 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMURAUER: Mapping Unlabeled Real Data for Label AUstERity
Dec 05, 2018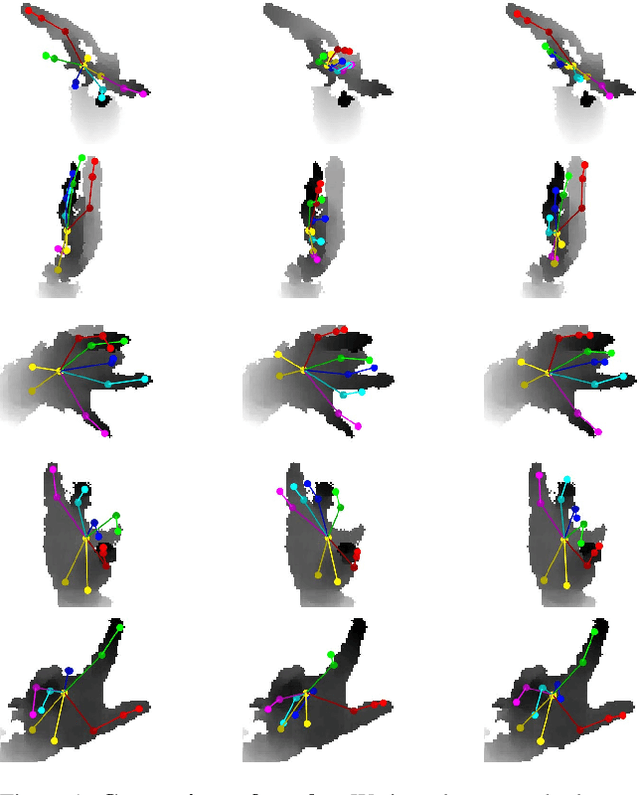
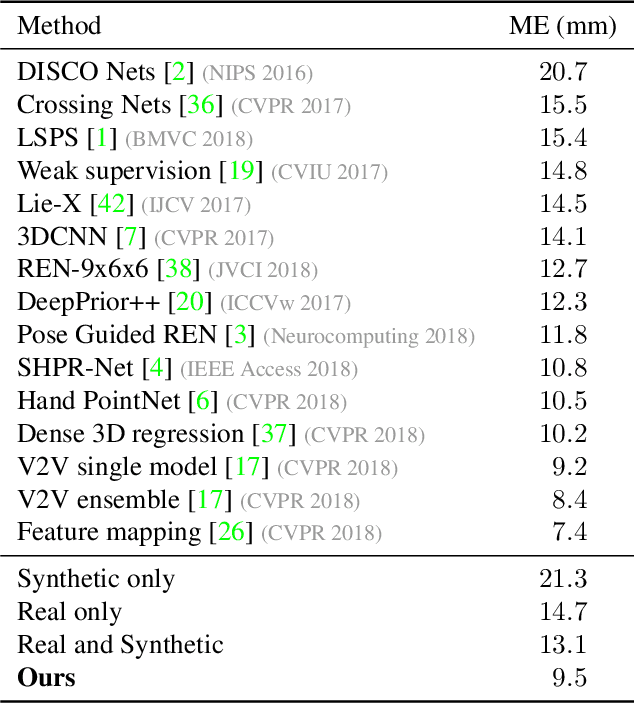
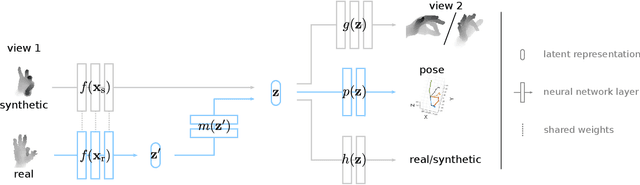
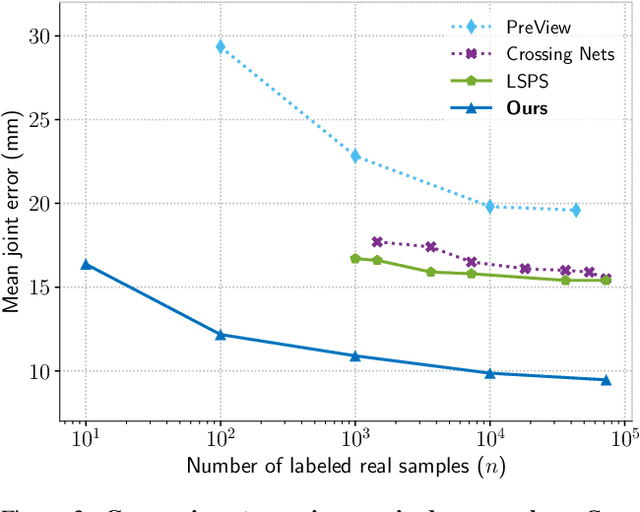
Data labeling for learning 3D hand pose estimation models is a huge effort. Readily available, accurately labeled synthetic data has the potential to reduce the effort. However, to successfully exploit synthetic data, current state-of-the-art methods still require a large amount of labeled real data. In this work, we remove this requirement by learning to map from the features of real data to the features of synthetic data mainly using a large amount of synthetic and unlabeled real data. We exploit unlabeled data using two auxiliary objectives, which enforce that (i) the mapped representation is pose specific and (ii) at the same time, the distributions of real and synthetic data are aligned. While pose specifity is enforced by a self-supervisory signal requiring that the representation is predictive for the appearance from different views, distributions are aligned by an adversarial term. In this way, we can significantly improve the results of the baseline system, which does not use unlabeled data and outperform many recent approaches already with about 1% of the labeled real data. This presents a step towards faster deployment of learning based hand pose estimation, making it accessible for a larger range of applications.
Learning Pose Specific Representations by Predicting Different Views
