 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Multimodal Image Registration for Plant Phenotyping
Jul 03, 2024



The use of multiple camera technologies in a combined multimodal monitoring system for plant phenotyping offers promising benefits. Compared to configurations that only utilize a single camera technology, cross-modal patterns can be recorded that allow a more comprehensive assessment of plant phenotypes. However, the effective utilization of cross-modal patterns is dependent on precise image registration to achieve pixel-accurate alignment, a challenge often complicated by parallax and occlusion effects inherent in plant canopy imaging. In this study, we propose a novel multimodal 3D image registration method that addresses these challenges by integrating depth information from a time-of-flight camera into the registration process. By leveraging depth data, our method mitigates parallax effects and thus facilitates more accurate pixel alignment across camera modalities. Additionally, we introduce an automated mechanism to identify and differentiate different types of occlusions, thereby minimizing the introduction of registration errors. To evaluate the efficacy of our approach, we conduct experiments on a diverse image dataset comprising six distinct plant species with varying leaf geometries. Our results demonstrate the robustness of the proposed registration algorithm, showcasing its ability to achieve accurate alignment across different plant types and camera compositions. Compared to previous methods it is not reliant on detecting plant specific image features and can thereby be utilized for a wide variety of applications in plant sciences. The registration approach principally scales to arbitrary numbers of cameras with different resolutions and wavelengths. Overall, our study contributes to advancing the field of plant phenotyping by offering a robust and reliable solution for multimodal image registration.
Case Study: Ensemble Decision-Based Annotation of Unconstrained Real Estate Images
Sep 26, 2023We describe a proof-of-concept for annotating real estate images using simple iterative rule-based semi-supervised learning. In this study, we have gained important insights into the content characteristics and uniqueness of individual image classes as well as essential requirements for a practical implementation.
Real Estate Attribute Prediction from Multiple Visual Modalities with Missing Data
Nov 16, 2022
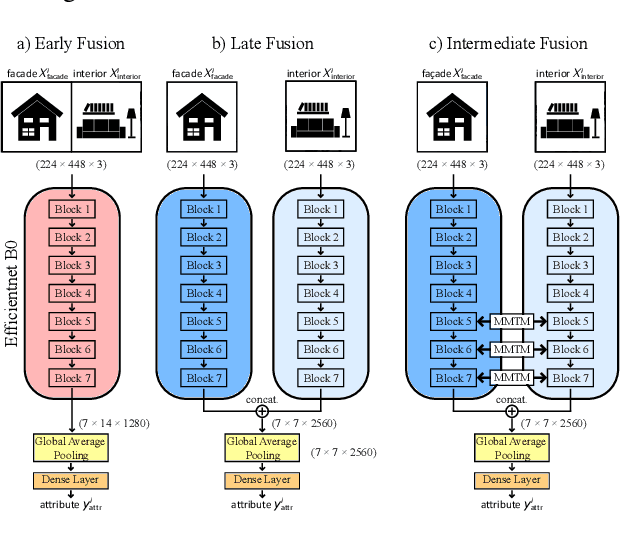
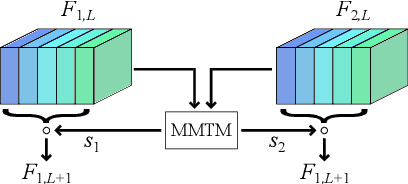

The assessment and valuation of real estate requires large datasets with real estate information. Unfortunately, real estate databases are usually sparse in practice, i.e., not for each property every important attribute is available. In this paper, we study the potential of predicting high-level real estate attributes from visual data, specifically from two visual modalities, namely indoor (interior) and outdoor (facade) photos. We design three models using different multimodal fusion strategies and evaluate them for three different use cases. Thereby, a particular challenge is to handle missing modalities. We evaluate different fusion strategies, present baselines for the different prediction tasks, and find that enriching the training data with additional incomplete samples can lead to an improvement in prediction accuracy. Furthermore, the fusion of information from indoor and outdoor photos results in a performance boost of up to 5% in Macro F1-score.
* included in the Proceedings of the OAGM Workshop 2021