 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Multimodal Complementarity for Single-Frame Action Anticipation
Jan 29, 2026Human action anticipation is commonly treated as a video understanding problem, implicitly assuming that dense temporal information is required to reason about future actions. In this work, we challenge this assumption by investigating what can be achieved when action anticipation is constrained to a single visual observation. We ask a fundamental question: how much information about the future is already encoded in a single frame, and how can it be effectively exploited? Building on our prior work on Action Anticipation at a Glimpse (AAG), we conduct a systematic investigation of single-frame action anticipation enriched with complementary sources of information. We analyze the contribution of RGB appearance, depth-based geometric cues, and semantic representations of past actions, and investigate how different multimodal fusion strategies, keyframe selection policies and past-action history sources influence anticipation performance. Guided by these findings, we consolidate the most effective design choices into AAG+, a refined single-frame anticipation framework. Despite operating on a single frame, AAG+ consistently improves upon the original AAG and achieves performance comparable to, or exceeding, that of state-of-the-art video-based methods on challenging anticipation benchmarks including IKEA-ASM, Meccano and Assembly101. Our results offer new insights into the limits and potential of single-frame action anticipation, and clarify when dense temporal modeling is necessary and when a carefully selected glimpse is sufficient.
Visual WetlandBirds Dataset: Bird Species Identification and Behavior Recognition in Videos
Jan 15, 2025



The current biodiversity loss crisis makes animal monitoring a relevant field of study. In light of this, data collected through monitoring can provide essential insights, and information for decision-making aimed at preserving global biodiversity. Despite the importance of such data, there is a notable scarcity of datasets featuring videos of birds, and none of the existing datasets offer detailed annotations of bird behaviors in video format. In response to this gap, our study introduces the first fine-grained video dataset specifically designed for bird behavior detection and species classification. This dataset addresses the need for comprehensive bird video datasets and provides detailed data on bird actions, facilitating the development of deep learning models to recognize these, similar to the advancements made in human action recognition. The proposed dataset comprises 178 videos recorded in Spanish wetlands, capturing 13 different bird species performing 7 distinct behavior classes. In addition, we also present baseline results using state of the art models on two tasks: bird behavior recognition and species classification.
Detecting Facial Image Manipulations with Multi-Layer CNN Models
Dec 09, 2024



The rapid evolution of digital image manipulation techniques poses significant challenges for content verification, with models such as stable diffusion and mid-journey producing highly realistic, yet synthetic, images that can deceive human perception. This research develops and evaluates convolutional neural networks (CNNs) specifically tailored for the detection of these manipulated images. The study implements a comparative analysis of three progressively complex CNN architectures, assessing their ability to classify and localize manipulations across various facial image modifications. Regularization and optimization techniques were systematically incorporated to improve feature extraction and performance. The results indicate that the proposed models achieve an accuracy of up to 76\% in distinguishing manipulated images from genuine ones, surpassing traditional approaches. This research not only highlights the potential of CNNs in enhancing the robustness of digital media verification tools, but also provides insights into effective architectural adaptations and training strategies for low-computation environments. Future work will build on these findings by extending the architectures to handle more diverse manipulation techniques and integrating multi-modal data for improved detection capabilities.
Enhancing Action Recognition by Leveraging the Hierarchical Structure of Actions and Textual Context
Oct 28, 2024