May 23, 2018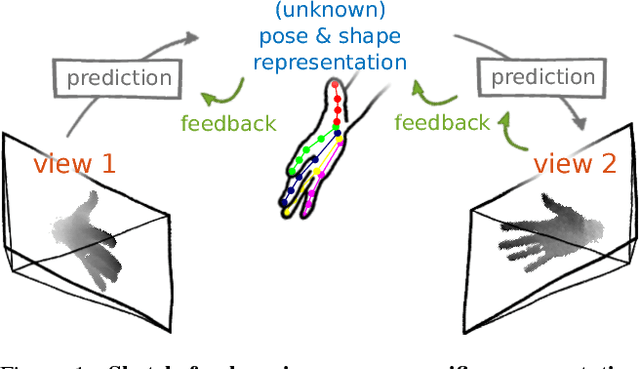
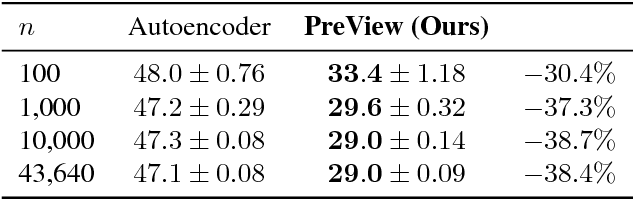
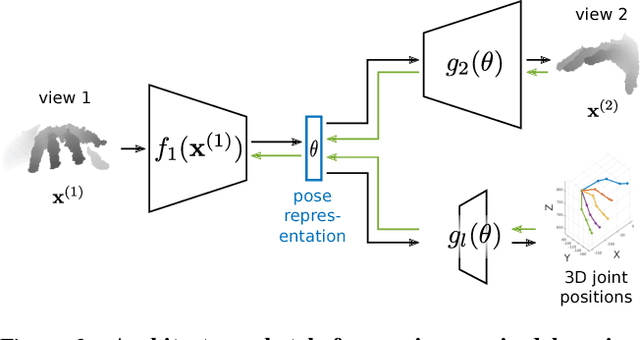
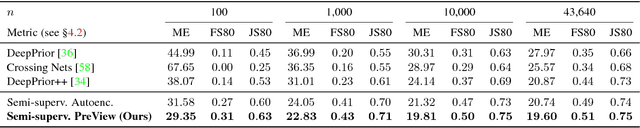
The labeled data required to learn pose estimation for articulated objects is difficult to provide in the desired quantity, realism, density, and accuracy. To address this issue, we develop a method to learn representations, which are very specific for articulated poses, without the need for labeled training data. We exploit the observation that the object pose of a known object is predictive for the appearance in any known view. That is, given only the pose and shape parameters of a hand, the hand's appearance from any viewpoint can be approximated. To exploit this observation, we train a model that -- given input from one view -- estimates a latent representation, which is trained to be predictive for the appearance of the object when captured from another viewpoint. Thus, the only necessary supervision is the second view. The training process of this model reveals an implicit pose representation in the latent space. Importantly, at test time the pose representation can be inferred using only a single view. In qualitative and quantitative experiments we show that the learned representations capture detailed pose information. Moreover, when training the proposed method jointly with labeled and unlabeled data, it consistently surpasses the performance of its fully supervised counterpart, while reducing the amount of needed labeled samples by at least one order of magnitude.
