 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage-Model Prior Overcomes Cold-Start Items
Nov 13, 2024
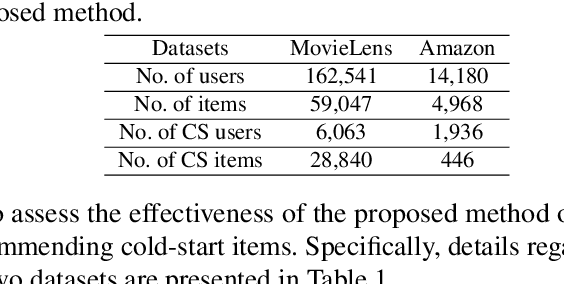
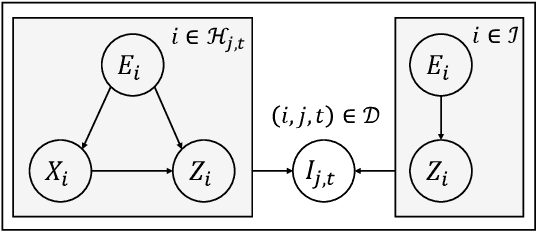

The growth of recommender systems (RecSys) is driven by digitization and the need for personalized content in areas such as e-commerce and video streaming. The content in these systems often changes rapidly and therefore they constantly face the ongoing cold-start problem, where new items lack interaction data and are hard to value. Existing solutions for the cold-start problem, such as content-based recommenders and hybrid methods, leverage item metadata to determine item similarities. The main challenge with these methods is their reliance on structured and informative metadata to capture detailed item similarities, which may not always be available. This paper introduces a novel approach for cold-start item recommendation that utilizes the language model (LM) to estimate item similarities, which are further integrated as a Bayesian prior with classic recommender systems. This approach is generic and able to boost the performance of various recommenders. Specifically, our experiments integrate it with both sequential and collaborative filtering-based recommender and evaluate it on two real-world datasets, demonstrating the enhanced performance of the proposed approach.
Auto-GDA: Automatic Domain Adaptation for Efficient Grounding Verification in Retrieval Augmented Generation
Oct 04, 2024



While retrieval augmented generation (RAG) has been shown to enhance factuality of large language model (LLM) outputs, LLMs still suffer from hallucination, generating incorrect or irrelevant information. One common detection strategy involves prompting the LLM again to assess whether its response is grounded in the retrieved evidence, but this approach is costly. Alternatively, lightweight natural language inference (NLI) models for efficient grounding verification can be used at inference time. While existing pre-trained NLI models offer potential solutions, their performance remains subpar compared to larger models on realistic RAG inputs. RAG inputs are more complex than most datasets used for training NLI models and have characteristics specific to the underlying knowledge base, requiring adaptation of the NLI models to a specific target domain. Additionally, the lack of labeled instances in the target domain makes supervised domain adaptation, e.g., through fine-tuning, infeasible. To address these challenges, we introduce Automatic Generative Domain Adaptation (Auto-GDA). Our framework enables unsupervised domain adaptation through synthetic data generation. Unlike previous methods that rely on handcrafted filtering and augmentation strategies, Auto-GDA employs an iterative process to continuously improve the quality of generated samples using weak labels from less efficient teacher models and discrete optimization to select the most promising augmented samples. Experimental results demonstrate the effectiveness of our approach, with models fine-tuned on synthetic data using Auto-GDA often surpassing the performance of the teacher model and reaching the performance level of LLMs at 10 % of their computational cost.
