 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Graphics Encoder for Real-Time Video Makeup Synthesis from Example
May 12, 2021

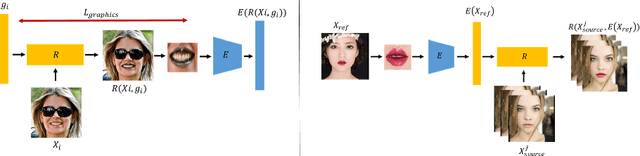
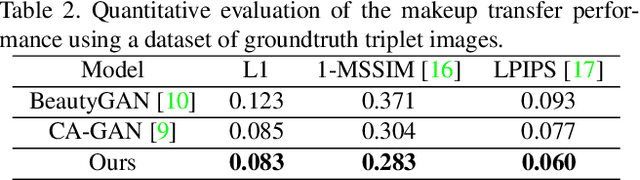
While makeup virtual-try-on is now widespread, parametrizing a computer graphics rendering engine for synthesizing images of a given cosmetics product remains a challenging task. In this paper, we introduce an inverse computer graphics method for automatic makeup synthesis from a reference image, by learning a model that maps an example portrait image with makeup to the space of rendering parameters. This method can be used by artists to automatically create realistic virtual cosmetics image samples, or by consumers, to virtually try-on a makeup extracted from their favorite reference image.
Lightweight Real-time Makeup Try-on in Mobile Browsers with Tiny CNN Models for Facial Tracking
Jun 11, 2019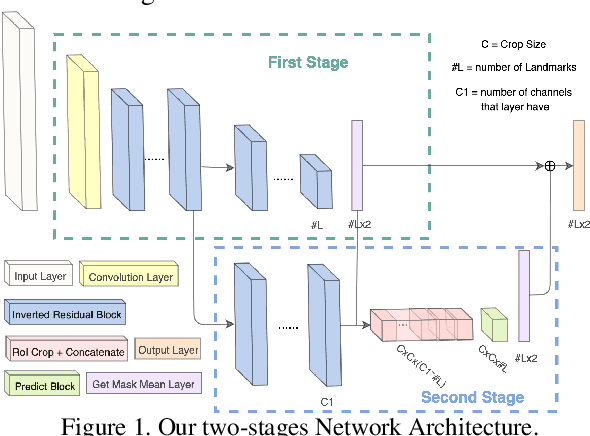

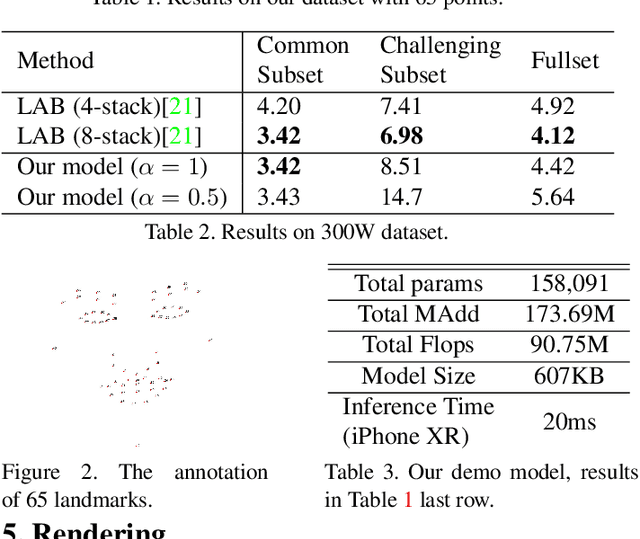
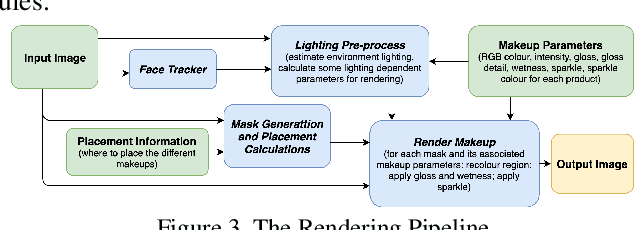
Recent works on convolutional neural networks (CNNs) for facial alignment have demonstrated unprecedented accuracy on a variety of large, publicly available datasets. However, the developed models are often both cumbersome and computationally expensive, and are not adapted to applications on resource restricted devices. In this work, we look into developing and training compact facial alignment models that feature fast inference speed and small deployment size, making them suitable for applications on the aforementioned category of devices. Our main contribution lies in designing such small models while maintaining high accuracy of facial alignment. The models we propose make use of light CNN architectures adapted to the facial alignment problem for accurate two-stage prediction of facial landmark coordinates from low-resolution output heatmaps. We further combine the developed facial tracker with a rendering method, and build a real-time makeup try-on demo that runs client-side in smartphone Web browsers. More results and demo are in our project page: http://research.modiface.com/makeup-try-on-cvprw2019/
