 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFHSTP@EXIST 2025 Benchmark: Sexism Detection with Transparent Speech Concept Bottleneck Models
Jul 28, 2025Sexism has become widespread on social media and in online conversation. To help address this issue, the fifth Sexism Identification in Social Networks (EXIST) challenge is initiated at CLEF 2025. Among this year's international benchmarks, we concentrate on solving the first task aiming to identify and classify sexism in social media textual posts. In this paper, we describe our solutions and report results for three subtasks: Subtask 1.1 - Sexism Identification in Tweets, Subtask 1.2 - Source Intention in Tweets, and Subtask 1.3 - Sexism Categorization in Tweets. We implement three models to address each subtask which constitute three individual runs: Speech Concept Bottleneck Model (SCBM), Speech Concept Bottleneck Model with Transformer (SCBMT), and a fine-tuned XLM-RoBERTa transformer model. SCBM uses descriptive adjectives as human-interpretable bottleneck concepts. SCBM leverages large language models (LLMs) to encode input texts into a human-interpretable representation of adjectives, then used to train a lightweight classifier for downstream tasks. SCBMT extends SCBM by fusing adjective-based representation with contextual embeddings from transformers to balance interpretability and classification performance. Beyond competitive results, these two models offer fine-grained explanations at both instance (local) and class (global) levels. We also investigate how additional metadata, e.g., annotators' demographic profiles, can be leveraged. For Subtask 1.1, XLM-RoBERTa, fine-tuned on provided data augmented with prior datasets, ranks 6th for English and Spanish and 4th for English in the Soft-Soft evaluation. Our SCBMT achieves 7th for English and Spanish and 6th for Spanish.
Machine Learning in Biomechanics: Key Applications and Limitations in Walking, Running, and Sports Movements
Mar 05, 2025This chapter provides an overview of recent and promising Machine Learning applications, i.e. pose estimation, feature estimation, event detection, data exploration & clustering, and automated classification, in gait (walking and running) and sports biomechanics. It explores the potential of Machine Learning methods to address challenges in biomechanical workflows, highlights central limitations, i.e. data and annotation availability and explainability, that need to be addressed, and emphasises the importance of interdisciplinary approaches for fully harnessing the potential of Machine Learning in gait and sports biomechanics.
Analysis of Hybrid Compositions in Animation Film with Weakly Supervised Learning
Oct 07, 2024
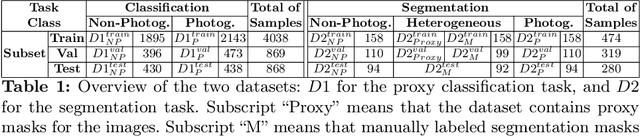
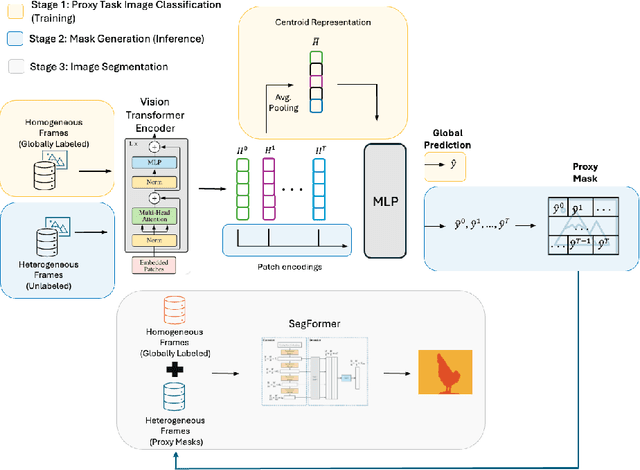

We present an approach for the analysis of hybrid visual compositions in animation in the domain of ephemeral film. We combine ideas from semi-supervised and weakly supervised learning to train a model that can segment hybrid compositions without requiring pre-labeled segmentation masks. We evaluate our approach on a set of ephemeral films from 13 film archives. Results demonstrate that the proposed learning strategy yields a performance close to a fully supervised baseline. On a qualitative level the performed analysis provides interesting insights on hybrid compositions in animation film.
Exploring the Plausibility of Hate and Counter Speech Detectors with Explainable AI
Jul 25, 2024In this paper we investigate the explainability of transformer models and their plausibility for hate speech and counter speech detection. We compare representatives of four different explainability approaches, i.e., gradient-based, perturbation-based, attention-based, and prototype-based approaches, and analyze them quantitatively with an ablation study and qualitatively in a user study. Results show that perturbation-based explainability performs best, followed by gradient-based and attention-based explainability. Prototypebased experiments did not yield useful results. Overall, we observe that explainability strongly supports the users in better understanding the model predictions.
