 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-time Virtual-Try-On from a Single Example Image through Deep Inverse Graphics and Learned Differentiable Renderers
May 12, 2022

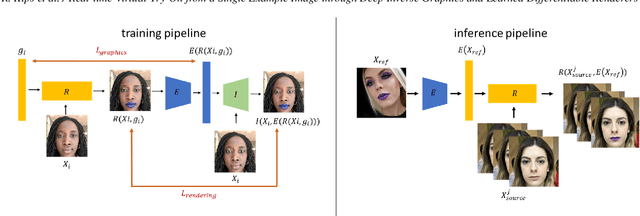

Augmented reality applications have rapidly spread across online platforms, allowing consumers to virtually try-on a variety of products, such as makeup, hair dying, or shoes. However, parametrizing a renderer to synthesize realistic images of a given product remains a challenging task that requires expert knowledge. While recent work has introduced neural rendering methods for virtual try-on from example images, current approaches are based on large generative models that cannot be used in real-time on mobile devices. This calls for a hybrid method that combines the advantages of computer graphics and neural rendering approaches. In this paper we propose a novel framework based on deep learning to build a real-time inverse graphics encoder that learns to map a single example image into the parameter space of a given augmented reality rendering engine. Our method leverages self-supervised learning and does not require labeled training data which makes it extendable to many virtual try-on applications. Furthermore, most augmented reality renderers are not differentiable in practice due to algorithmic choices or implementation constraints to reach real-time on portable devices. To relax the need for a graphics-based differentiable renderer in inverse graphics problems, we introduce a trainable imitator module. Our imitator is a generative network that learns to accurately reproduce the behavior of a given non-differentiable renderer. We propose a novel rendering sensitivity loss to train the imitator, which ensures that the network learns an accurate and continuous representation for each rendering parameter. Our framework enables novel applications where consumers can virtually try-on a novel unknown product from an inspirational reference image on social media. It can also be used by graphics artists to automatically create realistic rendering from a reference product image.
Hair Color Digitization through Imaging and Deep Inverse Graphics
Feb 08, 2022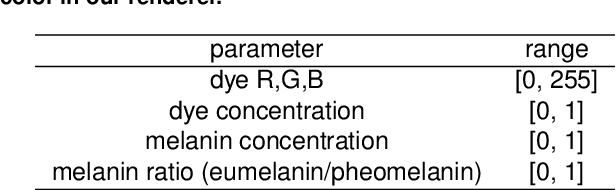


Hair appearance is a complex phenomenon due to hair geometry and how the light bounces on different hair fibers. For this reason, reproducing a specific hair color in a rendering environment is a challenging task that requires manual work and expert knowledge in computer graphics to tune the result visually. While current hair capture methods focus on hair shape estimation many applications could benefit from an automated method for capturing the appearance of a physical hair sample, from augmented/virtual reality to hair dying development. Building on recent advances in inverse graphics and material capture using deep neural networks, we introduce a novel method for hair color digitization. Our proposed pipeline allows capturing the color appearance of a physical hair sample and renders synthetic images of hair with a similar appearance, simulating different hair styles and/or lighting environments. Since rendering realistic hair images requires path-tracing rendering, the conventional inverse graphics approach based on differentiable rendering is untractable. Our method is based on the combination of a controlled imaging device, a path-tracing renderer, and an inverse graphics model based on self-supervised machine learning, which does not require to use differentiable rendering to be trained. We illustrate the performance of our hair digitization method on both real and synthetic images and show that our approach can accurately capture and render hair color.
Deep Graphics Encoder for Real-Time Video Makeup Synthesis from Example
May 12, 2021

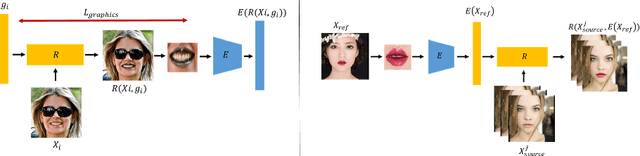
While makeup virtual-try-on is now widespread, parametrizing a computer graphics rendering engine for synthesizing images of a given cosmetics product remains a challenging task. In this paper, we introduce an inverse computer graphics method for automatic makeup synthesis from a reference image, by learning a model that maps an example portrait image with makeup to the space of rendering parameters. This method can be used by artists to automatically create realistic virtual cosmetics image samples, or by consumers, to virtually try-on a makeup extracted from their favorite reference image.
Learning Long-Term Style-Preserving Blind Video Temporal Consistency
Mar 12, 2021
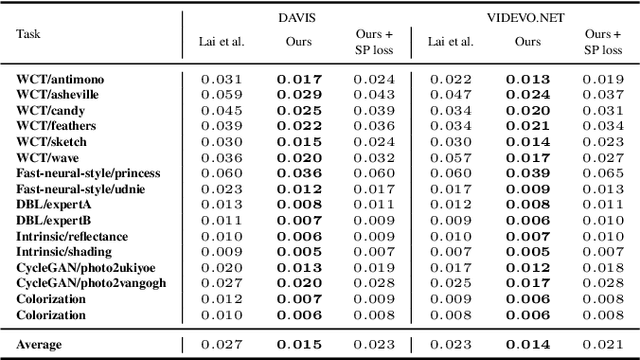

