 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSTVOS: Sparse Spatiotemporal Transformers for Video Object Segmentation
Jan 21, 2021
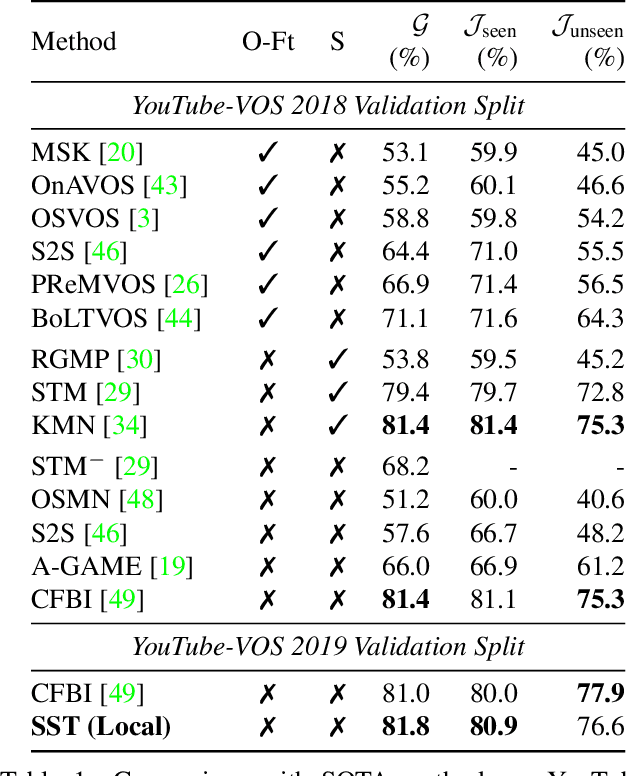
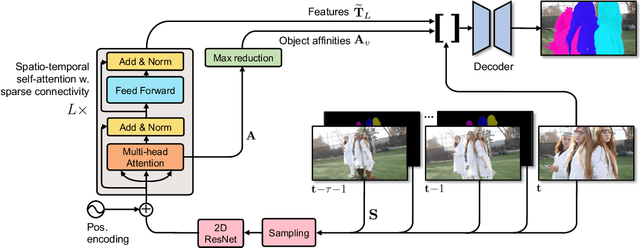
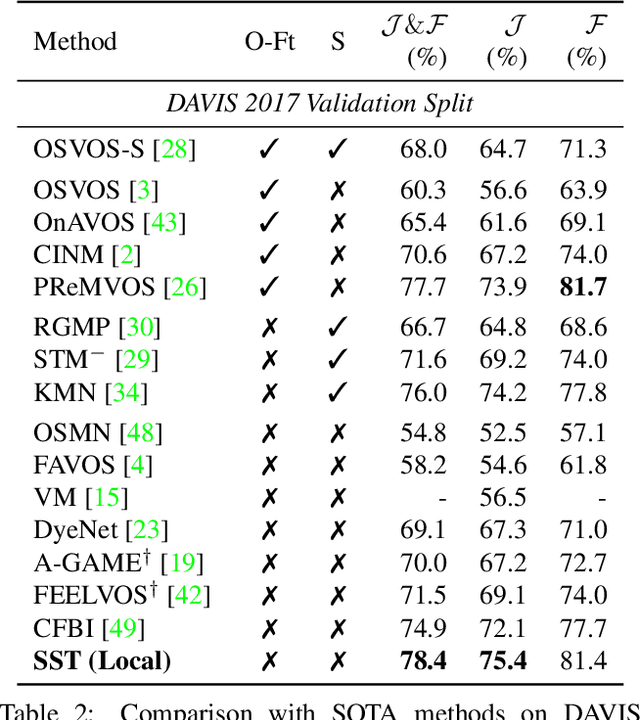
In this paper we introduce a Transformer-based approach to video object segmentation (VOS). To address compounding error and scalability issues of prior work, we propose a scalable, end-to-end method for VOS called Sparse Spatiotemporal Transformers (SST). SST extracts per-pixel representations for each object in a video using sparse attention over spatiotemporal features. Our attention-based formulation for VOS allows a model to learn to attend over a history of multiple frames and provides suitable inductive bias for performing correspondence-like computations necessary for solving motion segmentation. We demonstrate the effectiveness of attention-based over recurrent networks in the spatiotemporal domain. Our method achieves competitive results on YouTube-VOS and DAVIS 2017 with improved scalability and robustness to occlusions compared with the state of the art.
