 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOCCAM: Class-Agnostic, Training-Free, Prior-Free and Multi-Class Object Counting
Jan 20, 2026Class-Agnostic object Counting (CAC) involves counting instances of objects from arbitrary classes within an image. Due to its practical importance, CAC has received increasing attention in recent years. Most existing methods assume a single object class per image, rely on extensive training of large deep learning models and address the problem by incorporating additional information, such as visual exemplars or text prompts. In this paper, we present OCCAM, the first training-free approach to CAC that operates without the need of any supplementary information. Moreover, our approach addresses the multi-class variant of the problem, as it is capable of counting the object instances in each and every class among arbitrary object classes within an image. We leverage Segment Anything Model 2 (SAM2), a foundation model, and a custom threshold-based variant of the First Integer Neighbor Clustering Hierarchy (FINCH) algorithm to achieve competitive performance on widely used benchmark datasets, FSC-147 and CARPK. We propose a synthetic multi-class dataset and F1 score as a more suitable evaluation metric. The code for our method and the proposed synthetic dataset will be made publicly available at https://mikespanak.github.io/OCCAM_counter.
Combining facial videos and biosignals for stress estimation during driving
Jan 07, 2026Reliable stress recognition from facial videos is challenging due to stress's subjective nature and voluntary facial control. While most methods rely on Facial Action Units, the role of disentangled 3D facial geometry remains underexplored. We address this by analyzing stress during distracted driving using EMOCA-derived 3D expression and pose coefficients. Paired hypothesis tests between baseline and stressor phases reveal that 41 of 56 coefficients show consistent, phase-specific stress responses comparable to physiological markers. Building on this, we propose a Transformer-based temporal modeling framework and assess unimodal, early-fusion, and cross-modal attention strategies. Cross-Modal Attention fusion of EMOCA and physiological signals achieves best performance (AUROC 92\%, Accuracy 86.7\%), with EMOCA-gaze fusion also competitive (AUROC 91.8\%). This highlights the effectiveness of temporal modeling and cross-modal attention for stress recognition.
Y-MAP-Net: Real-time depth, normals, segmentation, multi-label captioning and 2D human pose in RGB images
Nov 15, 2024



We present Y-MAP-Net, a Y-shaped neural network architecture designed for real-time multi-task learning on RGB images. Y-MAP-Net, simultaneously predicts depth, surface normals, human pose, semantic segmentation and generates multi-label captions, all from a single network evaluation. To achieve this, we adopt a multi-teacher, single-student training paradigm, where task-specific foundation models supervise the network's learning, enabling it to distill their capabilities into a lightweight architecture suitable for real-time applications. Y-MAP-Net, exhibits strong generalization, simplicity and computational efficiency, making it ideal for robotics and other practical scenarios. To support future research, we will release our code publicly.