Membership Inference Attacks on Diffusion Models via Quantile Regression
Dec 08, 2023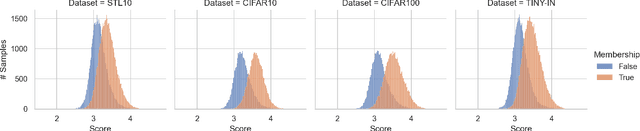


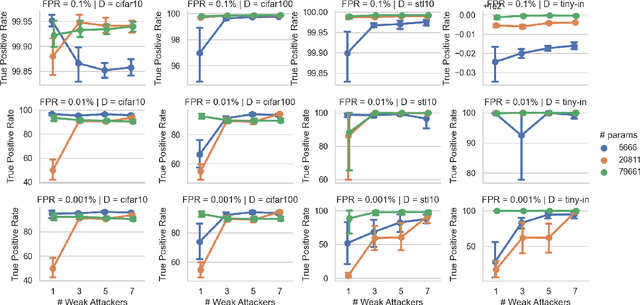
Recently, diffusion models have become popular tools for image synthesis because of their high-quality outputs. However, like other large-scale models, they may leak private information about their training data. Here, we demonstrate a privacy vulnerability of diffusion models through a \emph{membership inference (MI) attack}, which aims to identify whether a target example belongs to the training set when given the trained diffusion model. Our proposed MI attack learns quantile regression models that predict (a quantile of) the distribution of reconstruction loss on examples not used in training. This allows us to define a granular hypothesis test for determining the membership of a point in the training set, based on thresholding the reconstruction loss of that point using a custom threshold tailored to the example. We also provide a simple bootstrap technique that takes a majority membership prediction over ``a bag of weak attackers'' which improves the accuracy over individual quantile regression models. We show that our attack outperforms the prior state-of-the-art attack while being substantially less computationally expensive -- prior attacks required training multiple ``shadow models'' with the same architecture as the model under attack, whereas our attack requires training only much smaller models.
Beta quantile regression for robust estimation of uncertainty in the presence of outliers
Sep 14, 2023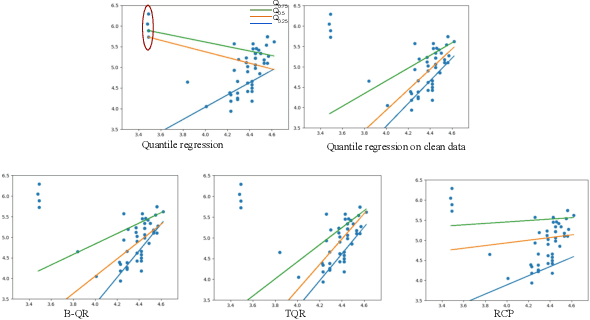
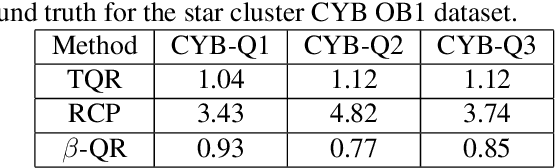
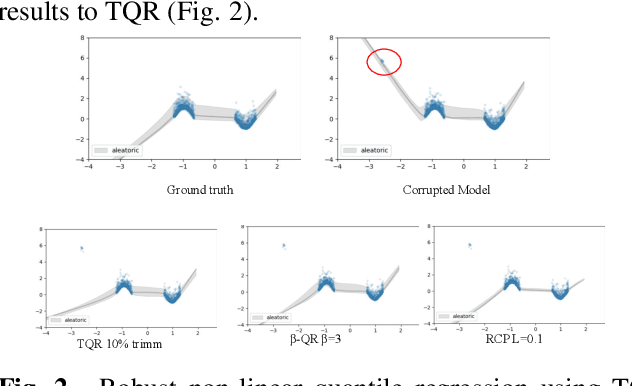
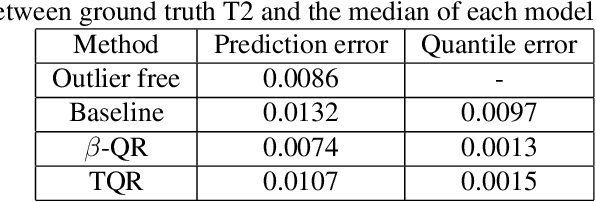
Quantile Regression (QR) can be used to estimate aleatoric uncertainty in deep neural networks and can generate prediction intervals. Quantifying uncertainty is particularly important in critical applications such as clinical diagnosis, where a realistic assessment of uncertainty is essential in determining disease status and planning the appropriate treatment. The most common application of quantile regression models is in cases where the parametric likelihood cannot be specified. Although quantile regression is quite robust to outlier response observations, it can be sensitive to outlier covariate observations (features). Outlier features can compromise the performance of deep learning regression problems such as style translation, image reconstruction, and deep anomaly detection, potentially leading to misleading conclusions. To address this problem, we propose a robust solution for quantile regression that incorporates concepts from robust divergence. We compare the performance of our proposed method with (i) least trimmed quantile regression and (ii) robust regression based on the regularization of case-specific parameters in a simple real dataset in the presence of outlier. These methods have not been applied in a deep learning framework. We also demonstrate the applicability of the proposed method by applying it to a medical imaging translation task using diffusion models.
