 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOTPL-VIO: Robust Visual-Inertial Odometry with Optimal Transport Line Association and Adaptive Uncertainty
Mar 10, 2026Robust stereo visual-inertial odometry (VIO) remains challenging in low-texture scenes and under abrupt illumination changes, where point features become sparse and unstable, leading to ambiguous association and under-constrained estimation. Line structures offer complementary geometric cues, yet many efficient point-line systems still rely on point-guided line association, which can break down when point support is weak and may lead to biased constraints. We present a stereo point-line VIO system in which line segments are equipped with dedicated deep descriptors and matched using an entropy-regularized optimal transport formulation, enabling globally consistent correspondences under ambiguity, outliers, and partial observations. The proposed descriptor is training-free and is computed by sampling and pooling network feature maps. To improve estimation stability, we analyze the impact of line measurement noise and introduce reliability-adaptive weighting to regulate the influence of line constraints during optimization. Experiments on EuRoC and UMA-VI, together with real-world deployments in low-texture and illumination-challenging environments, demonstrate improved accuracy and robustness over representative baselines while maintaining real-time performance.
Graph-Loc: Robust Graph-Based LiDAR Pose Tracking with Compact Structural Map Priors under Low Observability and Occlusion
Feb 09, 2026Map-based LiDAR pose tracking is essential for long-term autonomous operation, where onboard map priors need be compact for scalable storage and fast retrieval, while online observations are often partial, repetitive, and heavily occluded. We propose Graph-Loc, a graph-based localization framework that tracks the platform pose against compact structural map priors represented as a lightweight point-line graph. Such priors can be constructed from heterogeneous sources commonly available in practice, including polygon outlines vectorized from occupancy/grid maps and CAD/model/floor-plan layouts. For each incoming LiDAR scan, Graph-Loc extracts sparse point and line primitives to form an observation graph, retrieves a pose-conditioned visible subgraph via LiDAR ray simulation, and performs scan-to-map association through unbalanced optimal transport with a local graph-context regularizer. The unbalanced formulation relaxes mass conservation, improving robustness to missing, spurious, and fragmented structures under occlusion. To enhance stability in low-observability segments, we estimate information anisotropy from the refinement normal matrix and defer updates along weakly constrained directions until sufficient constraints reappear. Experiments on public benchmarks, controlled stress tests, and real-world deployments demonstrate accurate and stable tracking with KB-level priors from heterogeneous map sources, including under geometrically degenerate and sustained occlusion and in the presence of gradual scene changes.
RMLer: Synthesizing Novel Objects across Diverse Categories via Reinforcement Mixing Learning
Dec 22, 2025Novel object synthesis by integrating distinct textual concepts from diverse categories remains a significant challenge in Text-to-Image (T2I) generation. Existing methods often suffer from insufficient concept mixing, lack of rigorous evaluation, and suboptimal outputs-manifesting as conceptual imbalance, superficial combinations, or mere juxtapositions. To address these limitations, we propose Reinforcement Mixing Learning (RMLer), a framework that formulates cross-category concept fusion as a reinforcement learning problem: mixed features serve as states, mixing strategies as actions, and visual outcomes as rewards. Specifically, we design an MLP-policy network to predict dynamic coefficients for blending cross-category text embeddings. We further introduce visual rewards based on (1) semantic similarity and (2) compositional balance between the fused object and its constituent concepts, optimizing the policy via proximal policy optimization. At inference, a selection strategy leverages these rewards to curate the highest-quality fused objects. Extensive experiments demonstrate RMLer's superiority in synthesizing coherent, high-fidelity objects from diverse categories, outperforming existing methods. Our work provides a robust framework for generating novel visual concepts, with promising applications in film, gaming, and design.
