 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuto-GDA: Automatic Domain Adaptation for Efficient Grounding Verification in Retrieval Augmented Generation
Oct 04, 2024



While retrieval augmented generation (RAG) has been shown to enhance factuality of large language model (LLM) outputs, LLMs still suffer from hallucination, generating incorrect or irrelevant information. One common detection strategy involves prompting the LLM again to assess whether its response is grounded in the retrieved evidence, but this approach is costly. Alternatively, lightweight natural language inference (NLI) models for efficient grounding verification can be used at inference time. While existing pre-trained NLI models offer potential solutions, their performance remains subpar compared to larger models on realistic RAG inputs. RAG inputs are more complex than most datasets used for training NLI models and have characteristics specific to the underlying knowledge base, requiring adaptation of the NLI models to a specific target domain. Additionally, the lack of labeled instances in the target domain makes supervised domain adaptation, e.g., through fine-tuning, infeasible. To address these challenges, we introduce Automatic Generative Domain Adaptation (Auto-GDA). Our framework enables unsupervised domain adaptation through synthetic data generation. Unlike previous methods that rely on handcrafted filtering and augmentation strategies, Auto-GDA employs an iterative process to continuously improve the quality of generated samples using weak labels from less efficient teacher models and discrete optimization to select the most promising augmented samples. Experimental results demonstrate the effectiveness of our approach, with models fine-tuned on synthetic data using Auto-GDA often surpassing the performance of the teacher model and reaching the performance level of LLMs at 10 % of their computational cost.
The Language of Trauma: Modeling Traumatic Event Descriptions Across Domains with Explainable AI
Aug 12, 2024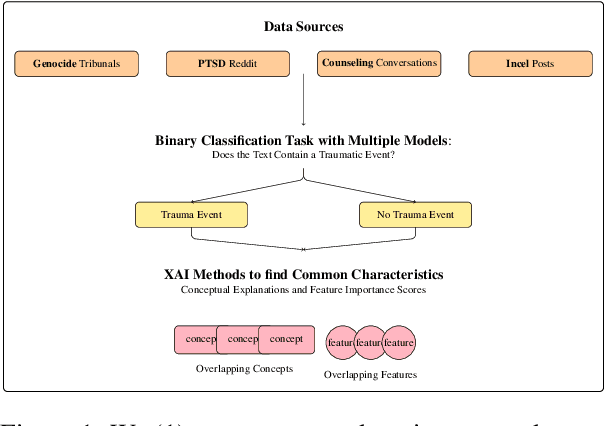


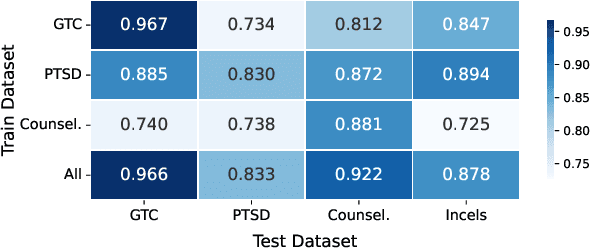
Psychological trauma can manifest following various distressing events and is captured in diverse online contexts. However, studies traditionally focus on a single aspect of trauma, often neglecting the transferability of findings across different scenarios. We address this gap by training language models with progressing complexity on trauma-related datasets, including genocide-related court data, a Reddit dataset on post-traumatic stress disorder (PTSD), counseling conversations, and Incel forum posts. Our results show that the fine-tuned RoBERTa model excels in predicting traumatic events across domains, slightly outperforming large language models like GPT-4. Additionally, SLALOM-feature scores and conceptual explanations effectively differentiate and cluster trauma-related language, highlighting different trauma aspects and identifying sexual abuse and experiences related to death as a common traumatic event across all datasets. This transferability is crucial as it allows for the development of tools to enhance trauma detection and intervention in diverse populations and settings.
