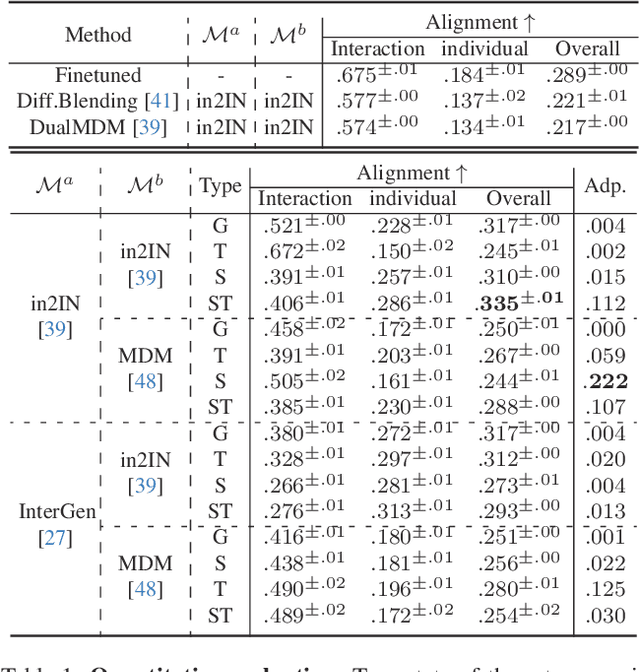
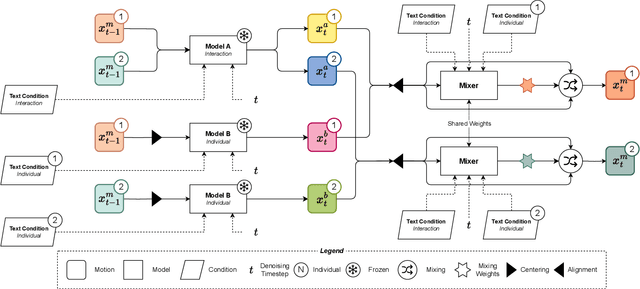
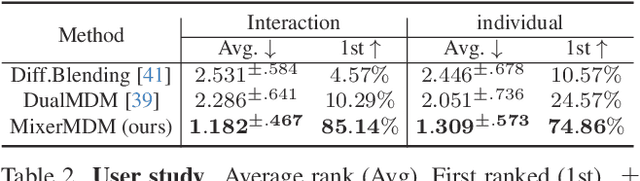
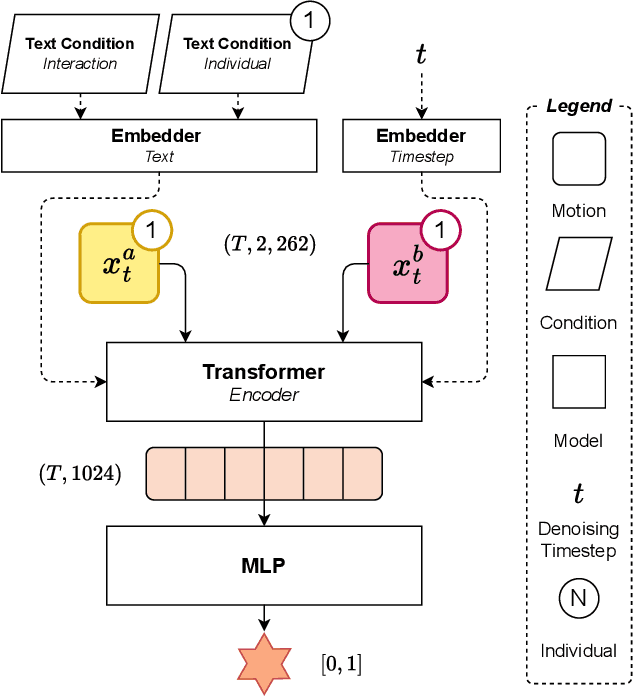
Generating human motion guided by conditions such as textual descriptions is challenging due to the need for datasets with pairs of high-quality motion and their corresponding conditions. The difficulty increases when aiming for finer control in the generation. To that end, prior works have proposed to combine several motion diffusion models pre-trained on datasets with different types of conditions, thus allowing control with multiple conditions. However, the proposed merging strategies overlook that the optimal way to combine the generation processes might depend on the particularities of each pre-trained generative model and also the specific textual descriptions. In this context, we introduce MixerMDM, the first learnable model composition technique for combining pre-trained text-conditioned human motion diffusion models. Unlike previous approaches, MixerMDM provides a dynamic mixing strategy that is trained in an adversarial fashion to learn to combine the denoising process of each model depending on the set of conditions driving the generation. By using MixerMDM to combine single- and multi-person motion diffusion models, we achieve fine-grained control on the dynamics of every person individually, and also on the overall interaction. Furthermore, we propose a new evaluation technique that, for the first time in this task, measures the interaction and individual quality by computing the alignment between the mixed generated motions and their conditions as well as the capabilities of MixerMDM to adapt the mixing throughout the denoising process depending on the motions to mix.