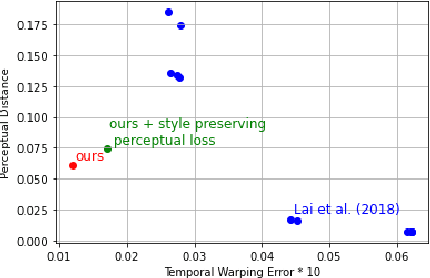
When trying to independently apply image-trained algorithms to successive frames in videos, noxious flickering tends to appear. State-of-the-art post-processing techniques that aim at fostering temporal consistency, generate other temporal artifacts and visually alter the style of videos. We propose a postprocessing model, agnostic to the transformation applied to videos (e.g. style transfer, image manipulation using GANs, etc.), in the form of a recurrent neural network. Our model is trained using a Ping Pong procedure and its corresponding loss, recently introduced for GAN video generation, as well as a novel style preserving perceptual loss. The former improves long-term temporal consistency learning, while the latter fosters style preservation. We evaluate our model on the DAVIS and videvo.net datasets and show that our approach offers state-of-the-art results concerning flicker removal, and better keeps the overall style of the videos than previous approaches.
AgingMapGAN (AMGAN): High-Resolution Controllable Face Aging with Spatially-Aware Conditional GANs
Aug 26, 2020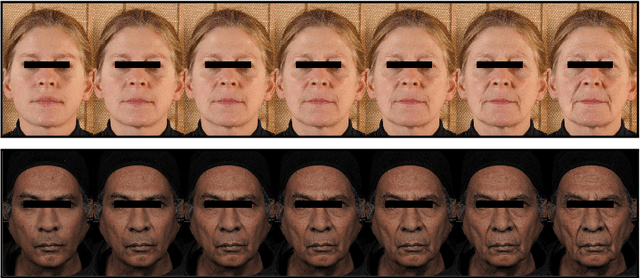
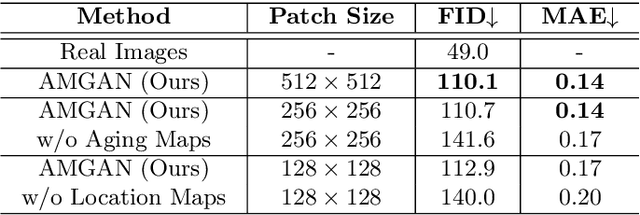


Existing approaches and datasets for face aging produce results skewed towards the mean, with individual variations and expression wrinkles often invisible or overlooked in favor of global patterns such as the fattening of the face. Moreover, they offer little to no control over the way the faces are aged and can difficultly be scaled to large images, thus preventing their usage in many real-world applications. To address these limitations, we present an approach to change the appearance of a high-resolution image using ethnicity-specific aging information and weak spatial supervision to guide the aging process. We demonstrate the advantage of our proposed method in terms of quality, control, and how it can be used on high-definition images while limiting the computational overhead.
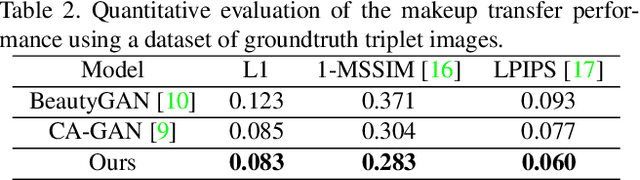
CA-GAN: Weakly Supervised Color Aware GAN for Controllable Makeup Transfer
Aug 24, 2020