Multi-view Image-based Hand Geometry Refinement using Differentiable Monte Carlo Ray Tracing
Jul 12, 2021
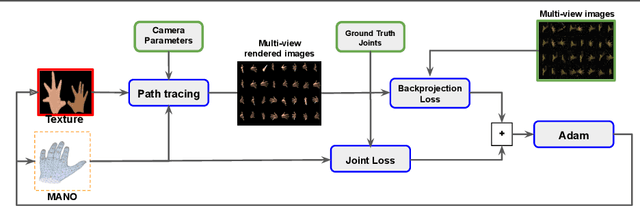
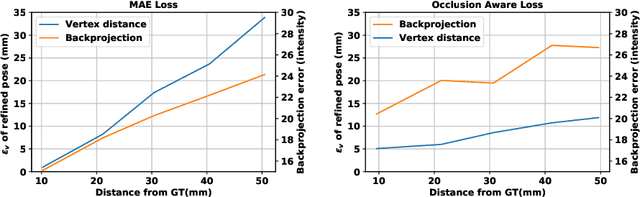
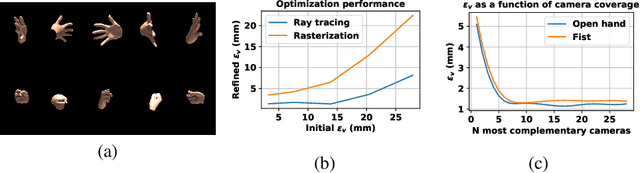
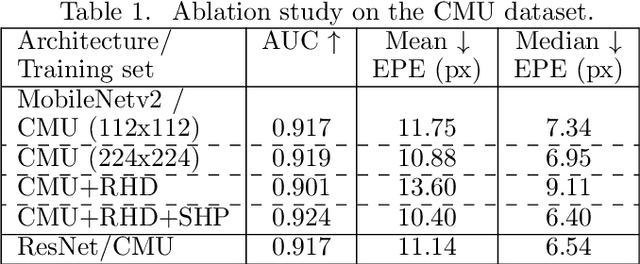
The amount and quality of datasets and tools available in the research field of hand pose and shape estimation act as evidence to the significant progress that has been made. We find that there is still room for improvement in both fronts, and even beyond. Even the datasets of the highest quality, reported to date, have shortcomings in annotation. There are tools in the literature that can assist in that direction and yet they have not been considered, so far. To demonstrate how these gaps can be bridged, we employ such a publicly available, multi-camera dataset of hands (InterHand2.6M), and perform effective image-based refinement to improve on the imperfect ground truth annotations, yielding a better dataset. The image-based refinement is achieved through raytracing, a method that has not been employed so far to relevant problems and is hereby shown to be superior to the approximative alternatives that have been employed in the past. To tackle the lack of reliable ground truth, we resort to realistic synthetic data, to show that the improvement we induce is indeed significant, qualitatively, and quantitatively, too.
Even Faster SNN Simulation with Lazy+Event-driven Plasticity and Shared Atomics
Jul 08, 2021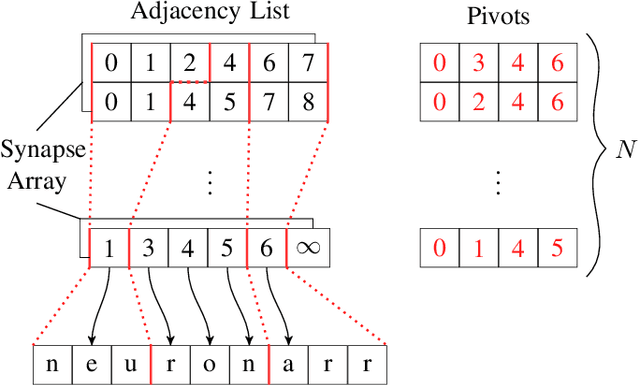


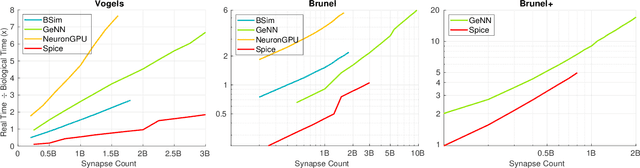
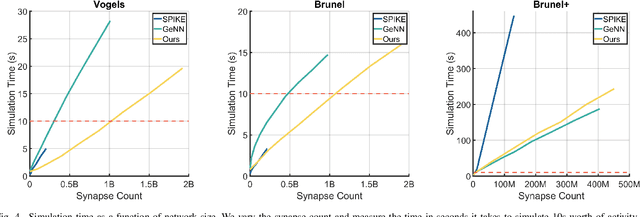
We present two novel optimizations that accelerate clock-based spiking neural network (SNN) simulators. The first one targets spike timing dependent plasticity (STDP). It combines lazy- with event-driven plasticity and efficiently facilitates the computation of pre- and post-synaptic spikes using bitfields and integer intrinsics. It offers higher bandwidth than event-driven plasticity alone and achieves a 1.5x-2x speedup over our closest competitor. The second optimization targets spike delivery. We partition our graph representation in a way that bounds the number of neurons that need be updated at any given time which allows us to perform said update in shared memory instead of global memory. This is 2x-2.5x faster than our closest competitor. Both optimizations represent the final evolutionary stages of years of iteration on STDP and spike delivery inside "Spice" (/spaIk/), our state of the art SNN simulator. The proposed optimizations are not exclusive to our graph representation or pipeline but are applicable to a multitude of simulator designs. We evaluate our performance on three well-established models and compare ourselves against three other state of the art simulators.