in2IN: Leveraging individual Information to Generate Human INteractions
Apr 15, 2024



Generating human-human motion interactions conditioned on textual descriptions is a very useful application in many areas such as robotics, gaming, animation, and the metaverse. Alongside this utility also comes a great difficulty in modeling the highly dimensional inter-personal dynamics. In addition, properly capturing the intra-personal diversity of interactions has a lot of challenges. Current methods generate interactions with limited diversity of intra-person dynamics due to the limitations of the available datasets and conditioning strategies. For this, we introduce in2IN, a novel diffusion model for human-human motion generation which is conditioned not only on the textual description of the overall interaction but also on the individual descriptions of the actions performed by each person involved in the interaction. To train this model, we use a large language model to extend the InterHuman dataset with individual descriptions. As a result, in2IN achieves state-of-the-art performance in the InterHuman dataset. Furthermore, in order to increase the intra-personal diversity on the existing interaction datasets, we propose DualMDM, a model composition technique that combines the motions generated with in2IN and the motions generated by a single-person motion prior pre-trained on HumanML3D. As a result, DualMDM generates motions with higher individual diversity and improves control over the intra-person dynamics while maintaining inter-personal coherence.
Seamless Human Motion Composition with Blended Positional Encodings
Feb 23, 2024



Conditional human motion generation is an important topic with many applications in virtual reality, gaming, and robotics. While prior works have focused on generating motion guided by text, music, or scenes, these typically result in isolated motions confined to short durations. Instead, we address the generation of long, continuous sequences guided by a series of varying textual descriptions. In this context, we introduce FlowMDM, the first diffusion-based model that generates seamless Human Motion Compositions (HMC) without any postprocessing or redundant denoising steps. For this, we introduce the Blended Positional Encodings, a technique that leverages both absolute and relative positional encodings in the denoising chain. More specifically, global motion coherence is recovered at the absolute stage, whereas smooth and realistic transitions are built at the relative stage. As a result, we achieve state-of-the-art results in terms of accuracy, realism, and smoothness on the Babel and HumanML3D datasets. FlowMDM excels when trained with only a single description per motion sequence thanks to its Pose-Centric Cross-ATtention, which makes it robust against varying text descriptions at inference time. Finally, to address the limitations of existing HMC metrics, we propose two new metrics: the Peak Jerk and the Area Under the Jerk, to detect abrupt transitions.