Improved Differentially Private Regression via Gradient Boosting
Mar 06, 2023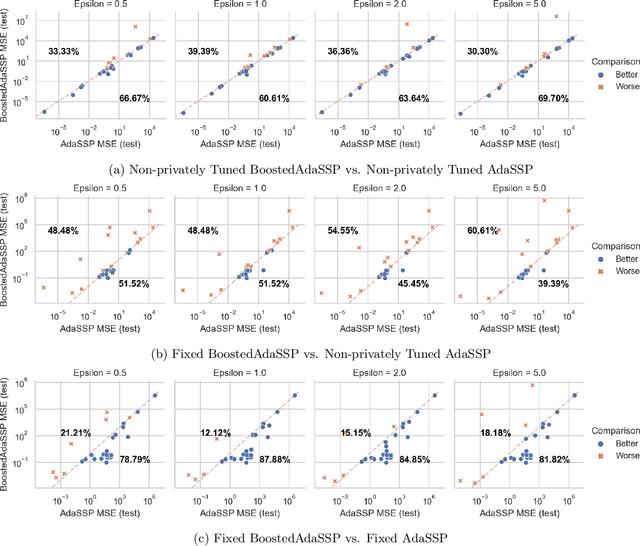
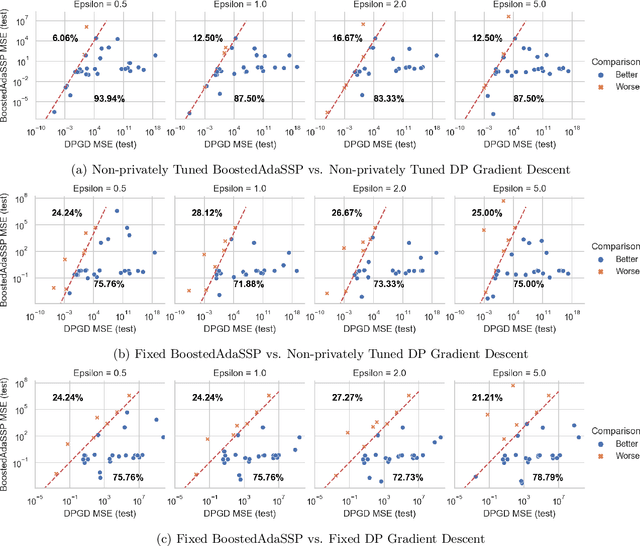
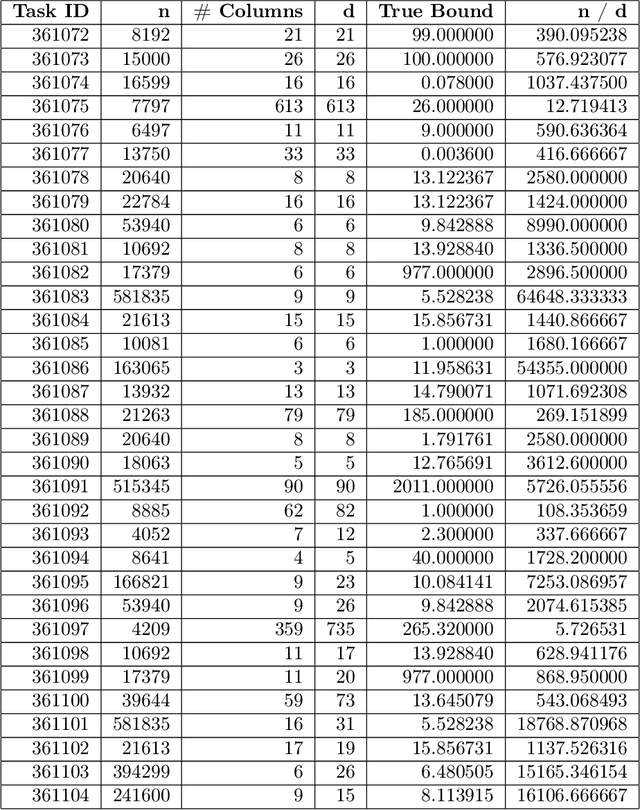
We revisit the problem of differentially private squared error linear regression. We observe that existing state-of-the-art methods are sensitive to the choice of hyper-parameters -- including the ``clipping threshold'' that cannot be set optimally in a data-independent way. We give a new algorithm for private linear regression based on gradient boosting. We show that our method consistently improves over the previous state of the art when the clipping threshold is taken to be fixed without knowledge of the data, rather than optimized in a non-private way -- and that even when we optimize the clipping threshold non-privately, our algorithm is no worse. In addition to a comprehensive set of experiments, we give theoretical insights to explain this behavior.
Private Synthetic Data for Multitask Learning and Marginal Queries
Sep 15, 2022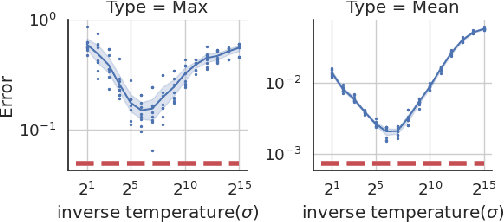

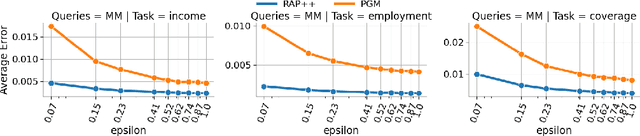

We provide a differentially private algorithm for producing synthetic data simultaneously useful for multiple tasks: marginal queries and multitask machine learning (ML). A key innovation in our algorithm is the ability to directly handle numerical features, in contrast to a number of related prior approaches which require numerical features to be first converted into {high cardinality} categorical features via {a binning strategy}. Higher binning granularity is required for better accuracy, but this negatively impacts scalability. Eliminating the need for binning allows us to produce synthetic data preserving large numbers of statistical queries such as marginals on numerical features, and class conditional linear threshold queries. Preserving the latter means that the fraction of points of each class label above a particular half-space is roughly the same in both the real and synthetic data. This is the property that is needed to train a linear classifier in a multitask setting. Our algorithm also allows us to produce high quality synthetic data for mixed marginal queries, that combine both categorical and numerical features. Our method consistently runs 2-5x faster than the best comparable techniques, and provides significant accuracy improvements in both marginal queries and linear prediction tasks for mixed-type datasets.