PetroSurf3D - A Dataset for high-resolution 3D Surface Segmentation
Mar 01, 2017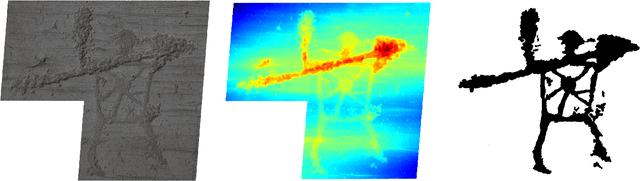
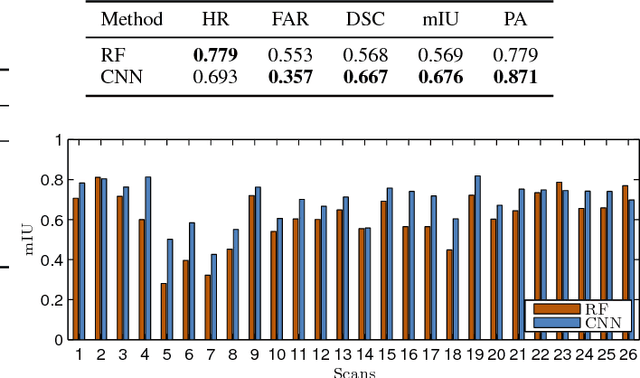

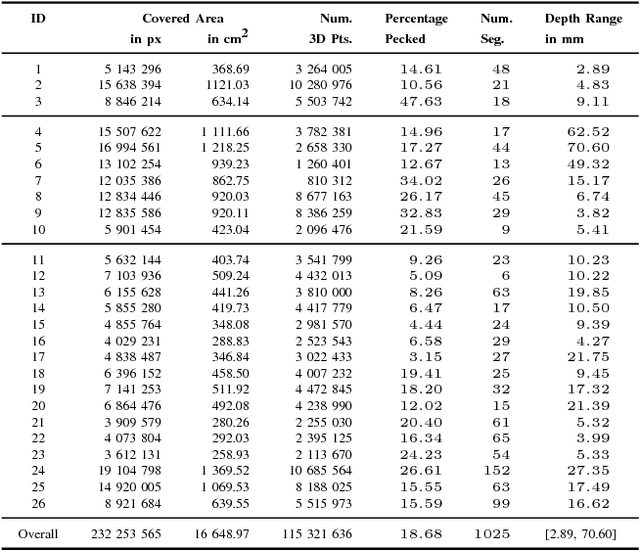
The development of powerful 3D scanning hardware and reconstruction algorithms has strongly promoted the generation of 3D surface reconstructions in different domains. An area of special interest for such 3D reconstructions is the cultural heritage domain, where surface reconstructions are generated to digitally preserve historical artifacts. While reconstruction quality nowadays is sufficient in many cases, the robust analysis (e.g. segmentation, matching, and classification) of reconstructed 3D data is still an open topic. In this paper, we target the automatic and interactive segmentation of high-resolution 3D surface reconstructions from the archaeological domain. To foster research in this field, we introduce a fully annotated and publicly available large-scale 3D surface dataset including high-resolution meshes, depth maps and point clouds as a novel benchmark dataset to the community. We provide baseline results for our existing random forest-based approach and for the first time investigate segmentation with convolutional neural networks (CNNs) on the data. Results show that both approaches have complementary strengths and weaknesses and that the provided dataset represents a challenge for future research.