REACT 2024: the Second Multiple Appropriate Facial Reaction Generation Challenge
Jan 10, 2024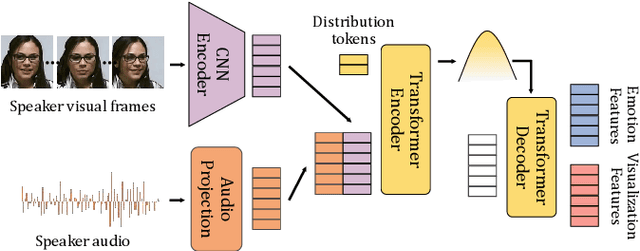
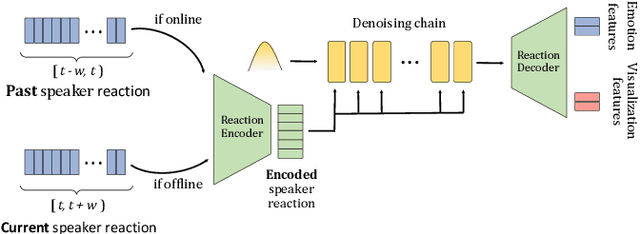
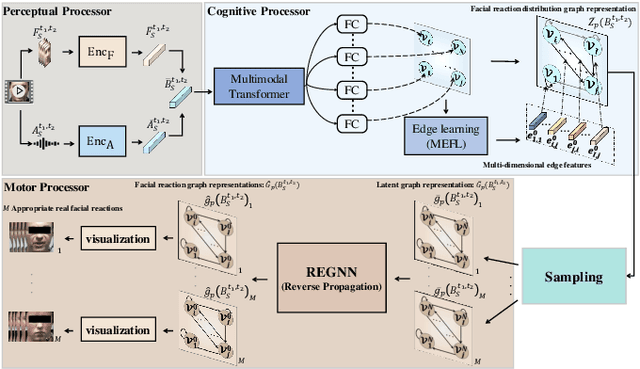
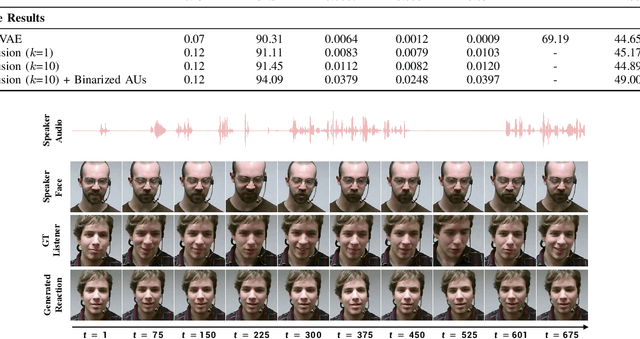
In dyadic interactions, humans communicate their intentions and state of mind using verbal and non-verbal cues, where multiple different facial reactions might be appropriate in response to a specific speaker behaviour. Then, how to develop a machine learning (ML) model that can automatically generate multiple appropriate, diverse, realistic and synchronised human facial reactions from an previously unseen speaker behaviour is a challenging task. Following the successful organisation of the first REACT challenge (REACT 2023), this edition of the challenge (REACT 2024) employs a subset used by the previous challenge, which contains segmented 30-secs dyadic interaction clips originally recorded as part of the NOXI and RECOLA datasets, encouraging participants to develop and benchmark Machine Learning (ML) models that can generate multiple appropriate facial reactions (including facial image sequences and their attributes) given an input conversational partner's stimulus under various dyadic video conference scenarios. This paper presents: (i) the guidelines of the REACT 2024 challenge; (ii) the dataset utilized in the challenge; and (iii) the performance of the baseline systems on the two proposed sub-challenges: Offline Multiple Appropriate Facial Reaction Generation and Online Multiple Appropriate Facial Reaction Generation, respectively. The challenge baseline code is publicly available at https://github.com/reactmultimodalchallenge/baseline_react2024.
Exploring Emotion Expression Recognition in Older Adults Interacting with a Virtual Coach
Nov 09, 2023The EMPATHIC project aimed to design an emotionally expressive virtual coach capable of engaging healthy seniors to improve well-being and promote independent aging. One of the core aspects of the system is its human sensing capabilities, allowing for the perception of emotional states to provide a personalized experience. This paper outlines the development of the emotion expression recognition module of the virtual coach, encompassing data collection, annotation design, and a first methodological approach, all tailored to the project requirements. With the latter, we investigate the role of various modalities, individually and combined, for discrete emotion expression recognition in this context: speech from audio, and facial expressions, gaze, and head dynamics from video. The collected corpus includes users from Spain, France, and Norway, and was annotated separately for the audio and video channels with distinct emotional labels, allowing for a performance comparison across cultures and label types. Results confirm the informative power of the modalities studied for the emotional categories considered, with multimodal methods generally outperforming others (around 68% accuracy with audio labels and 72-74% with video labels). The findings are expected to contribute to the limited literature on emotion recognition applied to older adults in conversational human-machine interaction.