Deep Quantile Regression for Uncertainty Estimation in Unsupervised and Supervised Lesion Detection
Sep 20, 2021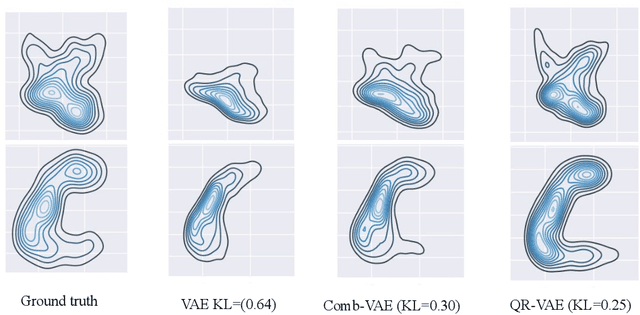

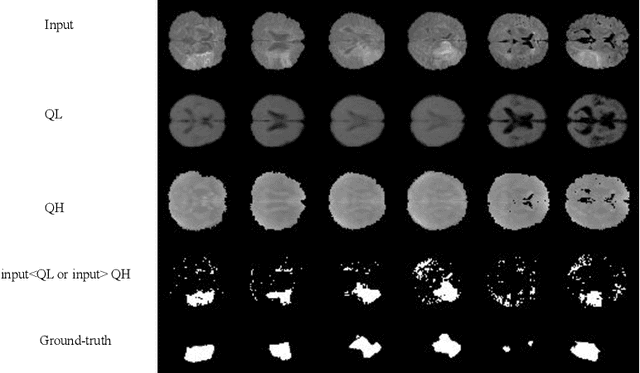

Despite impressive state-of-the-art performance on a wide variety of machine learning tasks in multiple applications, deep learning methods can produce over-confident predictions, particularly with limited training data. Therefore, quantifying uncertainty is particularly important in critical applications such as anomaly or lesion detection and clinical diagnosis, where a realistic assessment of uncertainty is essential in determining surgical margins, disease status and appropriate treatment. In this work, we focus on using quantile regression to estimate aleatoric uncertainty and use it for estimating uncertainty in both supervised and unsupervised lesion detection problems. In the unsupervised settings, we apply quantile regression to a lesion detection task using Variational AutoEncoder (VAE). The VAE models the output as a conditionally independent Gaussian characterized by means and variances for each output dimension. Unfortunately, joint optimization of both mean and variance in the VAE leads to the well-known problem of shrinkage or underestimation of variance. We describe an alternative VAE model, Quantile-Regression VAE (QR-VAE), that avoids this variance shrinkage problem by estimating conditional quantiles for the given input image. Using the estimated quantiles, we compute the conditional mean and variance for input images under the conditionally Gaussian model. We then compute reconstruction probability using this model as a principled approach to outlier or anomaly detection applications. In the supervised setting, we develop binary quantile regression (BQR) for the supervised lesion segmentation task. BQR segmentation can capture uncertainty in label boundaries. We show how quantile regression can be used to characterize expert disagreement in the location of lesion boundaries.
Differentially Private Query Release Through Adaptive Projection
Mar 11, 2021

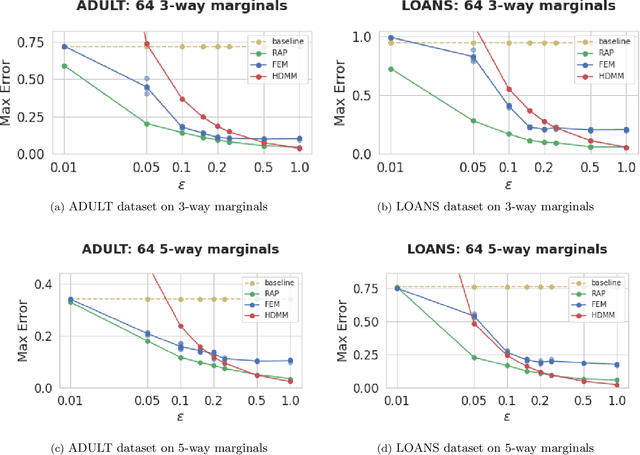
We propose, implement, and evaluate a new algorithm for releasing answers to very large numbers of statistical queries like $k$-way marginals, subject to differential privacy. Our algorithm makes adaptive use of a continuous relaxation of the Projection Mechanism, which answers queries on the private dataset using simple perturbation, and then attempts to find the synthetic dataset that most closely matches the noisy answers. We use a continuous relaxation of the synthetic dataset domain which makes the projection loss differentiable, and allows us to use efficient ML optimization techniques and tooling. Rather than answering all queries up front, we make judicious use of our privacy budget by iteratively and adaptively finding queries for which our (relaxed) synthetic data has high error, and then repeating the projection. We perform extensive experimental evaluations across a range of parameters and datasets, and find that our method outperforms existing algorithms in many cases, especially when the privacy budget is small or the query class is large.