Attention Mechanisms Don't Learn Additive Models: Rethinking Feature Importance for Transformers
May 22, 2024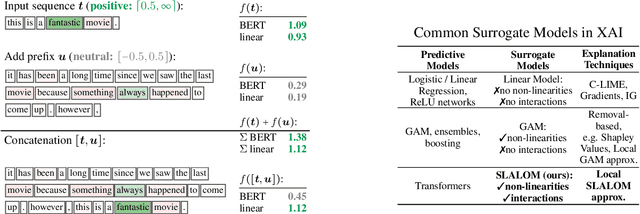
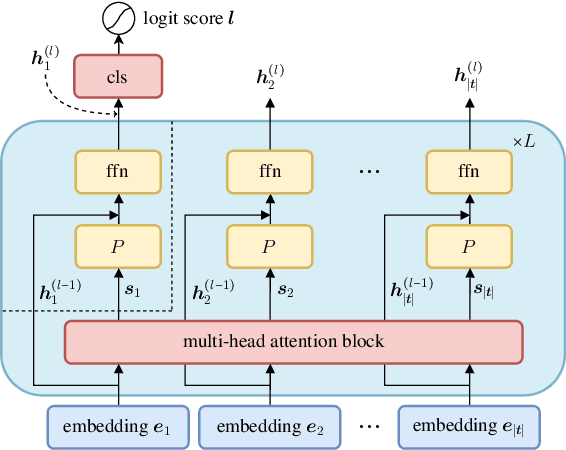

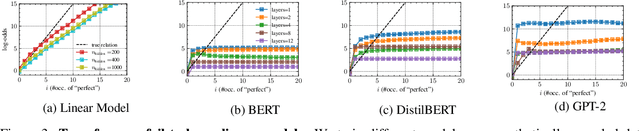
We address the critical challenge of applying feature attribution methods to the transformer architecture, which dominates current applications in natural language processing and beyond. Traditional attribution methods to explainable AI (XAI) explicitly or implicitly rely on linear or additive surrogate models to quantify the impact of input features on a model's output. In this work, we formally prove an alarming incompatibility: transformers are structurally incapable to align with popular surrogate models for feature attribution, undermining the grounding of these conventional explanation methodologies. To address this discrepancy, we introduce the Softmax-Linked Additive Log-Odds Model (SLALOM), a novel surrogate model specifically designed to align with the transformer framework. Unlike existing methods, SLALOM demonstrates the capacity to deliver a range of faithful and insightful explanations across both synthetic and real-world datasets. Showing that diverse explanations computed from SLALOM outperform common surrogate explanations on different tasks, we highlight the need for task-specific feature attributions rather than a one-size-fits-all approach.
Towards Non-Adversarial Algorithmic Recourse
Mar 15, 2024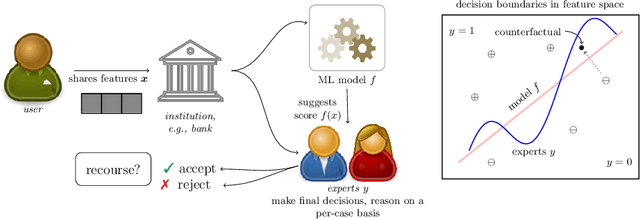
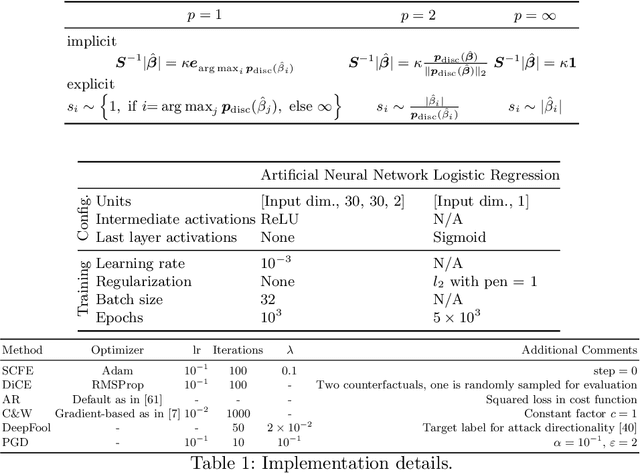
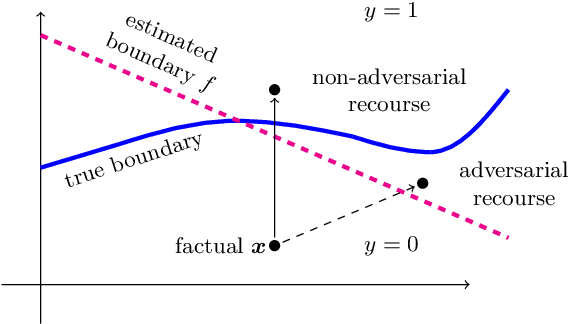

The streams of research on adversarial examples and counterfactual explanations have largely been growing independently. This has led to several recent works trying to elucidate their similarities and differences. Most prominently, it has been argued that adversarial examples, as opposed to counterfactual explanations, have a unique characteristic in that they lead to a misclassification compared to the ground truth. However, the computational goals and methodologies employed in existing counterfactual explanation and adversarial example generation methods often lack alignment with this requirement. Using formal definitions of adversarial examples and counterfactual explanations, we introduce non-adversarial algorithmic recourse and outline why in high-stakes situations, it is imperative to obtain counterfactual explanations that do not exhibit adversarial characteristics. We subsequently investigate how different components in the objective functions, e.g., the machine learning model or cost function used to measure distance, determine whether the outcome can be considered an adversarial example or not. Our experiments on common datasets highlight that these design choices are often more critical in deciding whether recourse is non-adversarial than whether recourse or attack algorithms are used. Furthermore, we show that choosing a robust and accurate machine learning model results in less adversarial recourse desired in practice.
Adapting to Change: Robust Counterfactual Explanations in Dynamic Data Landscapes
Aug 04, 2023


