 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparsifiner: Learning Sparse Instance-Dependent Attention for Efficient Vision Transformers
Mar 24, 2023Vision Transformers (ViT) have shown their competitive advantages performance-wise compared to convolutional neural networks (CNNs) though they often come with high computational costs. To this end, previous methods explore different attention patterns by limiting a fixed number of spatially nearby tokens to accelerate the ViT's multi-head self-attention (MHSA) operations. However, such structured attention patterns limit the token-to-token connections to their spatial relevance, which disregards learned semantic connections from a full attention mask. In this work, we propose a novel approach to learn instance-dependent attention patterns, by devising a lightweight connectivity predictor module to estimate the connectivity score of each pair of tokens. Intuitively, two tokens have high connectivity scores if the features are considered relevant either spatially or semantically. As each token only attends to a small number of other tokens, the binarized connectivity masks are often very sparse by nature and therefore provide the opportunity to accelerate the network via sparse computations. Equipped with the learned unstructured attention pattern, sparse attention ViT (Sparsifiner) produces a superior Pareto-optimal trade-off between FLOPs and top-1 accuracy on ImageNet compared to token sparsity. Our method reduces 48% to 69% FLOPs of MHSA while the accuracy drop is within 0.4%. We also show that combining attention and token sparsity reduces ViT FLOPs by over 60%.
Exploring Gradient-based Multi-directional Controls in GANs
Sep 01, 2022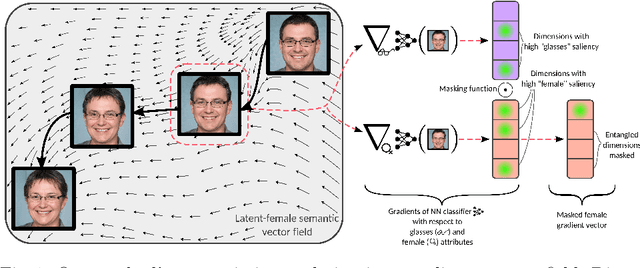

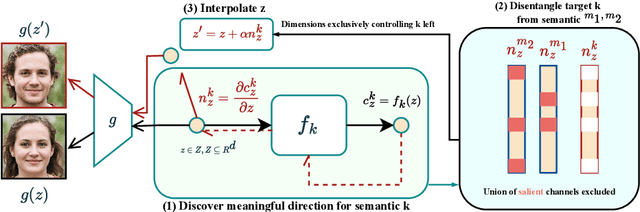

Generative Adversarial Networks (GANs) have been widely applied in modeling diverse image distributions. However, despite its impressive applications, the structure of the latent space in GANs largely remains as a black-box, leaving its controllable generation an open problem, especially when spurious correlations between different semantic attributes exist in the image distributions. To address this problem, previous methods typically learn linear directions or individual channels that control semantic attributes in the image space. However, they often suffer from imperfect disentanglement, or are unable to obtain multi-directional controls. In this work, in light of the above challenges, we propose a novel approach that discovers nonlinear controls, which enables multi-directional manipulation as well as effective disentanglement, based on gradient information in the learned GAN latent space. More specifically, we first learn interpolation directions by following the gradients from classification networks trained separately on the attributes, and then navigate the latent space by exclusively controlling channels activated for the target attribute in the learned directions. Empirically, with small training data, our approach is able to gain fine-grained controls over a diverse set of bi-directional and multi-directional attributes, and we showcase its ability to achieve disentanglement significantly better than state-of-the-art methods both qualitatively and quantitatively.