Adversarial Robustness with Non-uniform Perturbations
Feb 24, 2021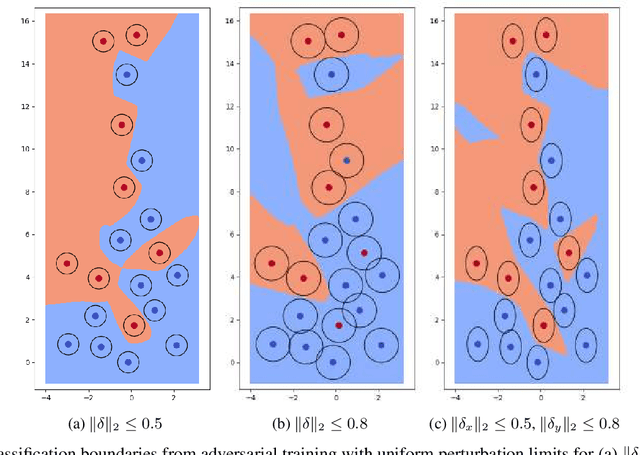
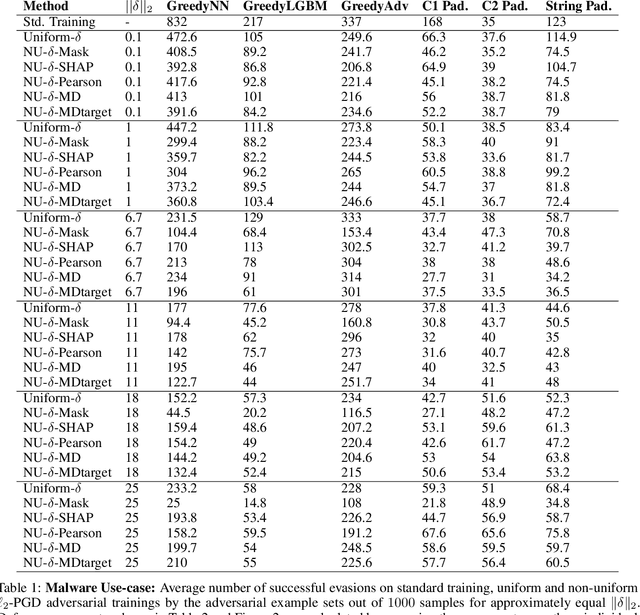
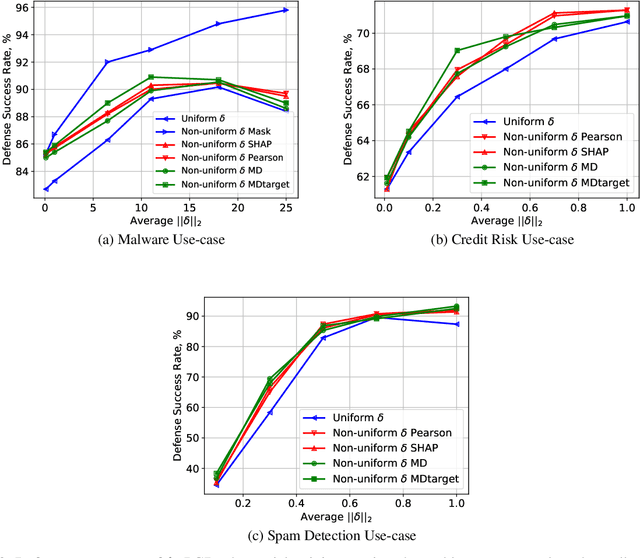
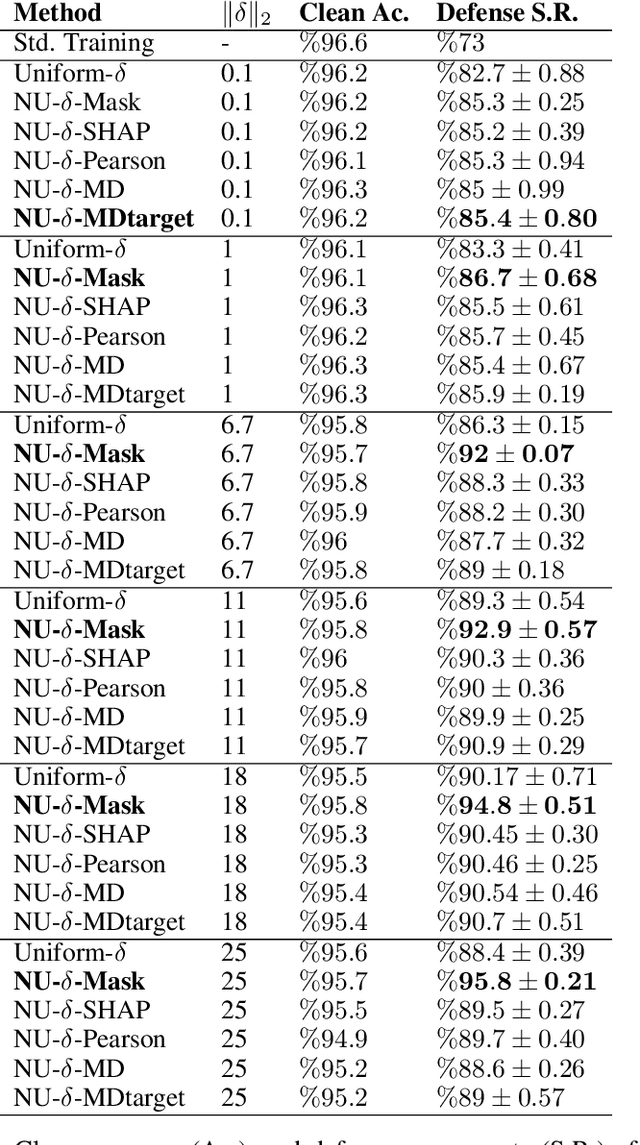
Robustness of machine learning models is critical for security related applications, where real-world adversaries are uniquely focused on evading neural network based detectors. Prior work mainly focus on crafting adversarial examples with small uniform norm-bounded perturbations across features to maintain the requirement of imperceptibility. Although such approaches are valid for images, uniform perturbations do not result in realistic adversarial examples in domains such as malware, finance, and social networks. For these types of applications, features typically have some semantically meaningful dependencies. The key idea of our proposed approach is to enable non-uniform perturbations that can adequately represent these feature dependencies during adversarial training. We propose using characteristics of the empirical data distribution, both on correlations between the features and the importance of the features themselves. Using experimental datasets for malware classification, credit risk prediction, and spam detection, we show that our approach is more robust to real-world attacks. Our approach can be adapted to other domains where non-uniform perturbations more accurately represent realistic adversarial examples.
