 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Based Mistake Analysis in Procedural Activities: A Review of Advances and Challenges
Oct 22, 2025Mistake analysis in procedural activities is a critical area of research with applications spanning industrial automation, physical rehabilitation, education and human-robot collaboration. This paper reviews vision-based methods for detecting and predicting mistakes in structured tasks, focusing on procedural and executional errors. By leveraging advancements in computer vision, including action recognition, anticipation and activity understanding, vision-based systems can identify deviations in task execution, such as incorrect sequencing, use of improper techniques, or timing errors. We explore the challenges posed by intra-class variability, viewpoint differences and compositional activity structures, which complicate mistake detection. Additionally, we provide a comprehensive overview of existing datasets, evaluation metrics and state-of-the-art methods, categorizing approaches based on their use of procedural structure, supervision levels and learning strategies. Open challenges, such as distinguishing permissible variations from true mistakes and modeling error propagation are discussed alongside future directions, including neuro-symbolic reasoning and counterfactual state modeling. This work aims to establish a unified perspective on vision-based mistake analysis in procedural activities, highlighting its potential to enhance safety, efficiency and task performance across diverse domains.
Y-MAP-Net: Real-time depth, normals, segmentation, multi-label captioning and 2D human pose in RGB images
Nov 15, 2024



We present Y-MAP-Net, a Y-shaped neural network architecture designed for real-time multi-task learning on RGB images. Y-MAP-Net, simultaneously predicts depth, surface normals, human pose, semantic segmentation and generates multi-label captions, all from a single network evaluation. To achieve this, we adopt a multi-teacher, single-student training paradigm, where task-specific foundation models supervise the network's learning, enabling it to distill their capabilities into a lightweight architecture suitable for real-time applications. Y-MAP-Net, exhibits strong generalization, simplicity and computational efficiency, making it ideal for robotics and other practical scenarios. To support future research, we will release our code publicly.
Multi-view Image-based Hand Geometry Refinement using Differentiable Monte Carlo Ray Tracing
Jul 12, 2021
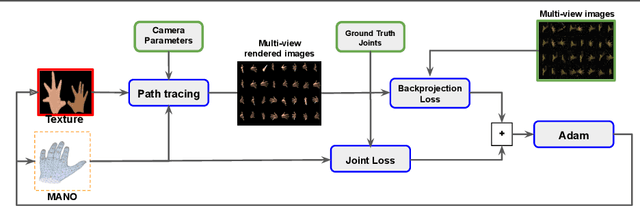
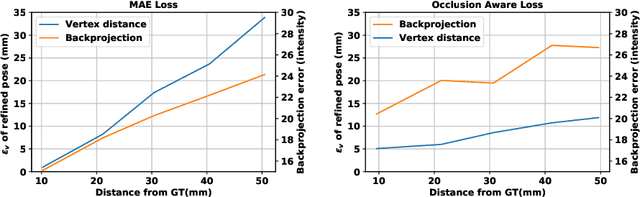
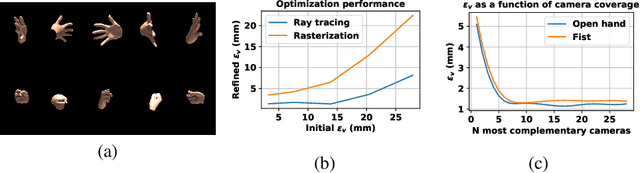
The amount and quality of datasets and tools available in the research field of hand pose and shape estimation act as evidence to the significant progress that has been made. We find that there is still room for improvement in both fronts, and even beyond. Even the datasets of the highest quality, reported to date, have shortcomings in annotation. There are tools in the literature that can assist in that direction and yet they have not been considered, so far. To demonstrate how these gaps can be bridged, we employ such a publicly available, multi-camera dataset of hands (InterHand2.6M), and perform effective image-based refinement to improve on the imperfect ground truth annotations, yielding a better dataset. The image-based refinement is achieved through raytracing, a method that has not been employed so far to relevant problems and is hereby shown to be superior to the approximative alternatives that have been employed in the past. To tackle the lack of reliable ground truth, we resort to realistic synthetic data, to show that the improvement we induce is indeed significant, qualitatively, and quantitatively, too.
Hybrid One-Shot 3D Hand Pose Estimation by Exploiting Uncertainties
Oct 27, 2015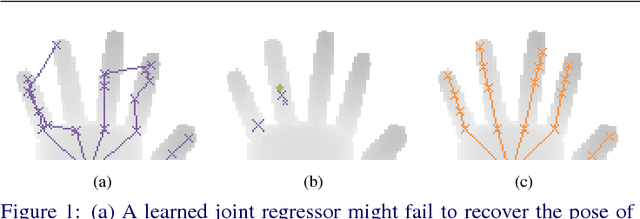

Model-based approaches to 3D hand tracking have been shown to perform well in a wide range of scenarios. However, they require initialisation and cannot recover easily from tracking failures that occur due to fast hand motions. Data-driven approaches, on the other hand, can quickly deliver a solution, but the results often suffer from lower accuracy or missing anatomical validity compared to those obtained from model-based approaches. In this work we propose a hybrid approach for hand pose estimation from a single depth image. First, a learned regressor is employed to deliver multiple initial hypotheses for the 3D position of each hand joint. Subsequently, the kinematic parameters of a 3D hand model are found by deliberately exploiting the inherent uncertainty of the inferred joint proposals. This way, the method provides anatomically valid and accurate solutions without requiring manual initialisation or suffering from track losses. Quantitative results on several standard datasets demonstrate that the proposed method outperforms state-of-the-art representatives of the model-based, data-driven and hybrid paradigms.