 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimultaneous Training of First- and Second-Order Optimizers in Population-Based Reinforcement Learning
Sep 04, 2024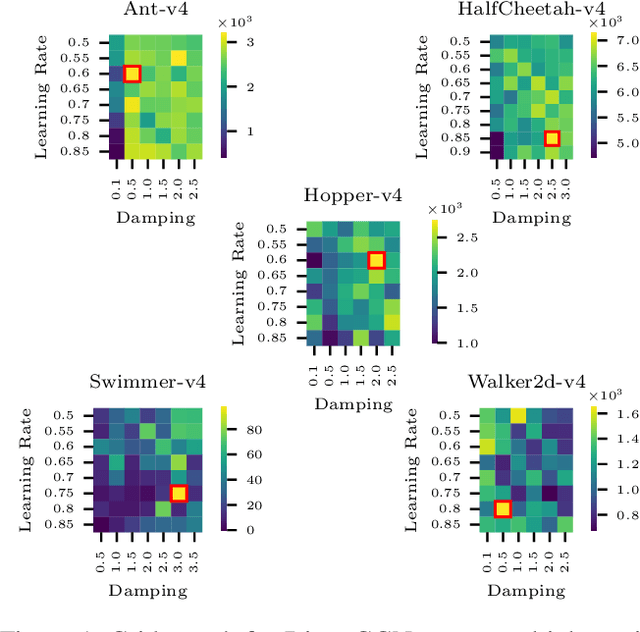
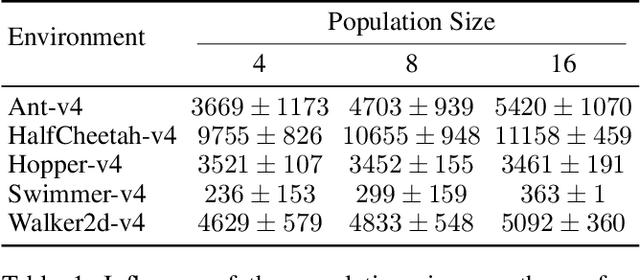
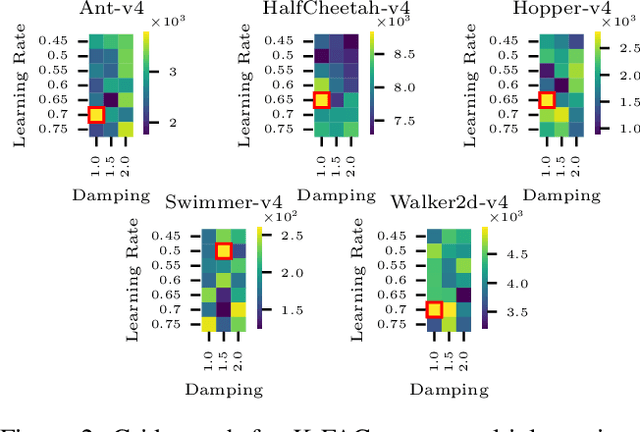
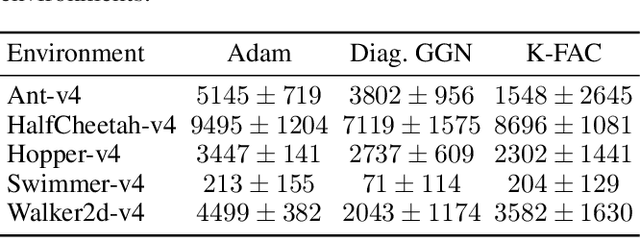
The tuning of hyperparameters in reinforcement learning (RL) is critical, as these parameters significantly impact an agent's performance and learning efficiency. Dynamic adjustment of hyperparameters during the training process can significantly enhance both the performance and stability of learning. Population-based training (PBT) provides a method to achieve this by continuously tuning hyperparameters throughout the training. This ongoing adjustment enables models to adapt to different learning stages, resulting in faster convergence and overall improved performance. In this paper, we propose an enhancement to PBT by simultaneously utilizing both first- and second-order optimizers within a single population. We conducted a series of experiments using the TD3 algorithm across various MuJoCo environments. Our results, for the first time, empirically demonstrate the potential of incorporating second-order optimizers within PBT-based RL. Specifically, the combination of the K-FAC optimizer with Adam led to up to a 10% improvement in overall performance compared to PBT using only Adam. Additionally, in environments where Adam occasionally fails, such as the Swimmer environment, the mixed population with K-FAC exhibited more reliable learning outcomes, offering a significant advantage in training stability without a substantial increase in computational time.
Attention Mechanisms Don't Learn Additive Models: Rethinking Feature Importance for Transformers
May 22, 2024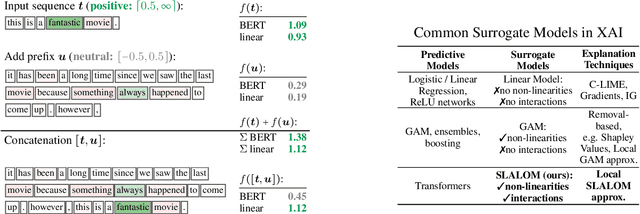
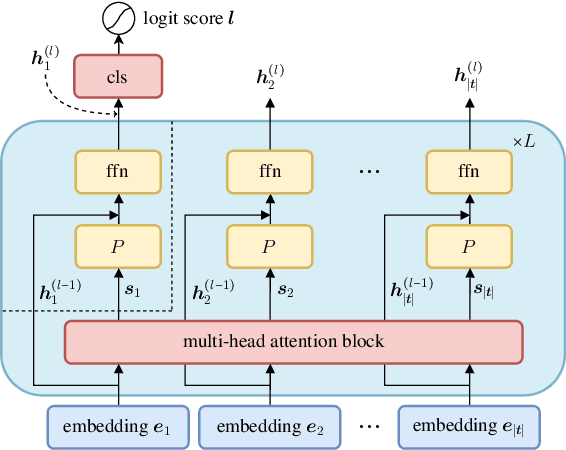

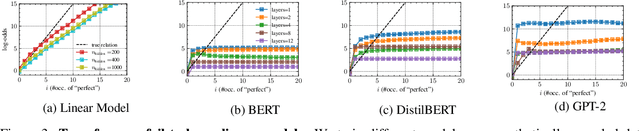
We address the critical challenge of applying feature attribution methods to the transformer architecture, which dominates current applications in natural language processing and beyond. Traditional attribution methods to explainable AI (XAI) explicitly or implicitly rely on linear or additive surrogate models to quantify the impact of input features on a model's output. In this work, we formally prove an alarming incompatibility: transformers are structurally incapable to align with popular surrogate models for feature attribution, undermining the grounding of these conventional explanation methodologies. To address this discrepancy, we introduce the Softmax-Linked Additive Log-Odds Model (SLALOM), a novel surrogate model specifically designed to align with the transformer framework. Unlike existing methods, SLALOM demonstrates the capacity to deliver a range of faithful and insightful explanations across both synthetic and real-world datasets. Showing that diverse explanations computed from SLALOM outperform common surrogate explanations on different tasks, we highlight the need for task-specific feature attributions rather than a one-size-fits-all approach.