Nail Polish Try-On: Realtime Semantic Segmentation of Small Objects for Native and Browser Smartphone AR Applications
Jun 10, 2019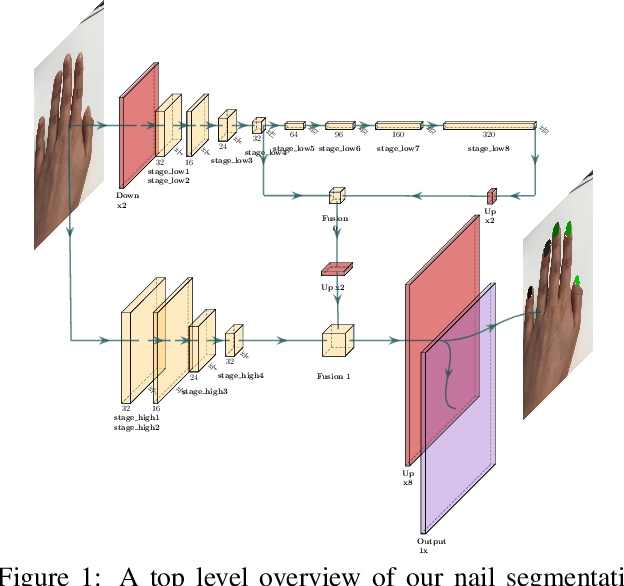
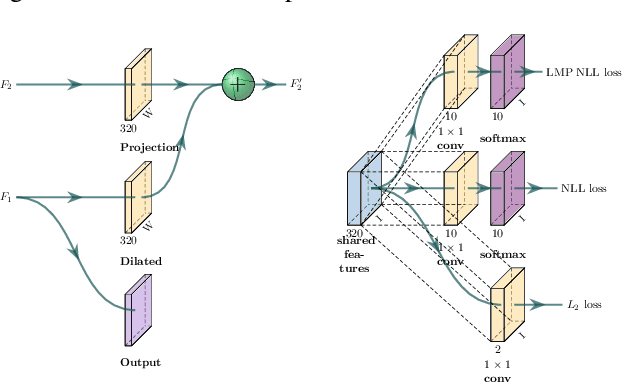
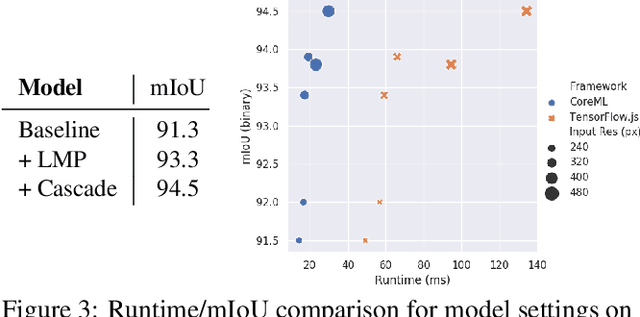
We provide a system for semantic segmentation of small objects that enables nail polish try-on AR applications to run client-side in realtime in native and web mobile applications. By adjusting input resolution and neural network depth, our model design enables a smooth trade-off of performance and runtime, with the highest performance setting achieving~\num{94.5} mIoU at 29.8ms runtime in native applications on an iPad Pro. We also provide a postprocessing and rendering algorithm for nail polish try-on, which integrates with our semantic segmentation and fingernail base-tip direction predictions.
Real-time deep hair matting on mobile devices
Jan 10, 2018
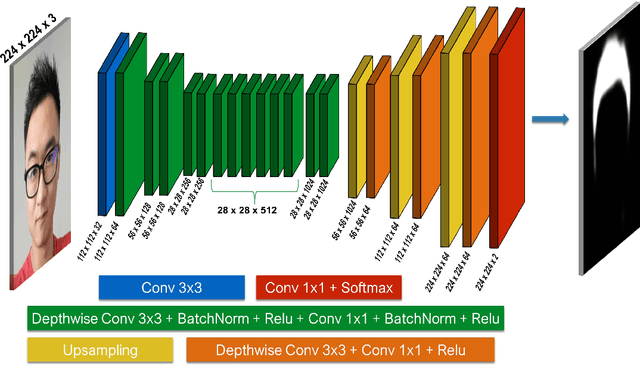

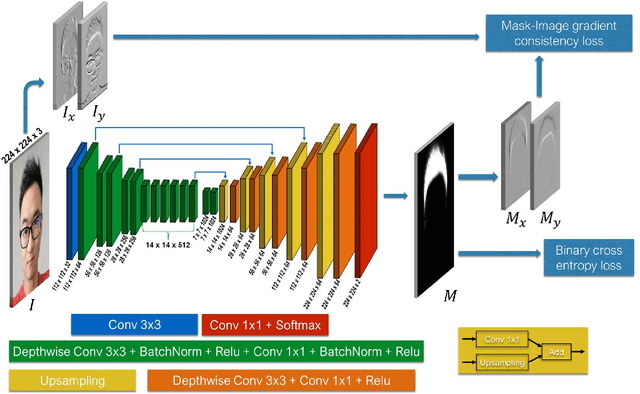
Augmented reality is an emerging technology in many application domains. Among them is the beauty industry, where live virtual try-on of beauty products is of great importance. In this paper, we address the problem of live hair color augmentation. To achieve this goal, hair needs to be segmented quickly and accurately. We show how a modified MobileNet CNN architecture can be used to segment the hair in real-time. Instead of training this network using large amounts of accurate segmentation data, which is difficult to obtain, we use crowd sourced hair segmentation data. While such data is much simpler to obtain, the segmentations there are noisy and coarse. Despite this, we show how our system can produce accurate and fine-detailed hair mattes, while running at over 30 fps on an iPad Pro tablet.
