 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Self-Supervised Gaze Estimation
Paper and Code
Mar 21, 2022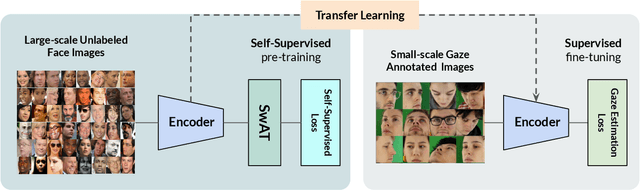

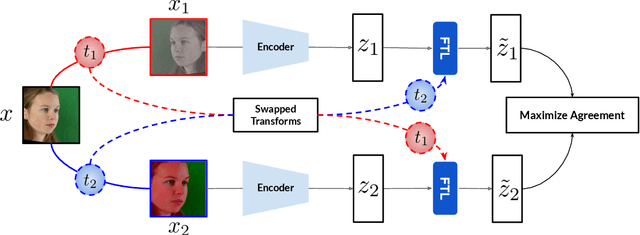
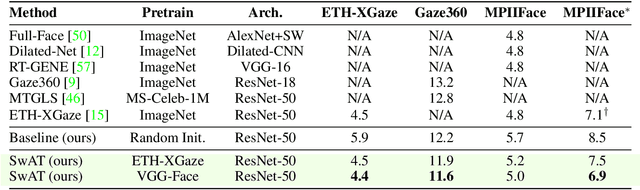
Recent joint embedding-based self-supervised methods have surpassed standard supervised approaches on various image recognition tasks such as image classification. These self-supervised methods aim at maximizing agreement between features extracted from two differently transformed views of the same image, which results in learning an invariant representation with respect to appearance and geometric image transformations. However, the effectiveness of these approaches remains unclear in the context of gaze estimation, a structured regression task that requires equivariance under geometric transformations (e.g., rotations, horizontal flip). In this work, we propose SwAT, an equivariant version of the online clustering-based self-supervised approach SwAV, to learn more informative representations for gaze estimation. We identify the most effective image transformations for self-supervised pretraining and demonstrate that SwAT, with ResNet-50 and supported with uncurated unlabeled face images, outperforms state-of-the-art gaze estimation methods and supervised baselines in various experiments. In particular, we achieve up to 57% and 25% improvements in cross-dataset and within-dataset evaluation tasks on existing benchmarks (ETH-XGaze, Gaze360, and MPIIFaceGaze).