While existing makeup style transfer models perform an image synthesis whose results cannot be explicitly controlled, the ability to modify makeup color continuously is a desirable property for virtual try-on applications. We propose a new formulation for the makeup style transfer task, with the objective to learn a color controllable makeup style synthesis. We introduce CA-GAN, a generative model that learns to modify the color of specific objects (e.g. lips or eyes) in the image to an arbitrary target color while preserving background. Since color labels are rare and costly to acquire, our method leverages weakly supervised learning for conditional GANs. This enables to learn a controllable synthesis of complex objects, and only requires a weak proxy of the image attribute that we desire to modify. Finally, we present for the first time a quantitative analysis of makeup style transfer and color control performance.
Scikit-learn: Machine Learning in Python
Jun 05, 2018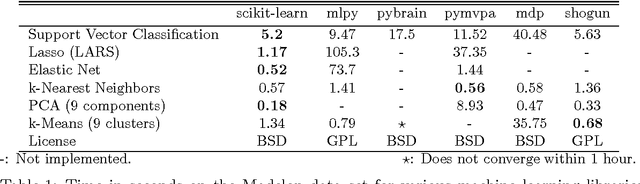
Scikit-learn is a Python module integrating a wide range of state-of-the-art machine learning algorithms for medium-scale supervised and unsupervised problems. This package focuses on bringing machine learning to non-specialists using a general-purpose high-level language. Emphasis is put on ease of use, performance, documentation, and API consistency. It has minimal dependencies and is distributed under the simplified BSD license, encouraging its use in both academic and commercial settings. Source code, binaries, and documentation can be downloaded from http://scikit-learn.org.
* Update authors list and URLs
Classification of MRI data using Deep Learning and Gaussian Process-based Model Selection
Jan 16, 2017
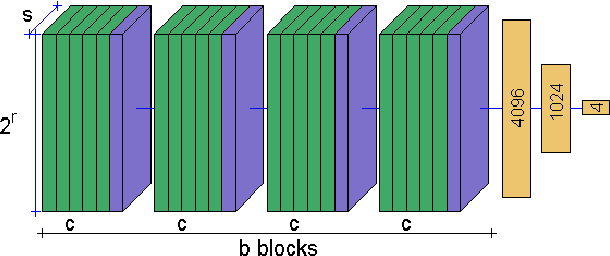
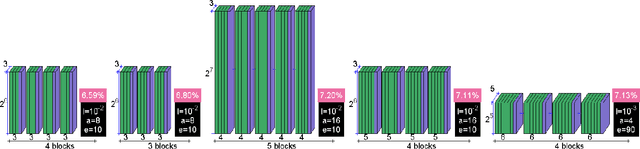
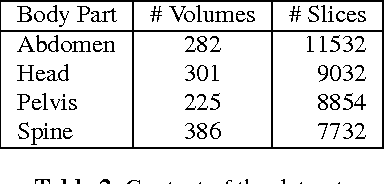
The classification of MRI images according to the anatomical field of view is a necessary task to solve when faced with the increasing quantity of medical images. In parallel, advances in deep learning makes it a suitable tool for computer vision problems. Using a common architecture (such as AlexNet) provides quite good results, but not sufficient for clinical use. Improving the model is not an easy task, due to the large number of hyper-parameters governing both the architecture and the training of the network, and to the limited understanding of their relevance. Since an exhaustive search is not tractable, we propose to optimize the network first by random search, and then by an adaptive search based on Gaussian Processes and Probability of Improvement. Applying this method on a large and varied MRI dataset, we show a substantial improvement between the baseline network and the final one (up to 20\% for the most difficult classes).
Predictive support recovery with TV-Elastic Net penalty and logistic regression: an application to structural MRI
Jul 21, 2014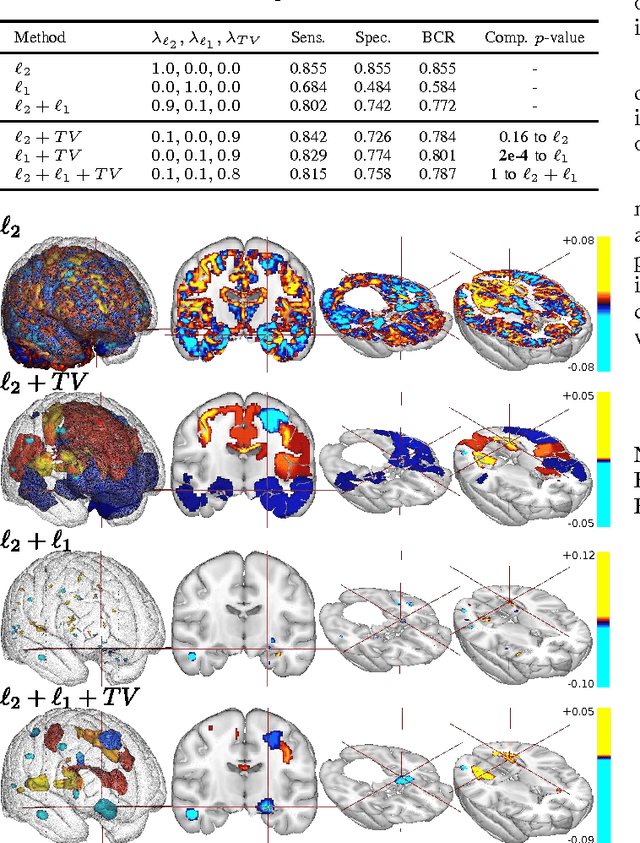
The use of machine-learning in neuroimaging offers new perspectives in early diagnosis and prognosis of brain diseases. Although such multivariate methods can capture complex relationships in the data, traditional approaches provide irregular (l2 penalty) or scattered (l1 penalty) predictive pattern with a very limited relevance. A penalty like Total Variation (TV) that exploits the natural 3D structure of the images can increase the spatial coherence of the weight map. However, TV penalization leads to non-smooth optimization problems that are hard to minimize. We propose an optimization framework that minimizes any combination of l1, l2, and TV penalties while preserving the exact l1 penalty. This algorithm uses Nesterov's smoothing technique to approximate the TV penalty with a smooth function such that the loss and the penalties are minimized with an exact accelerated proximal gradient algorithm. We propose an original continuation algorithm that uses successively smaller values of the smoothing parameter to reach a prescribed precision while achieving the best possible convergence rate. This algorithm can be used with other losses or penalties. The algorithm is applied on a classification problem on the ADNI dataset. We observe that the TV penalty does not necessarily improve the prediction but provides a major breakthrough in terms of support recovery of the predictive brain regions.