We introduce a novel semi-supervised Graph Counterfactual Explainer (GCE) methodology, Dynamic GRAph Counterfactual Explainer (DyGRACE). It leverages initial knowledge about the data distribution to search for valid counterfactuals while avoiding using information from potentially outdated decision functions in subsequent time steps. Employing two graph autoencoders (GAEs), DyGRACE learns the representation of each class in a binary classification scenario. The GAEs minimise the reconstruction error between the original graph and its learned representation during training. The method involves (i) optimising a parametric density function (implemented as a logistic regression function) to identify counterfactuals by maximising the factual autoencoder's reconstruction error, (ii) minimising the counterfactual autoencoder's error, and (iii) maximising the similarity between the factual and counterfactual graphs. This semi-supervised approach is independent of an underlying black-box oracle. A logistic regression model is trained on a set of graph pairs to learn weights that aid in finding counterfactuals. At inference, for each unseen graph, the logistic regressor identifies the best counterfactual candidate using these learned weights, while the GAEs can be iteratively updated to represent the continual adaptation of the learned graph representation over iterations. DyGRACE is quite effective and can act as a drift detector, identifying distributional drift based on differences in reconstruction errors between iterations. It avoids reliance on the oracle's predictions in successive iterations, thereby increasing the efficiency of counterfactual discovery. DyGRACE, with its capacity for contrastive learning and drift detection, will offer new avenues for semi-supervised learning and explanation generation.
Gaussian Membership Inference Privacy
Jun 12, 2023We propose a new privacy notion called $f$-Membership Inference Privacy ($f$-MIP), which explicitly considers the capabilities of realistic adversaries under the membership inference attack threat model. By doing so $f$-MIP offers interpretable privacy guarantees and improved utility (e.g., better classification accuracy). Our novel theoretical analysis of likelihood ratio-based membership inference attacks on noisy stochastic gradient descent (SGD) results in a parametric family of $f$-MIP guarantees that we refer to as $\mu$-Gaussian Membership Inference Privacy ($\mu$-GMIP). Our analysis additionally yields an analytical membership inference attack that offers distinct advantages over previous approaches. First, unlike existing methods, our attack does not require training hundreds of shadow models to approximate the likelihood ratio. Second, our analytical attack enables straightforward auditing of our privacy notion $f$-MIP. Finally, our analysis emphasizes the importance of various factors, such as hyperparameters (e.g., batch size, number of model parameters) and data specific characteristics in controlling an attacker's success in reliably inferring a given point's membership to the training set. We demonstrate the effectiveness of our method on models trained across vision and tabular datasets.