Real-time Virtual-Try-On from a Single Example Image through Deep Inverse Graphics and Learned Differentiable Renderers
May 12, 2022

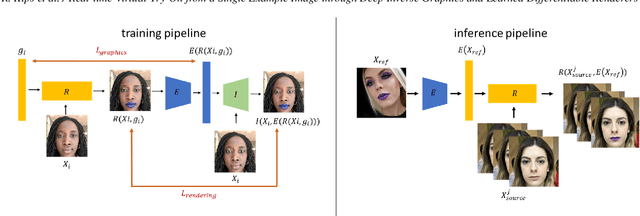

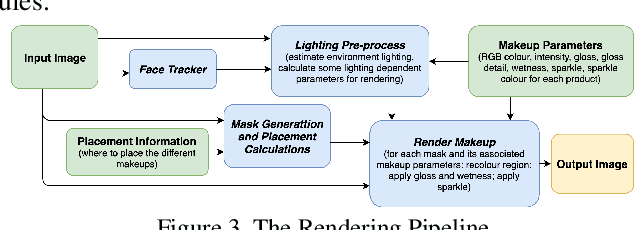
Augmented reality applications have rapidly spread across online platforms, allowing consumers to virtually try-on a variety of products, such as makeup, hair dying, or shoes. However, parametrizing a renderer to synthesize realistic images of a given product remains a challenging task that requires expert knowledge. While recent work has introduced neural rendering methods for virtual try-on from example images, current approaches are based on large generative models that cannot be used in real-time on mobile devices. This calls for a hybrid method that combines the advantages of computer graphics and neural rendering approaches. In this paper we propose a novel framework based on deep learning to build a real-time inverse graphics encoder that learns to map a single example image into the parameter space of a given augmented reality rendering engine. Our method leverages self-supervised learning and does not require labeled training data which makes it extendable to many virtual try-on applications. Furthermore, most augmented reality renderers are not differentiable in practice due to algorithmic choices or implementation constraints to reach real-time on portable devices. To relax the need for a graphics-based differentiable renderer in inverse graphics problems, we introduce a trainable imitator module. Our imitator is