The sequential execution of actions and their hierarchical structure consisting of different levels of abstraction, provide features that remain unexplored in the task of action recognition. In this study, we present a novel approach to improve action recognition by exploiting the hierarchical organization of actions and by incorporating contextualized textual information, including location and prior actions to reflect the sequential context. To achieve this goal, we introduce a novel transformer architecture tailored for action recognition that utilizes both visual and textual features. Visual features are obtained from RGB and optical flow data, while text embeddings represent contextual information. Furthermore, we define a joint loss function to simultaneously train the model for both coarse and fine-grained action recognition, thereby exploiting the hierarchical nature of actions. To demonstrate the effectiveness of our method, we extend the Toyota Smarthome Untrimmed (TSU) dataset to introduce action hierarchies, introducing the Hierarchical TSU dataset. We also conduct an ablation study to assess the impact of different methods for integrating contextual and hierarchical data on action recognition performance. Results show that the proposed approach outperforms pre-trained SOTA methods when trained with the same hyperparameters. Moreover, they also show a 17.12% improvement in top-1 accuracy over the equivalent fine-grained RGB version when using ground-truth contextual information, and a 5.33% improvement when contextual information is obtained from actual predictions.
Deep Insights into Cognitive Decline: A Survey of Leveraging Non-Intrusive Modalities with Deep Learning Techniques
Oct 24, 2024
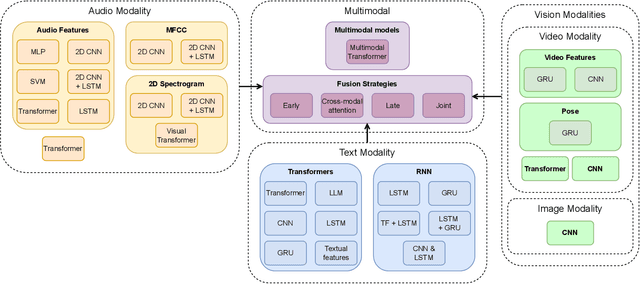
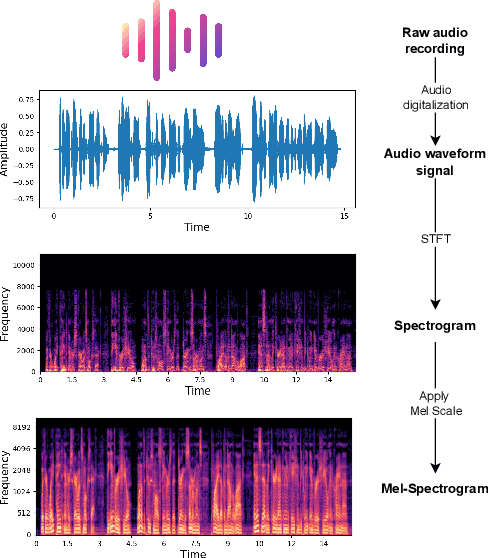
Cognitive decline is a natural part of aging, often resulting in reduced cognitive abilities. In some cases, however, this decline is more pronounced, typically due to disorders such as Alzheimer's disease. Early detection of anomalous cognitive decline is crucial, as it can facilitate timely professional intervention. While medical data can help in this detection, it often involves invasive procedures. An alternative approach is to employ non-intrusive techniques such as speech or handwriting analysis, which do not necessarily affect daily activities. This survey reviews the most relevant methodologies that use deep learning techniques to automate the cognitive decline estimation task, including audio, text, and visual processing. We discuss the key features and advantages of each modality and methodology, including state-of-the-art approaches like Transformer architecture and foundation models. In addition, we present works that integrate different modalities to develop multimodal models. We also highlight the most significant datasets and the quantitative results from studies using these resources. From this review, several conclusions emerge. In most cases, the textual modality achieves the best results and is the most relevant for detecting cognitive decline. Moreover, combining various approaches from individual modalities into a multimodal model consistently enhances performance across nearly all scenarios.
Cognitive Insights Across Languages: Enhancing Multimodal Interview Analysis
Jun 11, 2024Cognitive decline is a natural process that occurs as individuals age. Early diagnosis of anomalous decline is crucial for initiating professional treatment that can enhance the quality of life of those affected. To address this issue, we propose a multimodal model capable of predicting Mild Cognitive Impairment and cognitive scores. The TAUKADIAL dataset is used to conduct the evaluation, which comprises audio recordings of clinical interviews. The proposed model demonstrates the ability to transcribe and differentiate between languages used in the interviews. Subsequently, the model extracts audio and text features, combining them into a multimodal architecture to achieve robust and generalized results. Our approach involves in-depth research to implement various features obtained from the proposed modalities.
in2IN: Leveraging individual Information to Generate Human INteractions
Apr 15, 2024



Generating human-human motion interactions conditioned on textual descriptions is a very useful application in many areas such as robotics, gaming, animation, and the metaverse. Alongside this utility also comes a great difficulty in modeling the highly dimensional inter-personal dynamics. In addition, properly capturing the intra-personal diversity of interactions has a lot of challenges. Current methods generate interactions with limited diversity of intra-person dynamics due to the limitations of the available datasets and conditioning strategies. For this, we introduce in2IN, a novel diffusion model for human-human motion generation which is conditioned not only on the textual description of the overall interaction but also on the individual descriptions of the actions performed by each person involved in the interaction. To train this model, we use a large language model to extend the InterHuman dataset with individual descriptions. As a result, in2IN achieves state-of-the-art performance in the InterHuman dataset. Furthermore, in order to increase the intra-personal diversity on the existing interaction datasets, we propose DualMDM, a model composition technique that combines the motions generated with in2IN and the motions generated by a single-person motion prior pre-trained on HumanML3D. As a result, DualMDM generates motions with higher individual diversity and improves control over the intra-person dynamics while maintaining inter-personal coherence.
Self-supervised Vision Transformers for 3D Pose Estimation of Novel Objects
May 31, 2023