3D Multimodal Image Registration for Plant Phenotyping
Jul 03, 2024



The use of multiple camera technologies in a combined multimodal monitoring system for plant phenotyping offers promising benefits. Compared to configurations that only utilize a single camera technology, cross-modal patterns can be recorded that allow a more comprehensive assessment of plant phenotypes. However, the effective utilization of cross-modal patterns is dependent on precise image registration to achieve pixel-accurate alignment, a challenge often complicated by parallax and occlusion effects inherent in plant canopy imaging. In this study, we propose a novel multimodal 3D image registration method that addresses these challenges by integrating depth information from a time-of-flight camera into the registration process. By leveraging depth data, our method mitigates parallax effects and thus facilitates more accurate pixel alignment across camera modalities. Additionally, we introduce an automated mechanism to identify and differentiate different types of occlusions, thereby minimizing the introduction of registration errors. To evaluate the efficacy of our approach, we conduct experiments on a diverse image dataset comprising six distinct plant species with varying leaf geometries. Our results demonstrate the robustness of the proposed registration algorithm, showcasing its ability to achieve accurate alignment across different plant types and camera compositions. Compared to previous methods it is not reliant on detecting plant specific image features and can thereby be utilized for a wide variety of applications in plant sciences. The registration approach principally scales to arbitrary numbers of cameras with different resolutions and wavelengths. Overall, our study contributes to advancing the field of plant phenotyping by offering a robust and reliable solution for multimodal image registration.
Case Study: Ensemble Decision-Based Annotation of Unconstrained Real Estate Images
Sep 26, 2023We describe a proof-of-concept for annotating real estate images using simple iterative rule-based semi-supervised learning. In this study, we have gained important insights into the content characteristics and uniqueness of individual image classes as well as essential requirements for a practical implementation.
Explaining YOLO: Leveraging Grad-CAM to Explain Object Detections
Nov 22, 2022


We investigate the problem of explainability for visual object detectors. Specifically, we demonstrate on the example of the YOLO object detector how to integrate Grad-CAM into the model architecture and analyze the results. We show how to compute attribution-based explanations for individual detections and find that the normalization of the results has a great impact on their interpretation.
Real Estate Attribute Prediction from Multiple Visual Modalities with Missing Data
Nov 16, 2022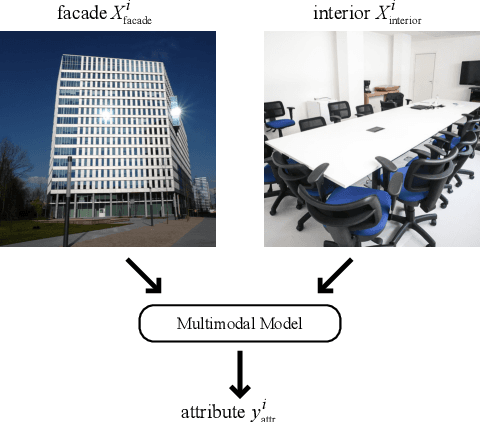
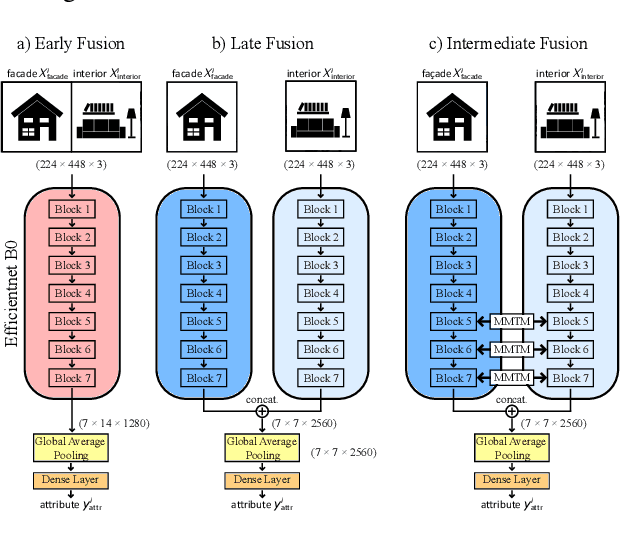
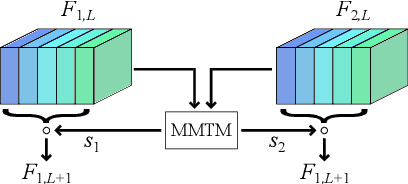

The assessment and valuation of real estate requires large datasets with real estate information. Unfortunately, real estate databases are usually sparse in practice, i.e., not for each property every important attribute is available. In this paper, we study the potential of predicting high-level real estate attributes from visual data, specifically from two visual modalities, namely indoor (interior) and outdoor (facade) photos. We design three models using different multimodal fusion strategies and evaluate them for three different use cases. Thereby, a particular challenge is to handle missing modalities. We evaluate different fusion strategies, present baselines for the different prediction tasks, and find that enriching the training data with additional incomplete samples can lead to an improvement in prediction accuracy. Furthermore, the fusion of information from indoor and outdoor photos results in a performance boost of up to 5% in Macro F1-score.