a generative network that learns to accurately reproduce the behavior of a given non-differentiable renderer. We propose a novel rendering sensitivity loss to train the imitator, which ensures that the network learns an accurate and continuous representation for each rendering parameter. Our framework enables novel applications where consumers can virtually try-on a novel unknown product from an inspirational reference image on social media. It can also be used by graphics artists to automatically create realistic rendering from a reference product image.
The GIST and RIST of Iterative Self-Training for Semi-Supervised Segmentation
Mar 31, 2021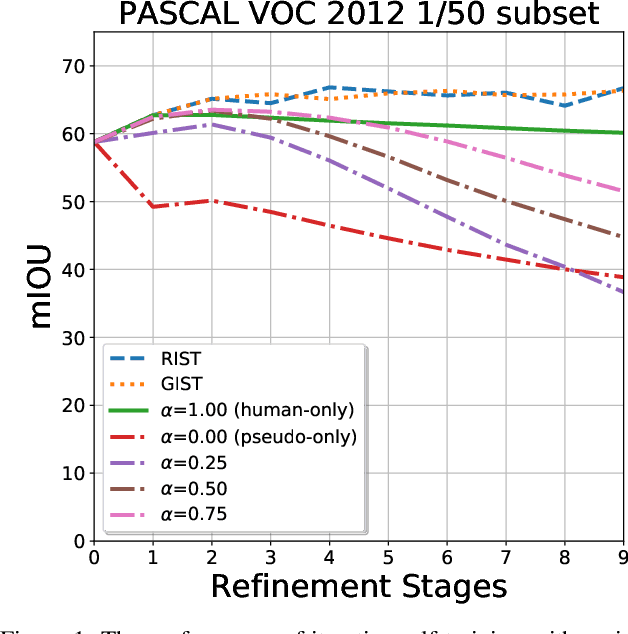
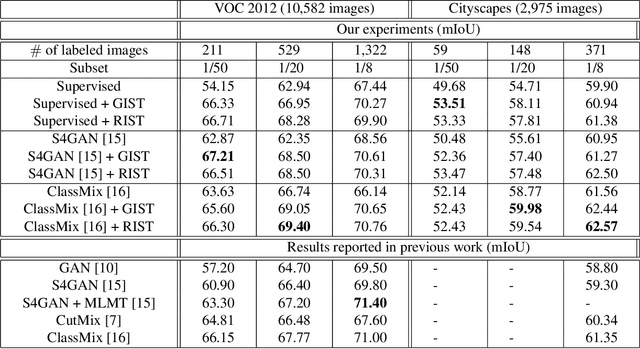

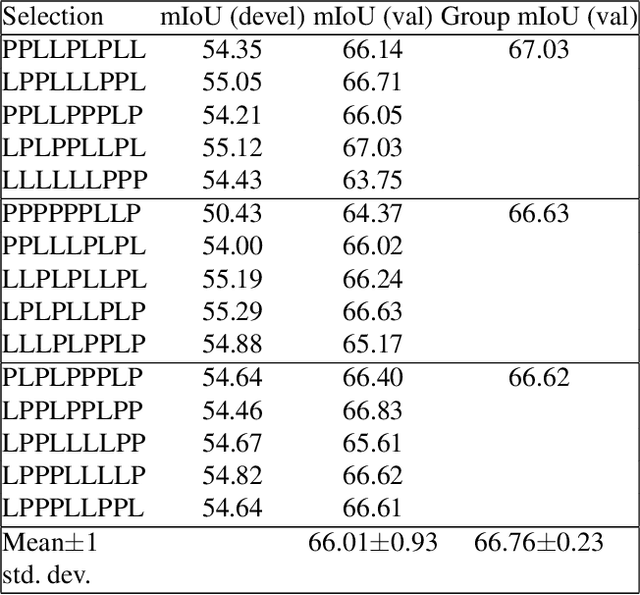
We consider the task of semi-supervised semantic segmentation, where we aim to produce pixel-wise semantic object masks given only a small number of human-labeled training examples. We focus on iterative self-training methods in which we explore the behavior of self-training over multiple refinement stages. We show that iterative self-training leads to performance degradation if done naively with a fixed ratio of human-labeled to pseudo-labeled training examples. We propose Greedy Iterative Self-Training (GIST) and Random Iterative Self-Training (RIST) strategies that alternate between training on either human-labeled data or pseudo-labeled data at each refinement stage, resulting in a performance boost rather than degradation. We further show that GIST and RIST can be combined with existing SOTA methods to boost performance, yielding new SOTA results in Pascal VOC 2012 and Cityscapes dataset across five out of six subsets.