Object pose estimation is important for object manipulation and scene understanding. In order to improve the general applicability of pose estimators, recent research focuses on providing estimates for novel objects, that is objects unseen during training. Such works use deep template matching strategies to retrieve the closest template connected to a query image. This template retrieval implicitly provides object class and pose. Despite the recent success and improvements of Vision Transformers over CNNs for many vision tasks, the state of the art uses CNN-based approaches for novel object pose estimation. This work evaluates and demonstrates the differences between self-supervised CNNs and Vision Transformers for deep template matching. In detail, both types of approaches are trained using contrastive learning to match training images against rendered templates of isolated objects. At test time, such templates are matched against query images of known and novel objects under challenging settings, such as clutter, occlusion and object symmetries, using masked cosine similarity. The presented results not only demonstrate that Vision Transformers improve in matching accuracy over CNNs, but also that for some cases pre-trained Vision Transformers do not need fine-tuning to do so. Furthermore, we highlight the differences in optimization and network architecture when comparing these two types of network for deep template matching.
Exploiting the relationship between visual and textual features in social networks for image classification with zero-shot deep learning
Jul 08, 2021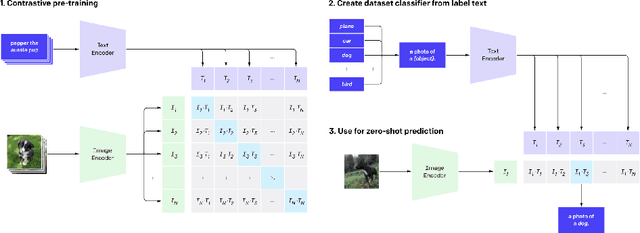



One of the main issues related to unsupervised machine learning is the cost of processing and extracting useful information from large datasets. In this work, we propose a classifier ensemble based on the transferable learning capabilities of the CLIP neural network architecture in multimodal environments (image and text) from social media. For this purpose, we used the InstaNY100K dataset and proposed a validation approach based on sampling techniques. Our experiments, based on image classification tasks according to the labels of the Places dataset, are performed by first considering only the visual part, and then adding the associated texts as support. The results obtained demonstrated that trained neural networks such as CLIP can be successfully applied to image classification with little fine-tuning, and considering the associated texts to the images can help to improve the accuracy depending on the goal. The results demonstrated what seems to be a promising research direction.
UnrealROX+: An Improved Tool for Acquiring Synthetic Data from Virtual 3D Environments
Apr 23, 2021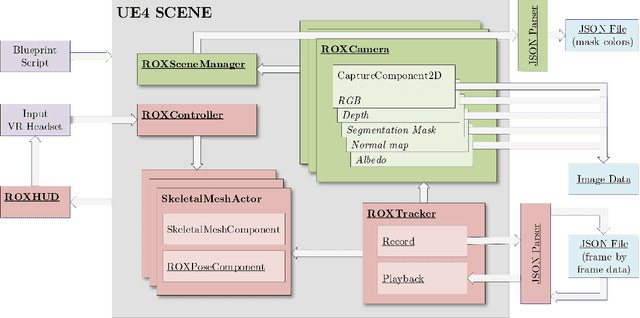



Synthetic data generation has become essential in last years for feeding data-driven algorithms, which surpassed traditional techniques performance in almost every computer vision problem. Gathering and labelling the amount of data needed for these data-hungry models in the real world may become unfeasible and error-prone, while synthetic data give us the possibility of generating huge amounts of data with pixel-perfect annotations. However, most synthetic datasets lack from enough realism in their rendered images. In that context UnrealROX generation tool was presented in 2019, allowing to generate highly realistic data, at high resolutions and framerates, with an efficient pipeline based on Unreal Engine, a cutting-edge videogame engine. UnrealROX enabled robotic vision researchers to generate realistic and visually plausible data with full ground truth for a wide variety of problems such as class and instance semantic segmentation, object detection, depth estimation, visual grasping, and navigation. Nevertheless, its workflow was very tied to generate image sequences from a robotic on-board camera, making hard to generate data for other purposes. In this work, we present UnrealROX+, an improved version of UnrealROX where its decoupled and easy-to-use data acquisition system allows to quickly design and generate data in a much more flexible and customizable way. Moreover, it is packaged as an Unreal plug-in, which makes it more comfortable to use with already existing Unreal projects, and it also includes new features such as generating albedo or a Python API for interacting with the virtual environment from Deep Learning frameworks.