H-GAN: the power of GANs in your Hands
Apr 21, 2021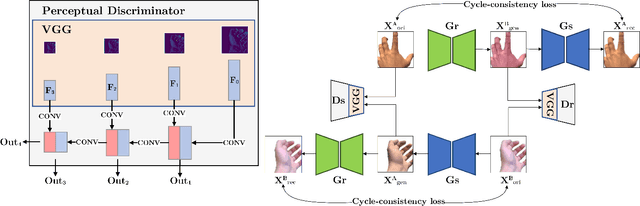
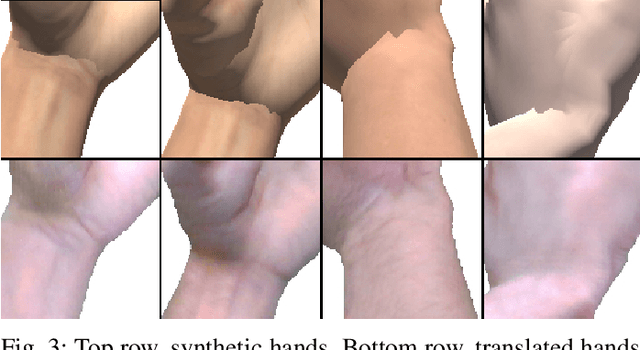
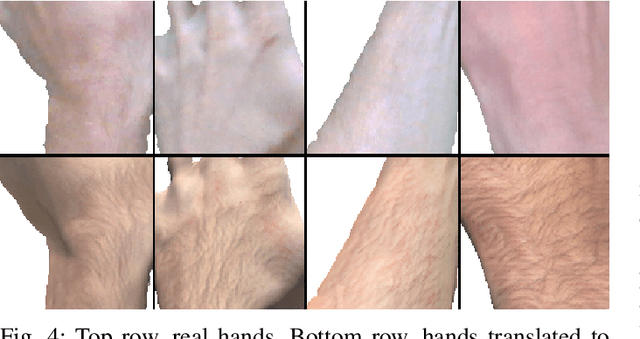
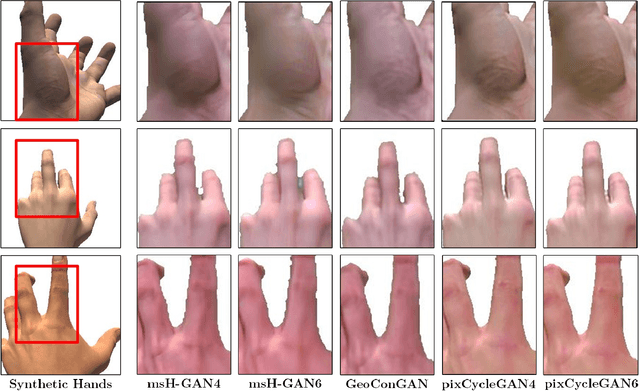
We present HandGAN (H-GAN), a cycle-consistent adversarial learning approach implementing multi-scale perceptual discriminators. It is designed to translate synthetic images of hands to the real domain. Synthetic hands provide complete ground-truth annotations, yet they are not representative of the target distribution of real-world data. We strive to provide the perfect blend of a realistic hand appearance with synthetic annotations. Relying on image-to-image translation, we improve the appearance of synthetic hands to approximate the statistical distribution underlying a collection of real images of hands. H-GAN tackles not only the cross-domain tone mapping but also structural differences in localized areas such as shading discontinuities. Results are evaluated on a qualitative and quantitative basis improving previous works. Furthermore, we relied on the hand classification task to claim our generated hands are statistically similar to the real domain of hands.
