 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling Embedding Spaces with Minimal Distributional Assumptions
Paper and Code
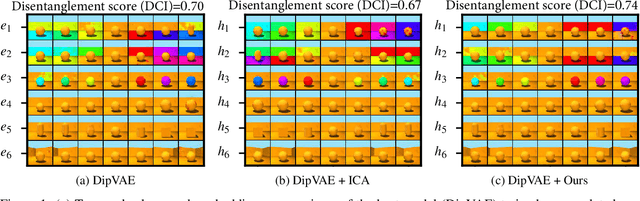
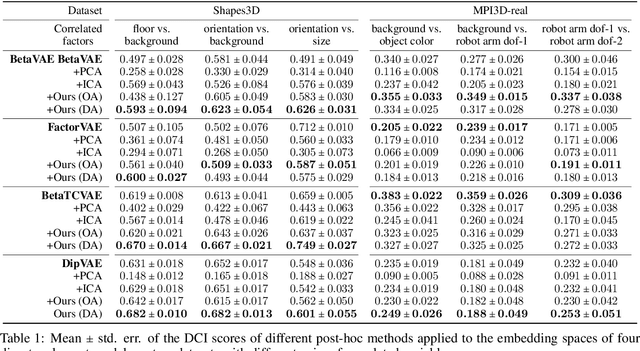
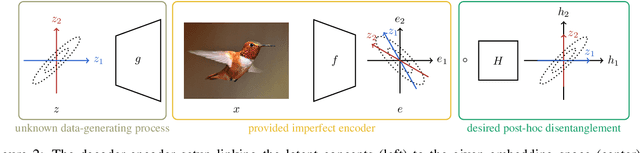

Interest in understanding and factorizing learned embedding spaces is growing. For instance, recent concept-based explanation techniques analyze a machine learning model in terms of interpretable latent components. Such components have to be discovered in the model's embedding space, e.g., through independent component analysis (ICA) or modern disentanglement learning techniques. While these unsupervised approaches offer a sound formal framework, they either require access to a data generating function or impose rigid assumptions on the data distribution, such as independence of components, that are often violated in practice. In this work, we link conceptual explainability for vision models with disentanglement learning and ICA. This enables us to provide first theoretical results on how components can be identified without requiring any distributional assumptions. From these insights, we derive the disjoint attributions (DA) concept discovery method that is applicable to a broader class of problems than current approaches but yet possesses a formal identifiability guarantee. In an extensive comparison against component analysis and over 300 state-of-the-art disentanglement models, DA stably maintains superior performance, even under varying distributions and correlation strengths.