Hybrid eye center localization using cascaded regression and hand-crafted model fitting
Dec 07, 2017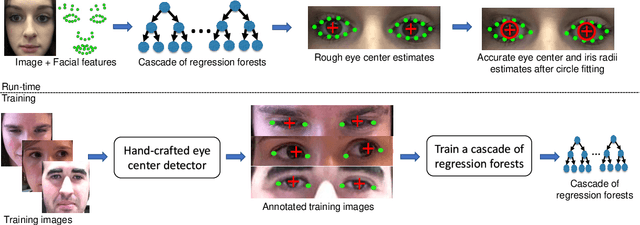
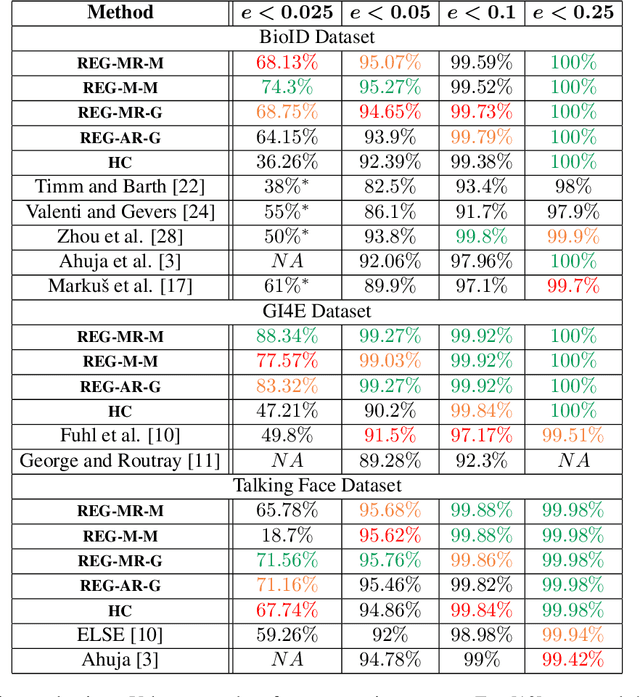

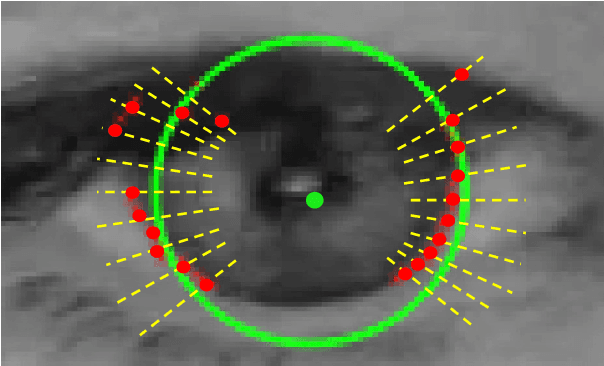
We propose a new cascaded regressor for eye center detection. Previous methods start from a face or an eye detector and use either advanced features or powerful regressors for eye center localization, but not both. Instead, we detect the eyes more accurately using an existing facial feature alignment method. We improve the robustness of localization by using both advanced features and powerful regression machinery. Unlike most other methods that do not refine the regression results, we make the localization more accurate by adding a robust circle fitting post-processing step. Finally, using a simple hand-crafted method for eye center localization, we show how to train the cascaded regressor without the need for manually annotated training data. We evaluate our new approach and show that it achieves state-of-the-art performance on the BioID, GI4E, and the TalkingFace datasets. At an average normalized error of e < 0.05, the regressor trained on manually annotated data yields an accuracy of 95.07% (BioID), 99.27% (GI4E), and 95.68% (TalkingFace). The automatically trained regressor is nearly as good, yielding an accuracy of 93.9% (BioID), 99.27% (GI4E), and 95.46% (TalkingFace).