Multi-GPU SNN Simulation with Perfect Static Load Balancing
Feb 09, 2021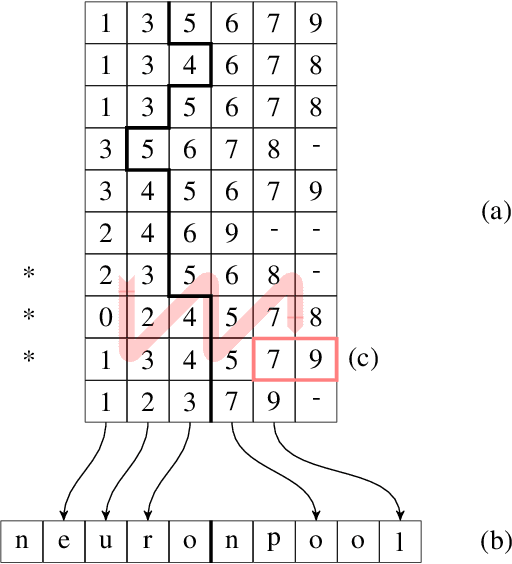
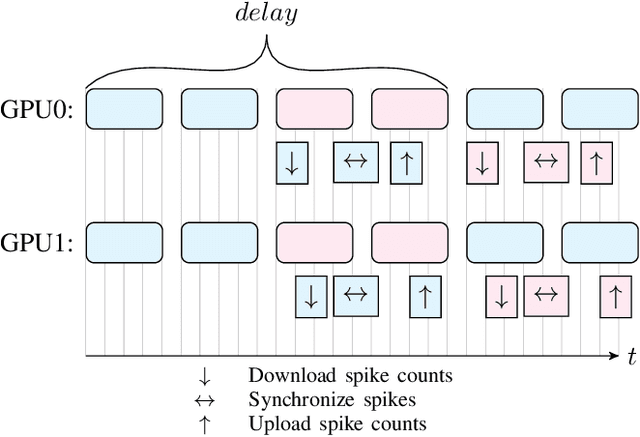
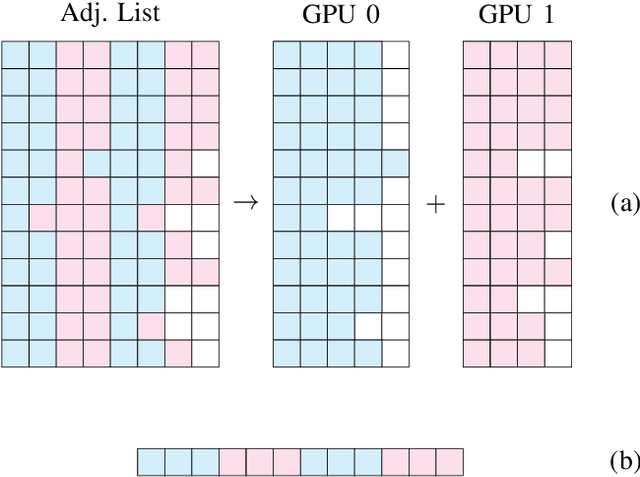
We present a SNN simulator which scales to millions of neurons, billions of synapses, and 8 GPUs. This is made possible by 1) a novel, cache-aware spike transmission algorithm 2) a model parallel multi-GPU distribution scheme and 3) a static, yet very effective load balancing strategy. The simulator further features an easy to use API and the ability to create custom models. We compare the proposed simulator against two state of the art ones on a series of benchmarks using three well-established models. We find that our simulator is faster, consumes less memory, and scales linearly with the number of GPUs.
Faster and Simpler SNN Simulation with Work Queues
Dec 17, 2019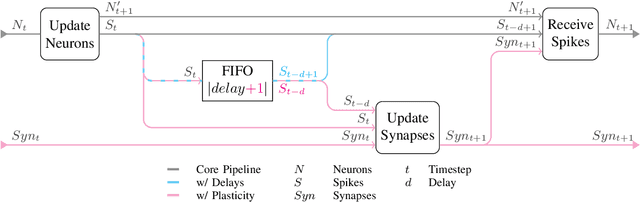


We present a clock-driven Spiking Neural Network simulator which is up to 3x faster than the state of the art while, at the same time, being more general and requiring less programming effort on both the user's and maintainer's side. This is made possible by designing our pipeline around "work queues" which act as interfaces between stages and greatly reduce implementation complexity. We evaluate our work using three well-established SNN models on a series of benchmarks.