Nail Polish Try-On: Realtime Semantic Segmentation of Small Objects for Native and Browser Smartphone AR Applications
Jun 10, 2019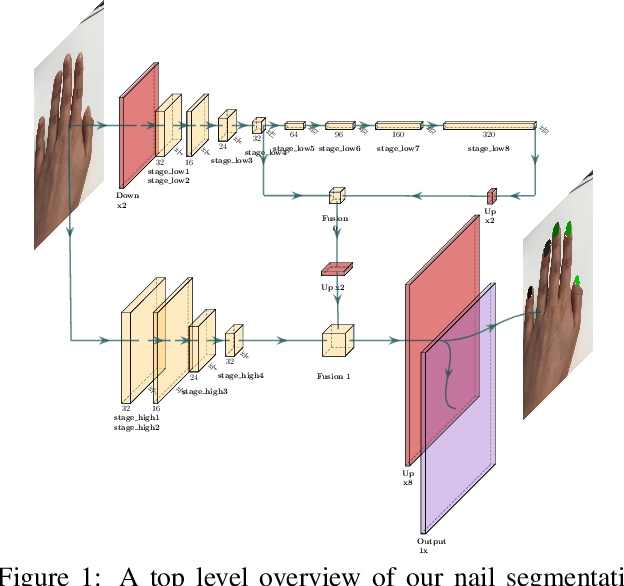
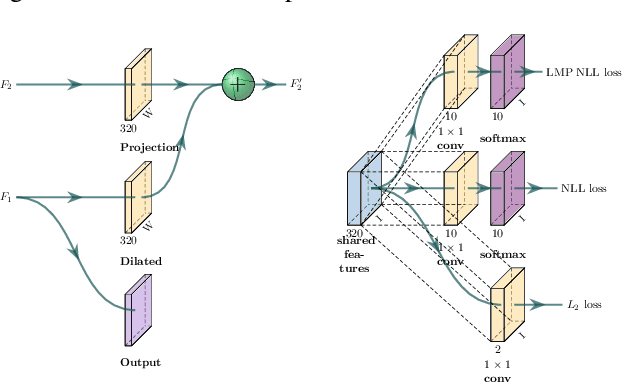
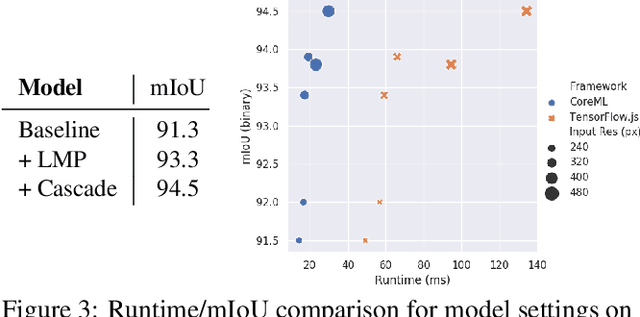
We provide a system for semantic segmentation of small objects that enables nail polish try-on AR applications to run client-side in realtime in native and web mobile applications. By adjusting input resolution and neural network depth, our model design enables a smooth trade-off of performance and runtime, with the highest performance setting achieving~\num{94.5} mIoU at 29.8ms runtime in native applications on an iPad Pro. We also provide a postprocessing and rendering algorithm for nail polish try-on, which integrates with our semantic segmentation and fingernail base-tip direction predictions.