LOHO: Latent Optimization of Hairstyles via Orthogonalization
Mar 10, 2021
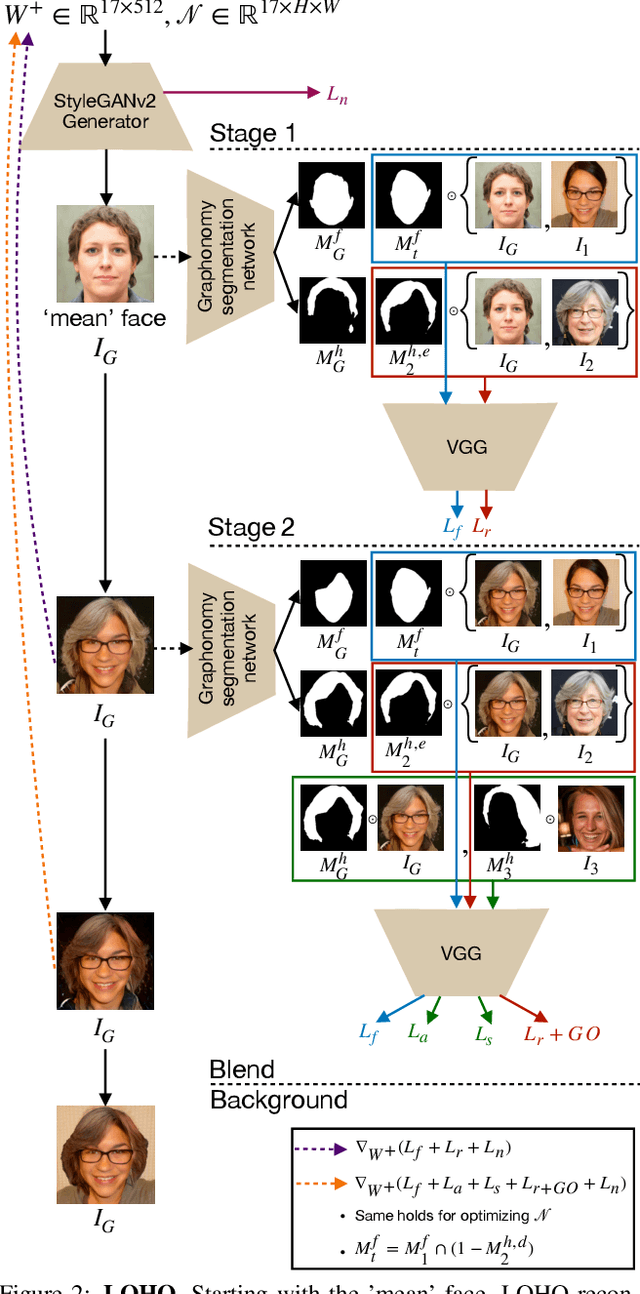


Hairstyle transfer is challenging due to hair structure differences in the source and target hair. Therefore, we propose Latent Optimization of Hairstyles via Orthogonalization (LOHO), an optimization-based approach using GAN inversion to infill missing hair structure details in latent space during hairstyle transfer. Our approach decomposes hair into three attributes: perceptual structure, appearance, and style, and includes tailored losses to model each of these attributes independently. Furthermore, we propose two-stage optimization and gradient orthogonalization to enable disentangled latent space optimization of our hair attributes. Using LOHO for latent space manipulation, users can synthesize novel photorealistic images by manipulating hair attributes either individually or jointly, transferring the desired attributes from reference hairstyles. LOHO achieves a superior FID compared with the current state-of-the-art (SOTA) for hairstyle transfer. Additionally, LOHO preserves the subject's identity comparably well according to PSNR and SSIM when compared to SOTA image embedding pipelines. Code is available at https://github.com/dukebw/LOHO.
SSTVOS: Sparse Spatiotemporal Transformers for Video Object Segmentation
Jan 21, 2021
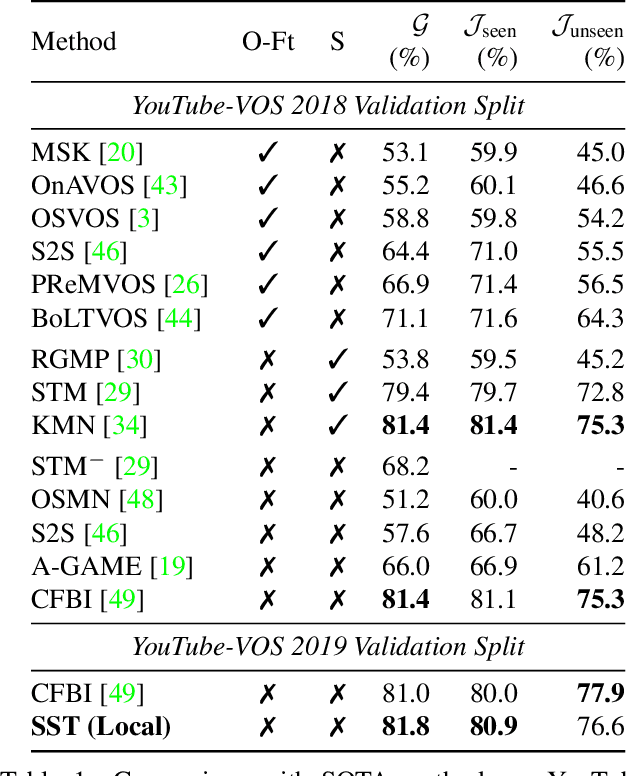