Grid Loss: Detecting Occluded Faces
Sep 01, 2016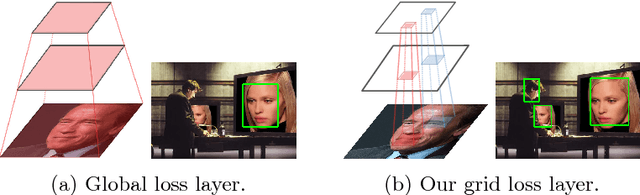
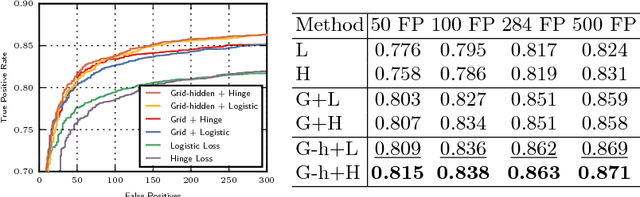
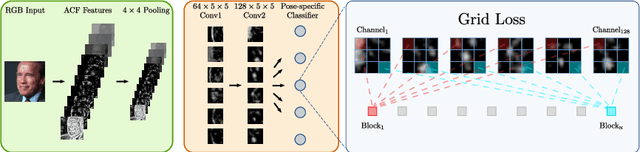
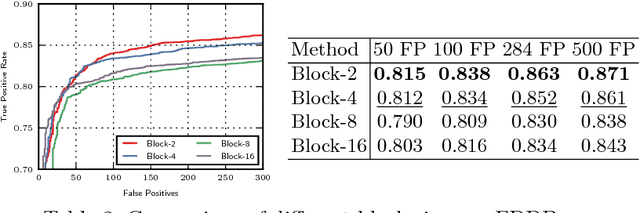
Detection of partially occluded objects is a challenging computer vision problem. Standard Convolutional Neural Network (CNN) detectors fail if parts of the detection window are occluded, since not every sub-part of the window is discriminative on its own. To address this issue, we propose a novel loss layer for CNNs, named grid loss, which minimizes the error rate on sub-blocks of a convolution layer independently rather than over the whole feature map. This results in parts being more discriminative on their own, enabling the detector to recover if the detection window is partially occluded. By mapping our loss layer back to a regular fully connected layer, no additional computational cost is incurred at runtime compared to standard CNNs. We demonstrate our method for face detection on several public face detection benchmarks and show that our method outperforms regular CNNs, is suitable for realtime applications and achieves state-of-the-art performance.
Hybrid One-Shot 3D Hand Pose Estimation by Exploiting Uncertainties
Oct 27, 2015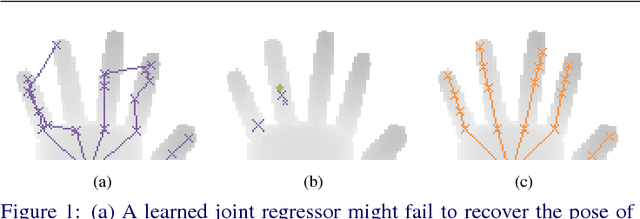

Model-based approaches to 3D hand tracking have been shown to perform well in a wide range of scenarios. However, they require initialisation and cannot recover easily from tracking failures that occur due to fast hand motions. Data-driven approaches, on the other hand, can quickly deliver a solution, but the results often suffer from lower accuracy or missing anatomical validity compared to those obtained from model-based approaches. In this work we propose a hybrid approach for hand pose estimation from a single depth image. First, a learned regressor is employed to deliver multiple initial hypotheses for the 3D position of each hand joint. Subsequently, the kinematic parameters of a 3D hand model are found by deliberately exploiting the inherent uncertainty of the inferred joint proposals. This way, the method provides anatomically valid and accurate solutions without requiring manual initialisation or suffering from track losses. Quantitative results on several standard datasets demonstrate that the proposed method outperforms state-of-the-art representatives of the model-based, data-driven and hybrid paradigms.