ReActNet: Temporal Localization of Repetitive Activities in Real-World Videos
Oct 14, 2019
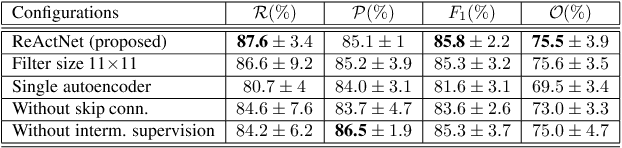
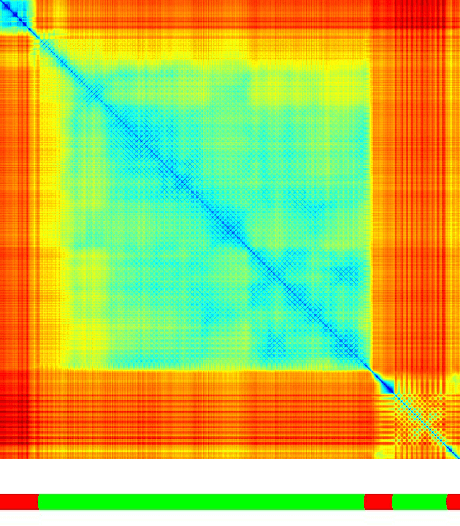
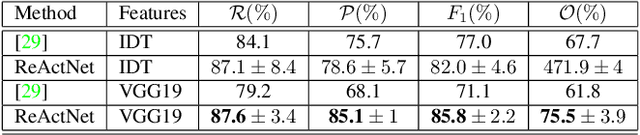
We address the problem of temporal localization of repetitive activities in a video, i.e., the problem of identifying all segments of a video that contain some sort of repetitive or periodic motion. To do so, the proposed method represents a video by the matrix of pairwise frame distances. These distances are computed on frame representations obtained with a convolutional neural network. On top of this representation, we design, implement and evaluate ReActNet, a lightweight convolutional neural network that classifies a given frame as belonging (or not) to a repetitive video segment. An important property of the employed representation is that it can handle repetitive segments of arbitrary number and duration. Furthermore, the proposed training process requires a relatively small number of annotated videos. Our method raises several of the limiting assumptions of existing approaches regarding the contents of the video and the types of the observed repetitive activities. Experimental results on recent, publicly available datasets validate our design choices, verify the generalization potential of ReActNet and demonstrate its superior performance in comparison to the current state of the art.
Accurate Hand Keypoint Localization on Mobile Devices
Dec 19, 2018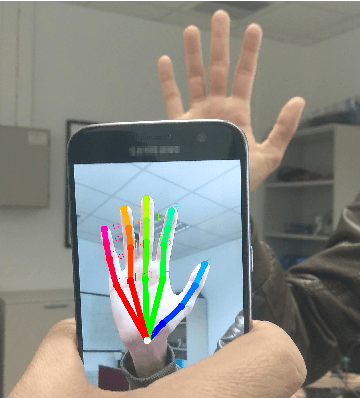
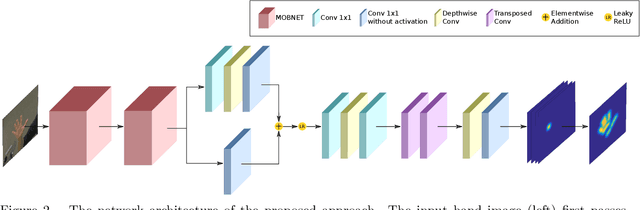

We present a novel approach for 2D hand keypoint localization from regular color input. The proposed approach relies on an appropriately designed Convolutional Neural Network (CNN) that computes a set of heatmaps, one per hand keypoint of interest. Extensive experiments with the proposed method compare it against state of the art approaches and demonstrate its accuracy and computational performance on standard, publicly available datasets. The obtained results demonstrate that the proposed method matches or outperforms the competing methods in accuracy, but clearly outperforms them in computational efficiency, making it a suitable building block for applications that require hand keypoint estimation on mobile devices.