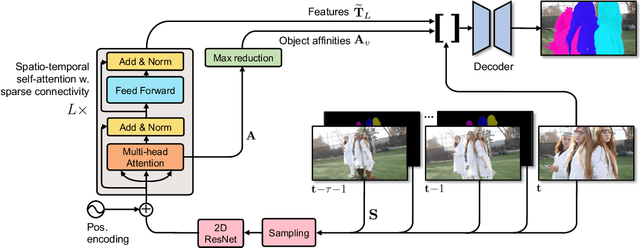
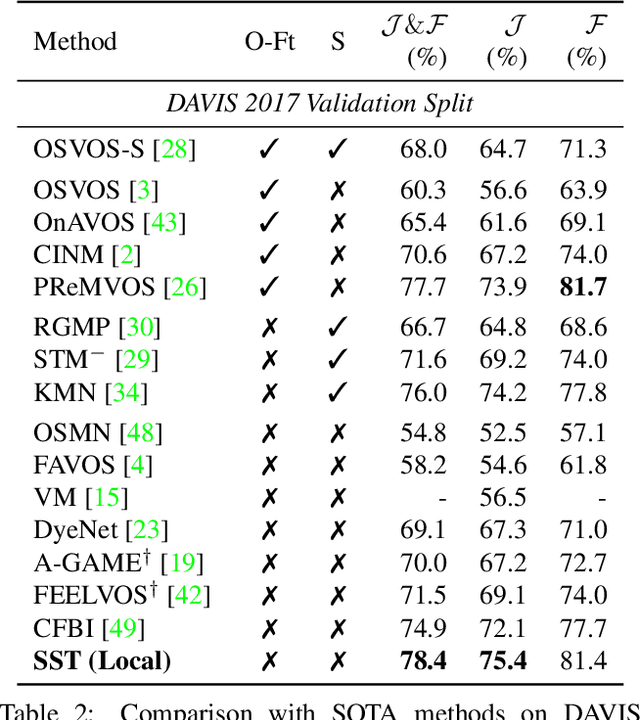
In this paper we introduce a Transformer-based approach to video object segmentation (VOS). To address compounding error and scalability issues of prior work, we propose a scalable, end-to-end method for VOS called Sparse Spatiotemporal Transformers (SST). SST extracts per-pixel representations for each object in a video using sparse attention over spatiotemporal features. Our attention-based formulation for VOS allows a model to learn to attend over a history of multiple frames and provides suitable inductive bias for performing correspondence-like computations necessary for solving motion segmentation. We demonstrate the effectiveness of attention-based over recurrent networks in the spatiotemporal domain. Our method achieves competitive results on YouTube-VOS and DAVIS 2017 with improved scalability and robustness to occlusions compared with the state of the art.
Lightweight Real-time Makeup Try-on in Mobile Browsers with Tiny CNN Models for Facial Tracking
Jun 11, 2019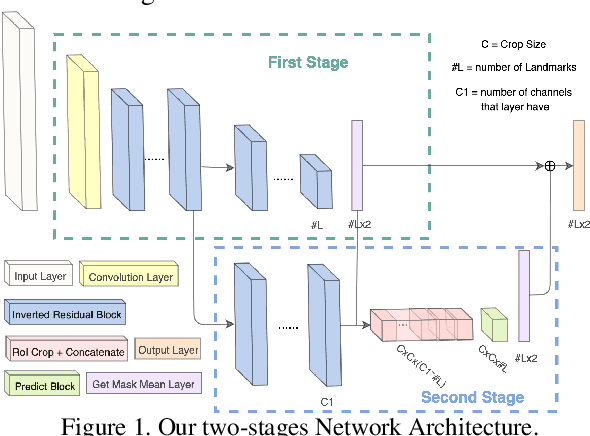

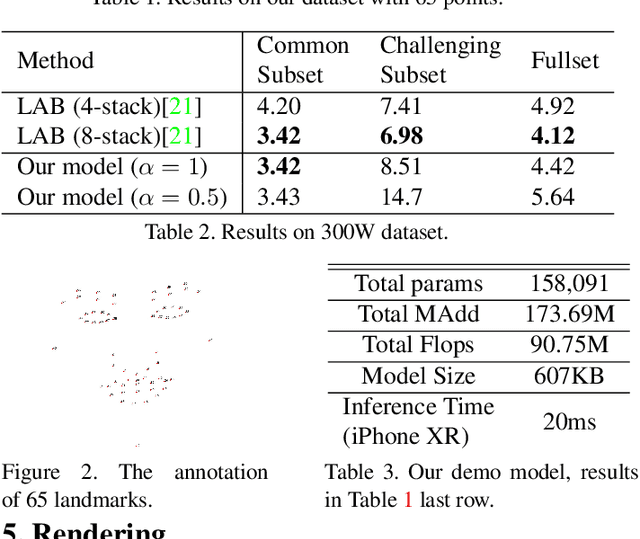
Recent works on convolutional neural networks (CNNs) for facial alignment have demonstrated unprecedented accuracy on a variety of large, publicly available datasets. However, the developed models are often both cumbersome and computationally expensive, and are not adapted to applications on resource restricted devices. In this work, we look into developing and training compact facial alignment models that feature