I Prefer not to Say: Operationalizing Fair and User-guided Data Minimization
Nov 01, 2022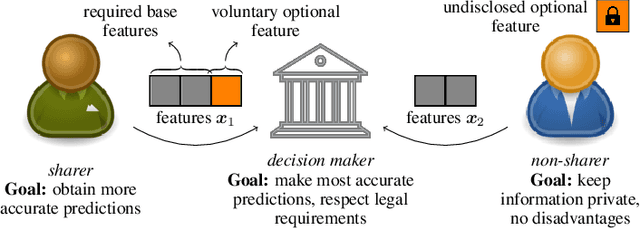
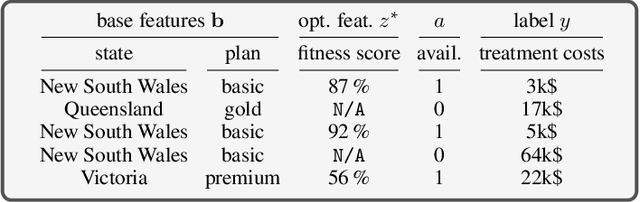
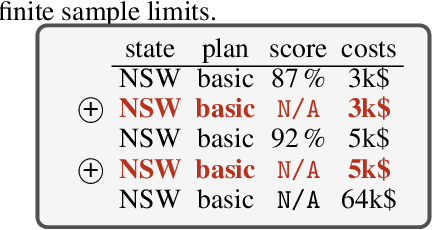
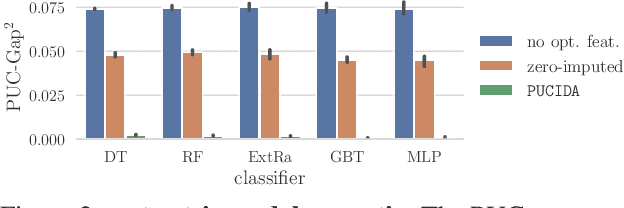
To grant users greater authority over their personal data, policymakers have suggested tighter data protection regulations (e.g., GDPR, CCPA). One key principle within these regulations is data minimization, which urges companies and institutions to only collect data that is relevant and adequate for the purpose of the data analysis. In this work, we take a user-centric perspective on this regulation, and let individual users decide which data they deem adequate and relevant to be processed by a machine-learned model. We require that users who decide to provide optional information should appropriately benefit from sharing their data, while users who rely on the mandate to leave their data undisclosed should not be penalized for doing so. This gives rise to the overlooked problem of fair treatment between individuals providing additional information and those choosing not to. While the classical fairness literature focuses on fair treatment between advantaged and disadvantaged groups, an initial look at this problem through the lens of classical fairness notions reveals that they are incompatible with these desiderata. We offer a solution to this problem by proposing the notion of Optional Feature Fairness (OFF) that follows from our requirements. To operationalize OFF, we derive a multi-model strategy and a tractable logistic regression model. We analyze the effect and the cost of applying OFF on several real-world data sets.
