 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNovel Object Synthesis via Adaptive Text-Image Harmony
Oct 28, 2024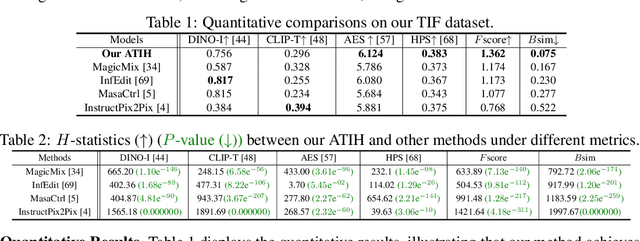
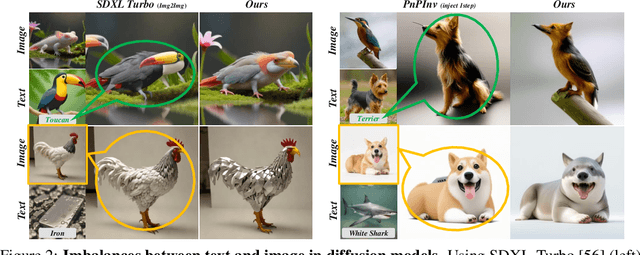
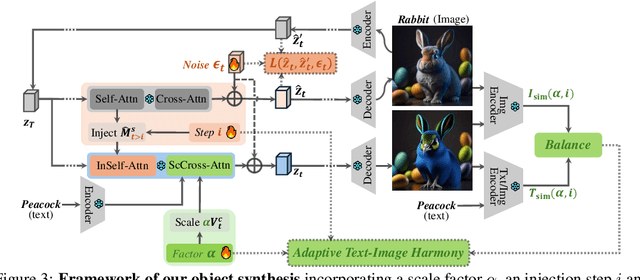
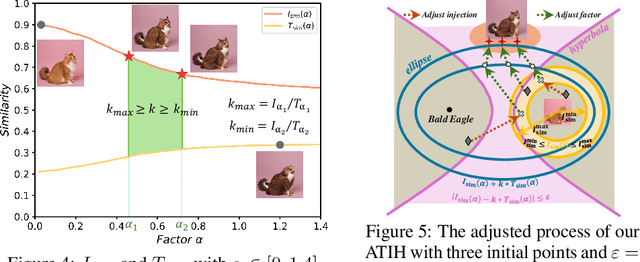
In this paper, we study an object synthesis task that combines an object text with an object image to create a new object image. However, most diffusion models struggle with this task, \textit{i.e.}, often generating an object that predominantly reflects either the text or the image due to an imbalance between their inputs. To address this issue, we propose a simple yet effective method called Adaptive Text-Image Harmony (ATIH) to generate novel and surprising objects. First, we introduce a scale factor and an injection step to balance text and image features in cross-attention and to preserve image information in self-attention during the text-image inversion diffusion process, respectively. Second, to better integrate object text and image, we design a balanced loss function with a noise parameter, ensuring both optimal editability and fidelity of the object image. Third, to adaptively adjust these parameters, we present a novel similarity score function that not only maximizes the similarities between the generated object image and the input text/image but also balances these similarities to harmonize text and image integration. Extensive experiments demonstrate the effectiveness of our approach, showcasing remarkable object creations such as colobus-glass jar. Project page: https://xzr52.github.io/ATIH/.