Novel Object Synthesis via Adaptive Text-Image Harmony
Oct 28, 2024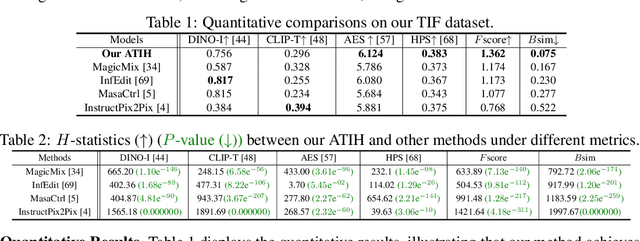
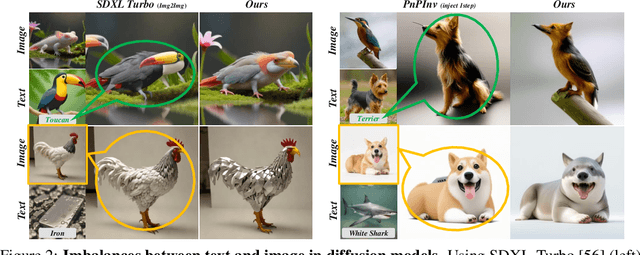
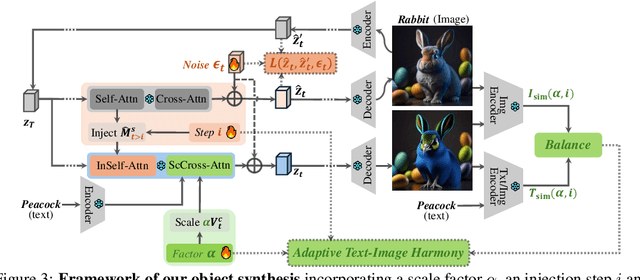
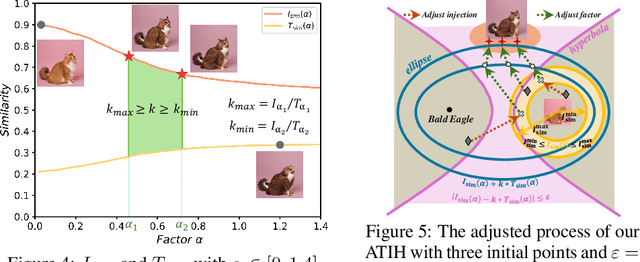
In this paper, we study an object synthesis task that combines an object text with an object image to create a new object image. However, most diffusion models struggle with this task, \textit{i.e.}, often generating an object that predominantly reflects either the text or the image due to an imbalance between their inputs. To address this issue, we propose a simple yet effective method called Adaptive Text-Image Harmony (ATIH) to generate novel and surprising objects. First, we introduce a scale factor and an injection step to balance text and image features in cross-attention and to preserve image information in self-attention during the text-image inversion diffusion process, respectively. Second, to better integrate object text and image, we design a balanced loss function with a noise parameter, ensuring both optimal editability and fidelity of the object image. Third, to adaptively adjust these parameters, we present a novel similarity score function that not only maximizes the similarities between the generated object image and the input text/image but also balances these similarities to harmonize text and image integration. Extensive experiments demonstrate the effectiveness of our approach, showcasing remarkable object creations such as colobus-glass jar. Project page: https://xzr52.github.io/ATIH/.
SC2GAN: Rethinking Entanglement by Self-correcting Correlated GAN Space
Oct 10, 2023Generative Adversarial Networks (GANs) can synthesize realistic images, with the learned latent space shown to encode rich semantic information with various interpretable directions. However, due to the unstructured nature of the learned latent space, it inherits the bias from the training data where specific groups of visual attributes that are not causally related tend to appear together, a phenomenon also known as spurious correlations, e.g., age and eyeglasses or women and lipsticks. Consequently, the learned distribution often lacks the proper modelling of the missing examples. The interpolation following editing directions for one attribute could result in entangled changes with other attributes. To address this problem, previous works typically adjust the learned directions to minimize the changes in other attributes, yet they still fail on strongly correlated features. In this work, we study the entanglement issue in both the training data and the learned latent space for the StyleGAN2-FFHQ model. We propose a novel framework SC$^2$GAN that achieves disentanglement by re-projecting low-density latent code samples in the original latent space and correcting the editing directions based on both the high-density and low-density regions. By leveraging the original meaningful directions and semantic region-specific layers, our framework interpolates the original latent codes to generate images with attribute combination that appears infrequently, then inverts these samples back to the original latent space. We apply our framework to pre-existing methods that learn meaningful latent directions and showcase its strong capability to disentangle the attributes with small amounts of low-density region samples added.
Exploring Gradient-based Multi-directional Controls in GANs
Sep 01, 2022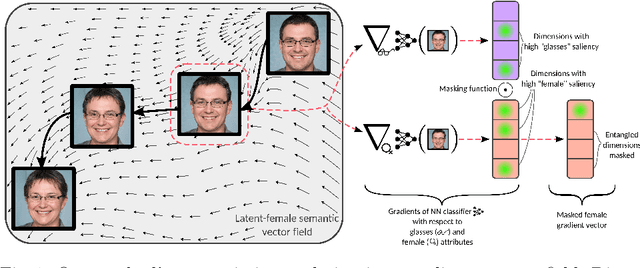

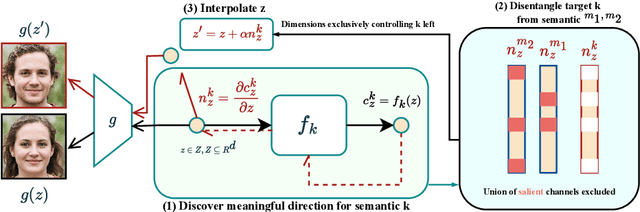

Generative Adversarial Networks (GANs) have been widely applied in modeling diverse image distributions. However, despite its impressive applications, the structure of the latent space in GANs largely remains as a black-box, leaving its controllable generation an open problem, especially when spurious correlations between different semantic attributes exist in the image distributions. To address this problem, previous methods typically learn linear directions or individual channels that control semantic attributes in the image space. However, they often suffer from imperfect disentanglement, or are unable to obtain multi-directional controls. In this work, in light of the above challenges, we propose a novel approach that discovers nonlinear controls, which enables multi-directional manipulation as well as effective disentanglement, based on gradient information in the learned GAN latent space. More specifically, we first learn interpolation directions by following the gradients from classification networks trained separately on the attributes, and then navigate the latent space by exclusively controlling channels activated for the target attribute in the learned directions. Empirically, with small training data, our approach is able to gain fine-grained controls over a diverse set of bi-directional and multi-directional attributes, and we showcase its ability to achieve disentanglement significantly better than state-of-the-art methods both qualitatively and quantitatively.