Language Models are Realistic Tabular Data Generators
Oct 12, 2022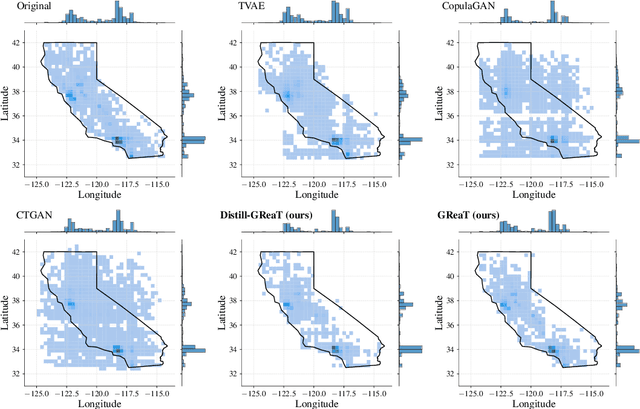
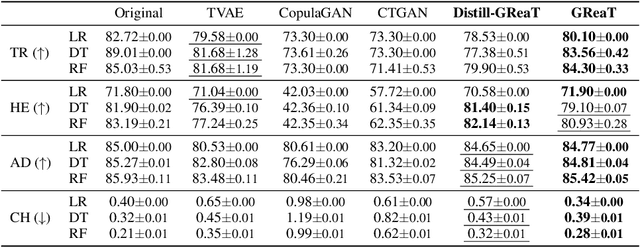
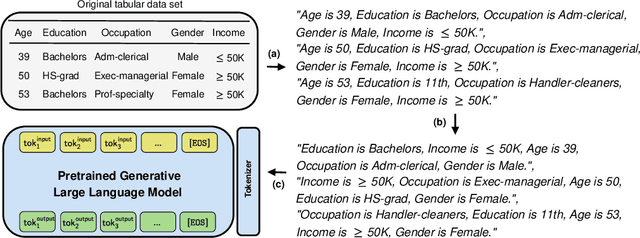
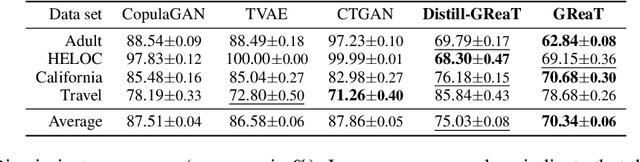
Tabular data is among the oldest and most ubiquitous forms of data. However, the generation of synthetic samples with the original data's characteristics still remains a significant challenge for tabular data. While many generative models from the computer vision domain, such as autoencoders or generative adversarial networks, have been adapted for tabular data generation, less research has been directed towards recent transformer-based large language models (LLMs), which are also generative in nature. To this end, we propose GReaT (Generation of Realistic Tabular data), which exploits an auto-regressive generative LLM to sample synthetic and yet highly realistic tabular data. Furthermore, GReaT can model tabular data distributions by conditioning on any subset of features; the remaining features are sampled without additional overhead. We demonstrate the effectiveness of the proposed approach in a series of experiments that quantify the validity and quality of the produced data samples from multiple angles. We find that GReaT maintains state-of-the-art performance across many real-world data sets with heterogeneous feature types.
On the Trade-Off between Actionable Explanations and the Right to be Forgotten
Aug 30, 2022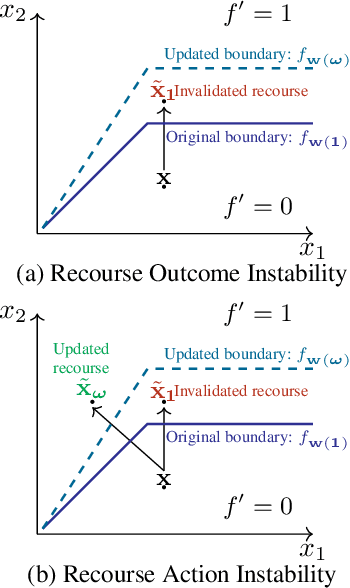

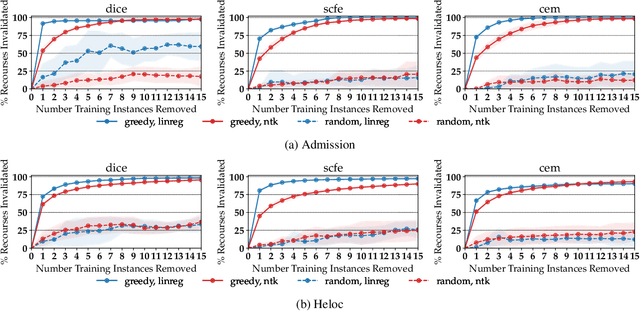
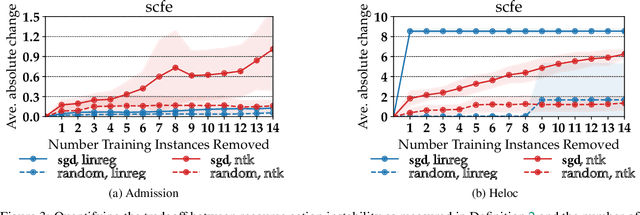
As machine learning (ML) models are increasingly being deployed in high-stakes applications, policymakers have suggested tighter data protection regulations (e.g., GDPR, CCPA). One key principle is the ``right to be forgotten'' which gives users the right to have their data deleted. Another key principle is the right to an actionable explanation, also known as algorithmic recourse, allowing users to reverse unfavorable decisions. To date it is unknown whether these two principles can be operationalized simultaneously. Therefore, we introduce and study the problem of recourse invalidation in the context of data deletion requests. More specifically, we theoretically and empirically analyze the behavior of popular state-of-the-art algorithms and demonstrate