Amazing Combinatorial Creation: Acceptable Swap-Sampling for Text-to-Image Generation
Oct 03, 2023Exploring a machine learning system to generate meaningful combinatorial object images from multiple textual descriptions, emulating human creativity, is a significant challenge as humans are able to construct amazing combinatorial objects, but machines strive to emulate data distribution. In this paper, we develop a straightforward yet highly effective technique called acceptable swap-sampling to generate a combinatorial object image that exhibits novelty and surprise, utilizing text concepts of different objects. Initially, we propose a swapping mechanism that constructs a novel embedding by exchanging column vectors of two text embeddings for generating a new combinatorial image through a cutting-edge diffusion model. Furthermore, we design an acceptable region by managing suitable CLIP distances between the new image and the original concept generations, increasing the likelihood of accepting the new image with a high-quality combination. This region allows us to efficiently sample a small subset from a new image pool generated by using randomly exchanging column vectors. Lastly, we employ a segmentation method to compare CLIP distances among the segmented components, ultimately selecting the most promising object image from the sampled subset. Our experiments focus on text pairs of objects from ImageNet, and our results demonstrate that our approach outperforms recent methods such as Stable-Diffusion2, DALLE2, ERNIE-ViLG2 and Bing in generating novel and surprising object images, even when the associated concepts appear to be implausible, such as lionfish-abacus. Furthermore, during the sampling process, our approach without training and human preference is also comparable to PickScore and HPSv2 trained using human preference datasets.
Case Study: Ensemble Decision-Based Annotation of Unconstrained Real Estate Images
Sep 26, 2023We describe a proof-of-concept for annotating real estate images using simple iterative rule-based semi-supervised learning. In this study, we have gained important insights into the content characteristics and uniqueness of individual image classes as well as essential requirements for a practical implementation.
Real Estate Attribute Prediction from Multiple Visual Modalities with Missing Data
Nov 16, 2022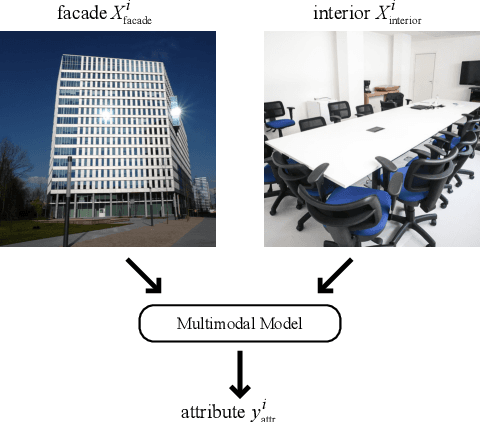
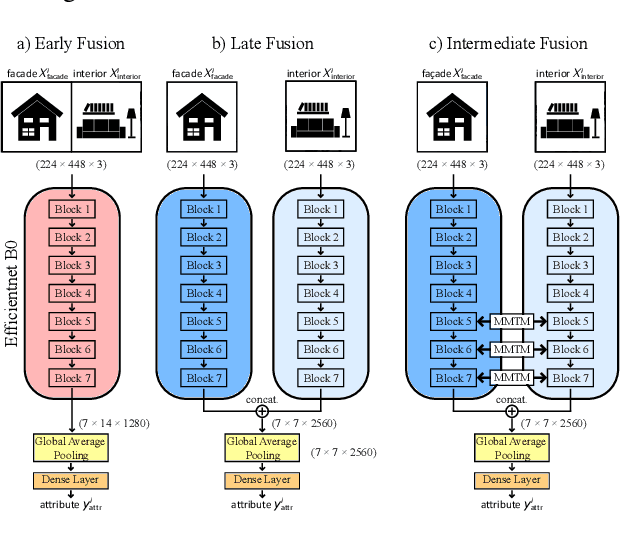
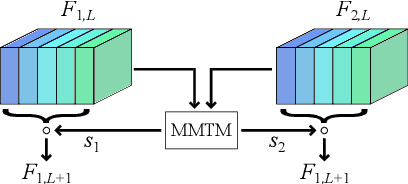

The assessment and valuation of real estate requires large datasets with real estate information. Unfortunately, real estate databases are usually sparse in practice, i.e., not for each property every important attribute is available. In this paper, we study the potential of predicting high-level real estate attributes from visual data, specifically from two visual modalities, namely indoor (interior) and outdoor (facade) photos. We design three models using different multimodal fusion strategies and evaluate them for three different use cases. Thereby, a particular challenge is to handle missing modalities. We evaluate different fusion strategies, present baselines for the different prediction tasks, and find that enriching the training data with additional incomplete samples can lead to an improvement in prediction accuracy. Furthermore, the fusion of information from indoor and outdoor photos results in a performance boost of up to 5% in Macro F1-score.