fast inference speed and small deployment size, making them suitable for applications on the aforementioned category of devices. Our main contribution lies in designing such small models while maintaining high accuracy of facial alignment. The models we propose make use of light CNN architectures adapted to the facial alignment problem for accurate two-stage prediction of facial landmark coordinates from low-resolution output heatmaps. We further combine the developed facial tracker with a rendering method, and build a real-time makeup try-on demo that runs client-side in smartphone Web browsers. More results and demo are in our project page: http://research.modiface.com/makeup-try-on-cvprw2019/
Nail Polish Try-On: Realtime Semantic Segmentation of Small Objects for Native and Browser Smartphone AR Applications
Jun 10, 2019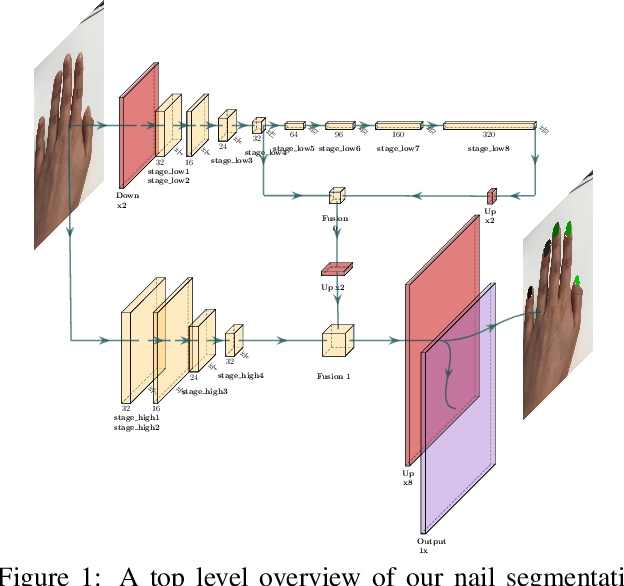
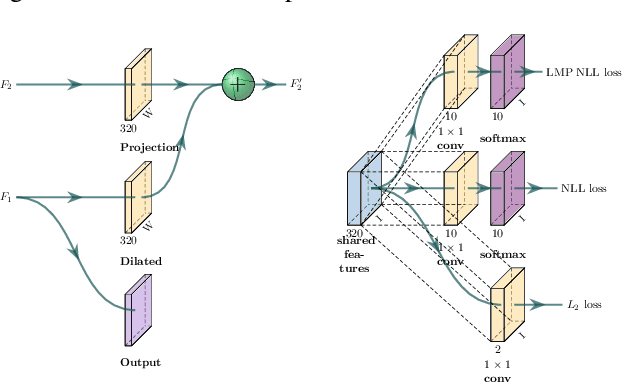
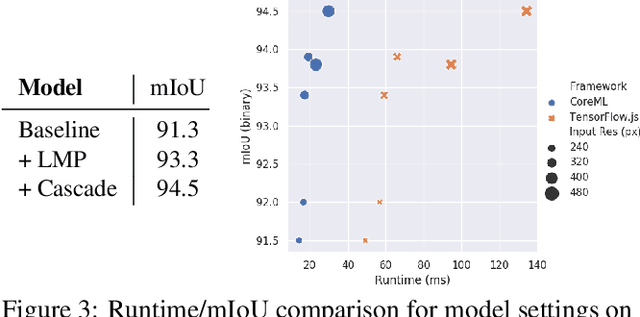
We provide a system for semantic segmentation of small objects that enables nail polish try-on AR applications to run client-side in realtime in native and web mobile applications. By adjusting input resolution and neural network depth, our model design enables a smooth trade-off of performance and runtime, with the highest performance setting achieving~\num{94.5} mIoU at 29.8ms runtime in native applications on an iPad Pro. We also provide a postprocessing and rendering algorithm for nail polish try-on, which integrates with our semantic segmentation and fingernail base-tip direction predictions.