REACT2023: the first Multi-modal Multiple Appropriate Facial Reaction Generation Challenge
Jun 11, 2023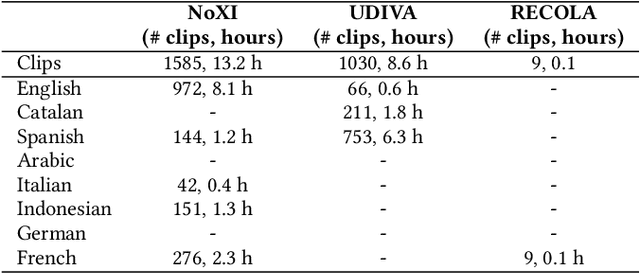
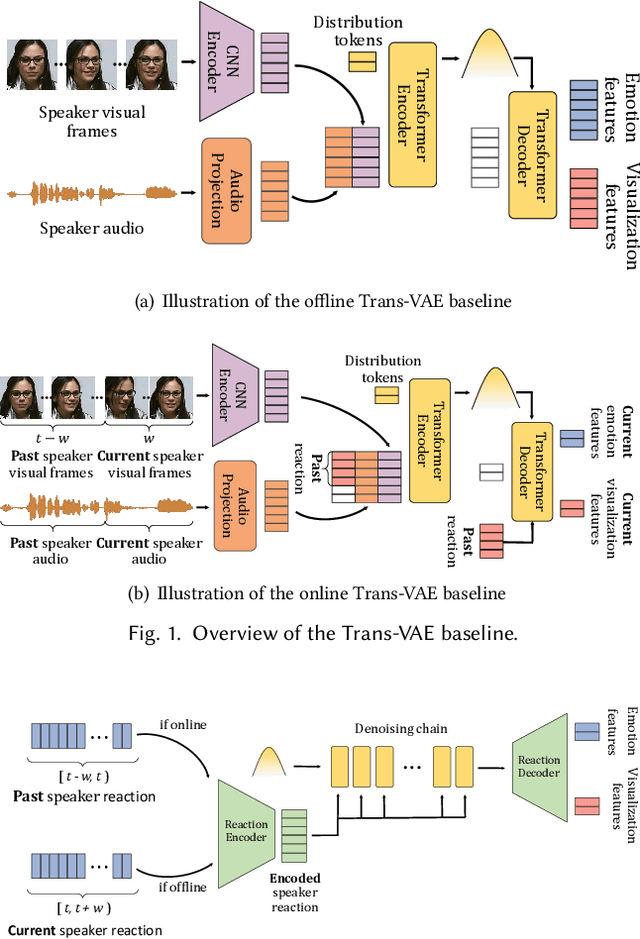
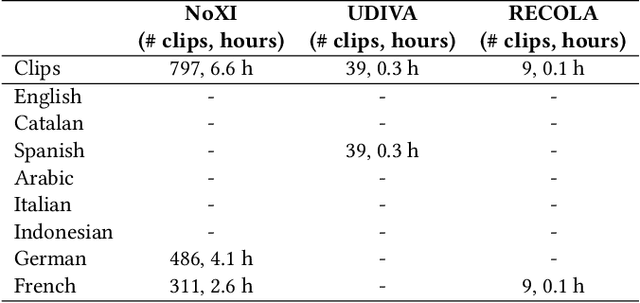
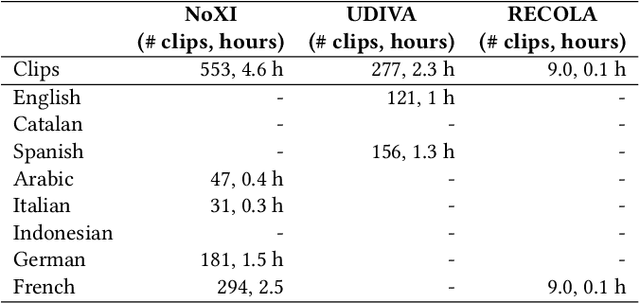
The Multi-modal Multiple Appropriate Facial Reaction Generation Challenge (REACT2023) is the first competition event focused on evaluating multimedia processing and machine learning techniques for generating human-appropriate facial reactions in various dyadic interaction scenarios, with all participants competing strictly under the same conditions. The goal of the challenge is to provide the first benchmark test set for multi-modal information processing and to foster collaboration among the audio, visual, and audio-visual affective computing communities, to compare the relative merits of the approaches to automatic appropriate facial reaction generation under different spontaneous dyadic interaction conditions. This paper presents: (i) novelties, contributions and guidelines of the REACT2023 challenge; (ii) the dataset utilized in the challenge; and (iii) the performance of baseline systems on the two proposed sub-challenges: Offline Multiple Appropriate Facial Reaction Generation and Online Multiple Appropriate Facial Reaction Generation, respectively. The challenge baseline code is publicly available at \url{https://github.com/reactmultimodalchallenge/baseline_react2023}.