* included in the Proceedings of the OAGM Workshop 2021
FIRL: Fast Imitation and Policy Reuse Learning
Mar 01, 2022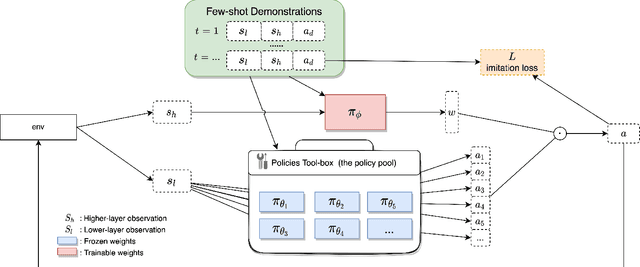
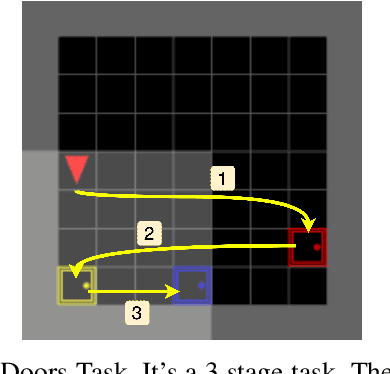
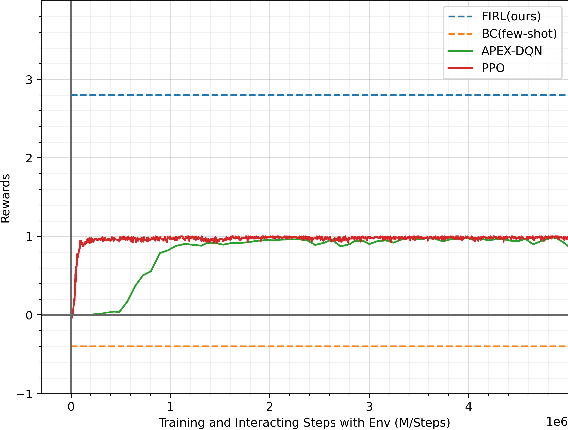
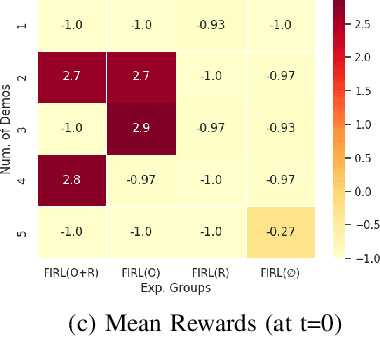
Intelligent robotics policies have been widely researched for challenging applications such as opening doors, washing dishes, and table organization. We refer to a "Policy Pool", containing skills that be easily accessed and reused. There are researches to leverage the pool, such as policy reuse, modular learning, assembly learning, transfer learning, hierarchical reinforcement learning (HRL), etc. However, most methods generally do not perform well in learning efficiency and require large datasets for training. This work focuses on enabling fast learning based on the policy pool. It should learn fast enough in one-shot or few-shot by avoiding learning from scratch. We also allow it to interact and learn from humans, but the training period should be within minutes. We propose FIRL, Fast (one-shot) Imitation, and Policy Reuse Learning. Instead of learning a new skill from scratch, it performs the one-shot imitation learning on the higher layer under a 2-layer hierarchical mechanism. Our method reduces a complex task learning to a simple regression problem that it could solve in a few offline iterations. The agent could have a good command of a new task given a one-shot demonstration. We demonstrate this method on the OpenDoors mini-grid environment, and the code is available on http://www.github.com/yiwc/firl.