* included in the Proceedings of the OAGM Workshop 2021
Trustworthy Visual Analytics in Clinical Gait Analysis: A Case Study for Patients with Cerebral Palsy
Aug 10, 2022
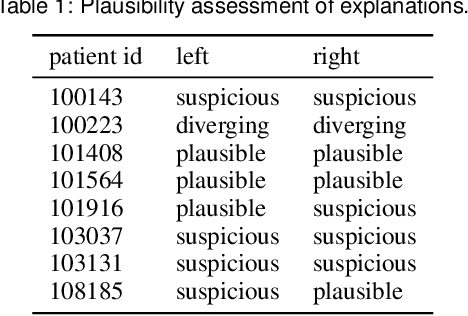
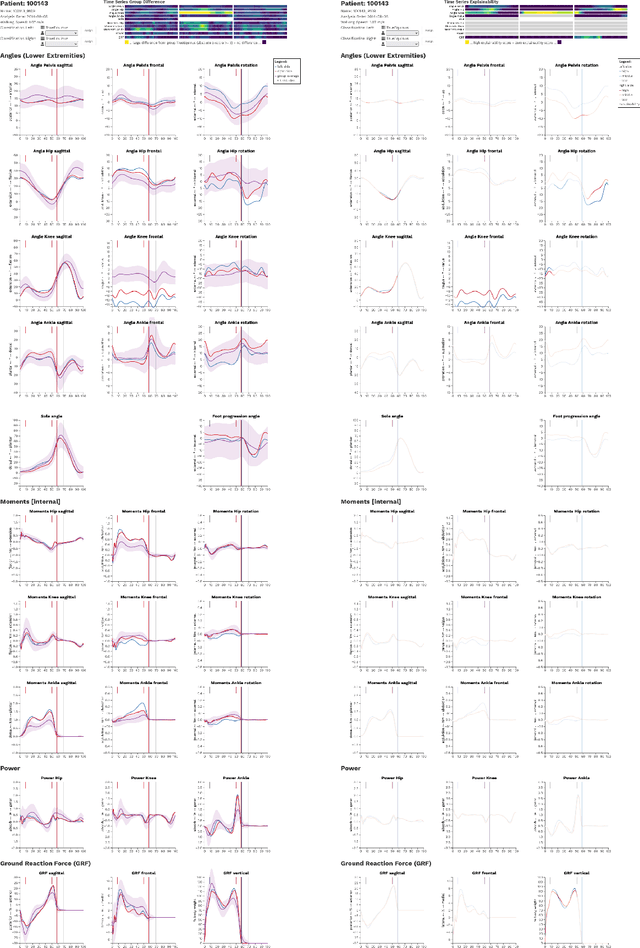
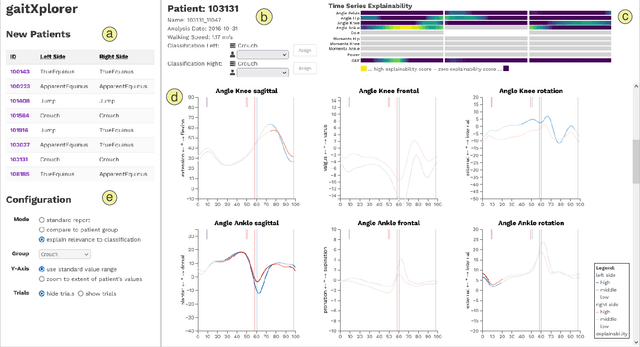
Three-dimensional clinical gait analysis is essential for selecting optimal treatment interventions for patients with cerebral palsy (CP), but generates a large amount of time series data. For the automated analysis of these data, machine learning approaches yield promising results. However, due to their black-box nature, such approaches are often mistrusted by clinicians. We propose gaitXplorer, a visual analytics approach for the classification of CP-related gait patterns that integrates Grad-CAM, a well-established explainable artificial intelligence algorithm, for explanations of machine learning classifications. Regions of high relevance for classification are highlighted in the interactive visual interface. The approach is evaluated in a case study with two clinical gait experts. They inspected the explanations for a sample of eight patients using the visual interface and expressed which relevance scores they found trustworthy and which they found suspicious. Overall, the clinicians gave positive feedback on the approach as it allowed them a better understanding of which regions in the data were relevant for the classification.