that the recourses generated by these algorithms are likely to be invalidated if a small number of data deletion requests (e.g., 1 or 2) warrant updates of the predictive model. For the setting of linear models and overparameterized neural networks -- studied through the lens of neural tangent kernels (NTKs) -- we suggest a framework to identify a minimal subset of critical training points, which when removed, would lead to maximize the fraction of invalidated recourses. Using our framework, we empirically establish that the removal of as little as 2 data instances from the training set can invalidate up to 95 percent of all recourses output by popular state-of-the-art algorithms. Thus, our work raises fundamental questions about the compatibility of ``the right to an actionable explanation'' in the context of the ``right to be forgotten''.
Disentangling Embedding Spaces with Minimal Distributional Assumptions
Jun 28, 2022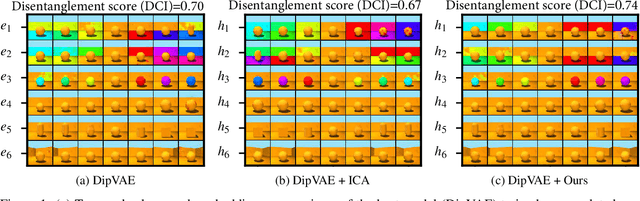
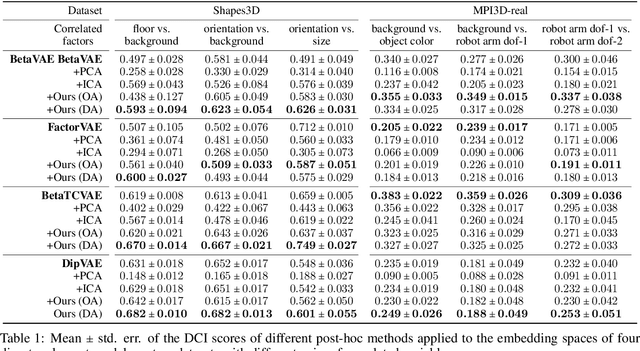
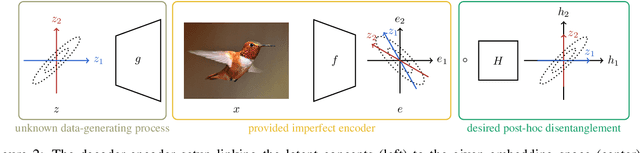

Interest in understanding and factorizing learned embedding spaces is growing. For instance, recent concept-based explanation techniques analyze a machine learning model in terms of interpretable latent components. Such components have to be discovered in the model's embedding space, e.g., through independent component analysis (ICA) or modern disentanglement learning techniques. While these unsupervised approaches offer a sound formal framework, they either require access to a data generating function or impose rigid assumptions on the data distribution, such as independence of components, that are often violated in practice. In this work, we link conceptual explainability for vision models with disentanglement learning and ICA. This enables us to provide first theoretical results on how components can be identified without requiring any distributional assumptions. From these insights, we derive the disjoint attributions (DA) concept discovery method that is applicable to a broader class of problems than current approaches but yet possesses a formal identifiability guarantee. In an extensive comparison against component analysis and over 300 state-of-the-art disentanglement models, DA stably maintains superior performance, even under varying distributions and correlation strengths.