 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurvival Models: Proper Scoring Rule and Stochastic Optimization with Competing Risks
Oct 22, 2024When dealing with right-censored data, where some outcomes are missing due to a limited observation period, survival analysis -- known as time-to-event analysis -- focuses on predicting the time until an event of interest occurs. Multiple classes of outcomes lead to a classification variant: predicting the most likely event, a less explored area known as competing risks. Classic competing risks models couple architecture and loss, limiting scalability.To address these issues, we design a strictly proper censoring-adjusted separable scoring rule, allowing optimization on a subset of the data as each observation is evaluated independently. The loss estimates outcome probabilities and enables stochastic optimization for competing risks, which we use for efficient gradient boosting trees. SurvivalBoost not only outperforms 12 state-of-the-art models across several metrics on 4 real-life datasets, both in competing risks and survival settings, but also provides great calibration, the ability to predict across any time horizon, and computation times faster than existing methods.
Teaching Models To Survive: Proper Scoring Rule and Stochastic Optimization with Competing Risks
Jun 20, 2024When data are right-censored, i.e. some outcomes are missing due to a limited period of observation, survival analysis can compute the "time to event". Multiple classes of outcomes lead to a classification variant: predicting the most likely event, known as competing risks, which has been less studied. To build a loss that estimates outcome probabilities for such settings, we introduce a strictly proper censoring-adjusted separable scoring rule that can be optimized on a subpart of the data because the evaluation is made independently of observations. It enables stochastic optimization for competing risks which we use to train gradient boosting trees. Compared to 11 state-of-the-art models, this model, MultiIncidence, performs best in estimating the probability of outcomes in survival and competing risks. It can predict at any time horizon and is much faster than existing alternatives.
Using Feature Grouping as a Stochastic Regularizer for High-Dimensional Noisy Data
Jul 31, 2018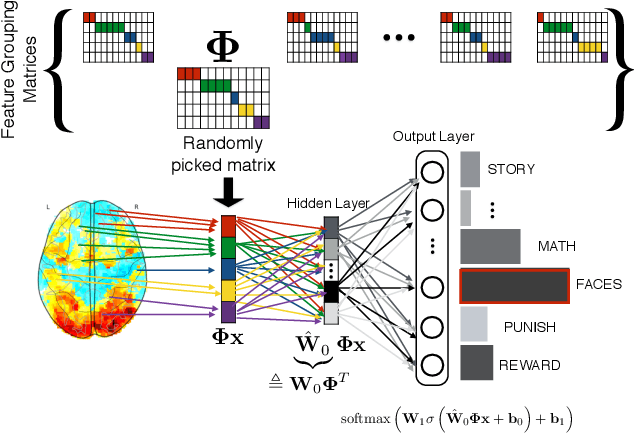



The use of complex models --with many parameters-- is challenging with high-dimensional small-sample problems: indeed, they face rapid overfitting. Such situations are common when data collection is expensive, as in neuroscience, biology, or geology. Dedicated regularization can be crafted to tame overfit, typically via structured penalties. But rich penalties require mathematical expertise and entail large computational costs. Stochastic regularizers such as dropout are easier to implement: they prevent overfitting by random perturbations. Used inside a stochastic optimizer, they come with little additional cost. We propose a structured stochastic regularization that relies on feature grouping. Using a fast clustering algorithm, we define a family of groups of features that capture feature covariations. We then randomly select these groups inside a stochastic gradient descent loop. This procedure acts as a structured regularizer for high-dimensional correlated data without additional computational cost and it has a denoising effect. We demonstrate the performance of our approach for logistic regression both on a sample-limited face image dataset with varying additive noise and on a typical high-dimensional learning problem, brain image classification.
Scikit-learn: Machine Learning in Python
Jun 05, 2018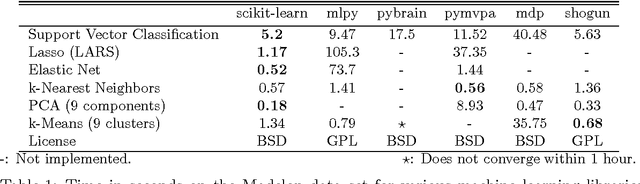
Scikit-learn is a Python module integrating a wide range of state-of-the-art machine learning algorithms for medium-scale supervised and unsupervised problems. This package focuses on bringing machine learning to non-specialists using a general-purpose high-level language. Emphasis is put on ease of use, performance, documentation, and API consistency. It has minimal dependencies and is distributed under the simplified BSD license, encouraging its use in both academic and commercial settings. Source code, binaries, and documentation can be downloaded from http://scikit-learn.org.
* Update authors list and URLs
API design for machine learning software: experiences from the scikit-learn project
Sep 01, 2013Scikit-learn is an increasingly popular machine learning li- brary. Written in Python, it is designed to be simple and efficient, accessible to non-experts, and reusable in various contexts. In this paper, we present and discuss our design choices for the application programming interface (API) of the project. In particular, we describe the simple and elegant interface shared by all learning and processing units in the library and then discuss its advantages in terms of composition and reusability. The paper also comments on implementation details specific to the Python ecosystem and analyzes obstacles faced by users and developers of the library.