Multimodal Detection of Information Disorder from Social Media
May 31, 2021
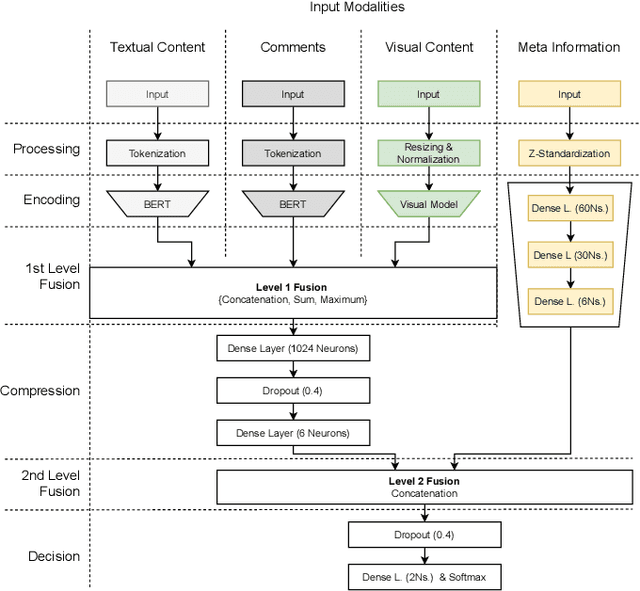
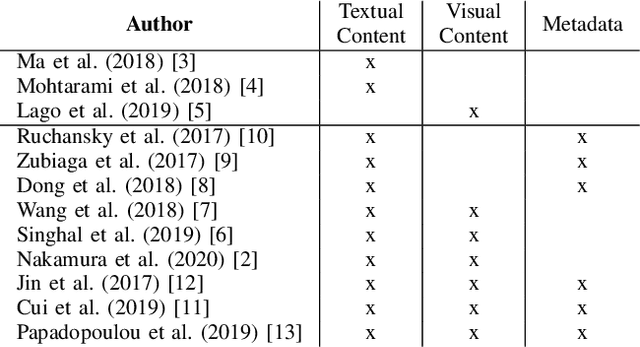
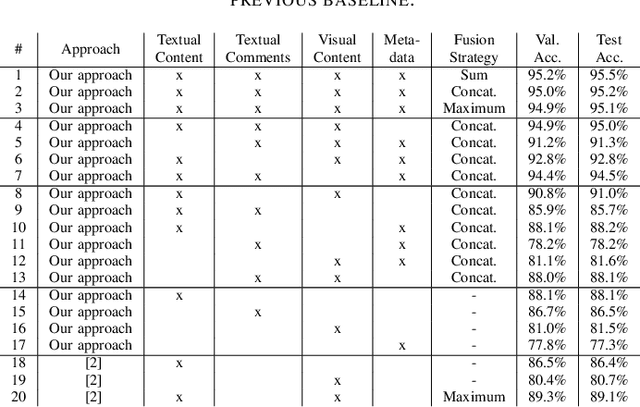
Social media is accompanied by an increasing proportion of content that provides fake information or misleading content, known as information disorder. In this paper, we study the problem of multimodal fake news detection on a largescale multimodal dataset. We propose a multimodal network architecture that enables different levels and types of information fusion. In addition to the textual and visual content of a posting, we further leverage secondary information, i.e. user comments and metadata. We fuse information at multiple levels to account for the specific intrinsic structure of the modalities. Our results show that multimodal analysis is highly effective for the task and all modalities contribute positively when fused properly.