Addressing Variance Shrinkage in Variational Autoencoders using Quantile Regression
Oct 18, 2020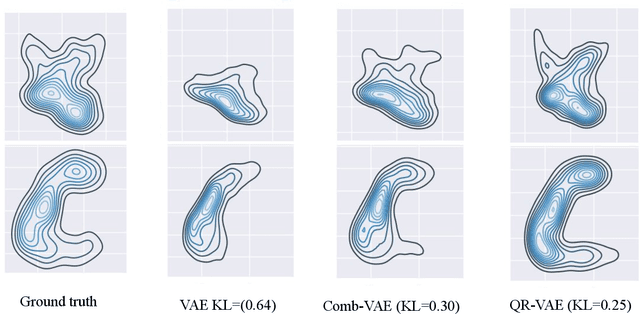
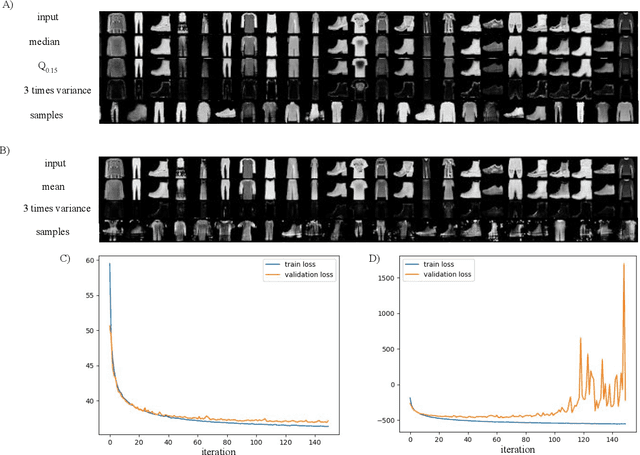
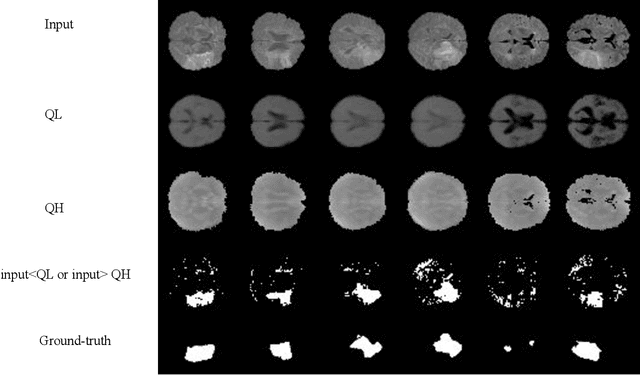
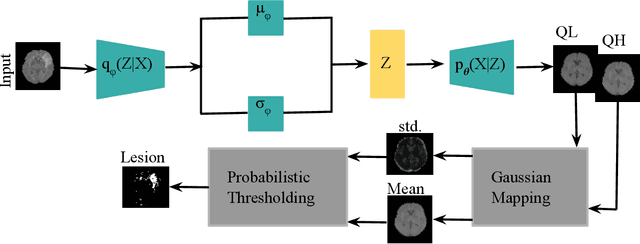
Estimation of uncertainty in deep learning models is of vital importance, especially in medical imaging, where reliance on inference without taking into account uncertainty could lead to misdiagnosis. Recently, the probabilistic Variational AutoEncoder (VAE) has become a popular model for anomaly detection in applications such as lesion detection in medical images. The VAE is a generative graphical model that is used to learn the data distribution from samples and then generate new samples from this distribution. By training on normal samples, the VAE can be used to detect inputs that deviate from this learned distribution. The VAE models the output as a conditionally independent Gaussian characterized by means and variances for each output dimension. VAEs can therefore use reconstruction probability instead of reconstruction error for anomaly detection. Unfortunately, joint optimization of both mean and variance in the VAE leads to the well-known problem of shrinkage or underestimation of variance. We describe an alternative approach that avoids this variance shrinkage problem by using quantile regression. Using estimated quantiles to compute mean and variance under the Gaussian assumption, we compute reconstruction probability as a principled approach to outlier or anomaly detection. Results on simulated and Fashion MNIST data demonstrate the effectiveness of our approach. We also show how our approach can be used for principled heterogeneous thresholding for lesion detection in brain images.