Generalized Hadamard-Product Fusion Operators for Visual Question Answering
Apr 06, 2018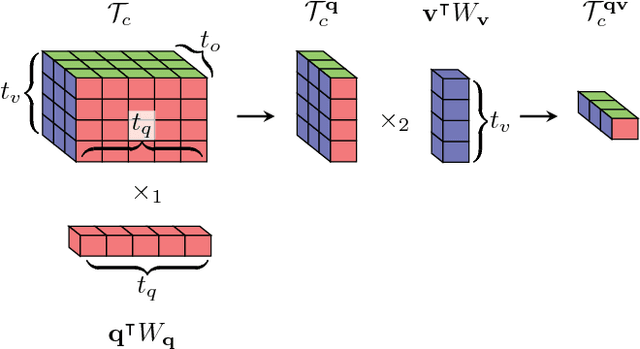
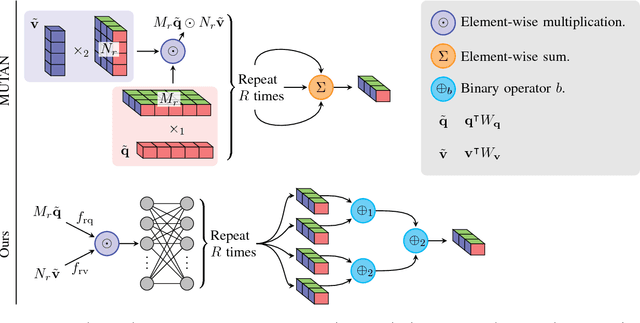
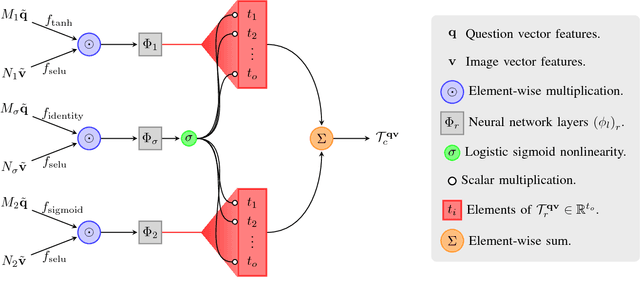
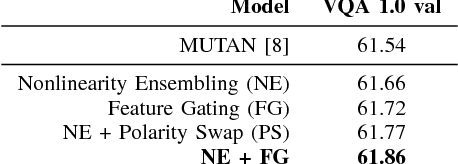
We propose a generalized class of multimodal fusion operators for the task of visual question answering (VQA). We identify generalizations of existing multimodal fusion operators based on the Hadamard product, and show that specific non-trivial instantiations of this generalized fusion operator exhibit superior performance in terms of OpenEnded accuracy on the VQA task. In particular, we introduce Nonlinearity Ensembling, Feature Gating, and post-fusion neural network layers as fusion operator components, culminating in an absolute percentage point improvement of $1.1\%$ on the VQA 2.0 test-dev set over baseline fusion operators, which use the same features as input. We use our findings as evidence that our generalized class of fusion operators could lead to the discovery of even superior task-specific operators when used as a search space in an architecture search over fusion operators.