 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInjecting Falsehoods: Adversarial Man-in-the-Middle Attacks Undermining Factual Recall in LLMs
Nov 08, 2025LLMs are now an integral part of information retrieval. As such, their role as question answering chatbots raises significant concerns due to their shown vulnerability to adversarial man-in-the-middle (MitM) attacks. Here, we propose the first principled attack evaluation on LLM factual memory under prompt injection via Xmera, our novel, theory-grounded MitM framework. By perturbing the input given to "victim" LLMs in three closed-book and fact-based QA settings, we undermine the correctness of the responses and assess the uncertainty of their generation process. Surprisingly, trivial instruction-based attacks report the highest success rate (up to ~85.3%) while simultaneously having a high uncertainty for incorrectly answered questions. To provide a simple defense mechanism against Xmera, we train Random Forest classifiers on the response uncertainty levels to distinguish between attacked and unattacked queries (average AUC of up to ~96%). We believe that signaling users to be cautious about the answers they receive from black-box and potentially corrupt LLMs is a first checkpoint toward user cyberspace safety.
Understanding Knowledge Drift in LLMs through Misinformation
Sep 11, 2024



Large Language Models (LLMs) have revolutionized numerous applications, making them an integral part of our digital ecosystem. However, their reliability becomes critical, especially when these models are exposed to misinformation. We primarily analyze the susceptibility of state-of-the-art LLMs to factual inaccuracies when they encounter false information in a QnA scenario, an issue that can lead to a phenomenon we refer to as *knowledge drift*, which significantly undermines the trustworthiness of these models. We evaluate the factuality and the uncertainty of the models' responses relying on Entropy, Perplexity, and Token Probability metrics. Our experiments reveal that an LLM's uncertainty can increase up to 56.6% when the question is answered incorrectly due to the exposure to false information. At the same time, repeated exposure to the same false information can decrease the models uncertainty again (-52.8% w.r.t. the answers on the untainted prompts), potentially manipulating the underlying model's beliefs and introducing a drift from its original knowledge. These findings provide insights into LLMs' robustness and vulnerability to adversarial inputs, paving the way for developing more reliable LLM applications across various domains. The code is available at https://github.com/afastowski/knowledge_drift.
Attention Mechanisms Don't Learn Additive Models: Rethinking Feature Importance for Transformers
May 22, 2024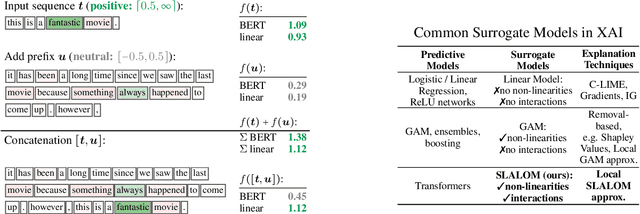
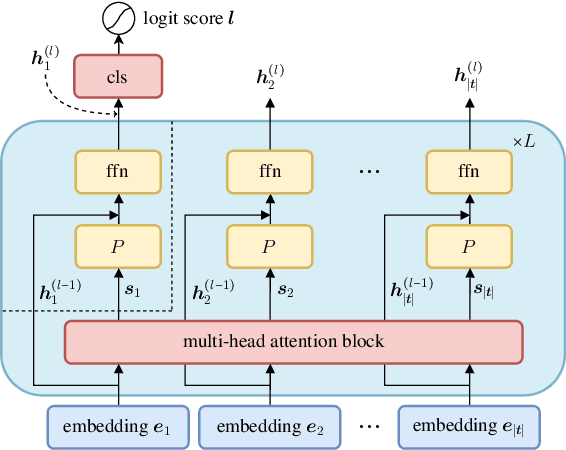

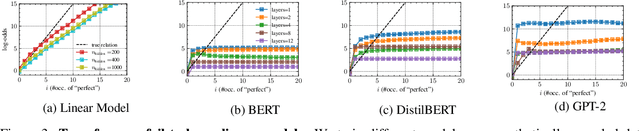
We address the critical challenge of applying feature attribution methods to the transformer architecture, which dominates current applications in natural language processing and beyond. Traditional attribution methods to explainable AI (XAI) explicitly or implicitly rely on linear or additive surrogate models to quantify the impact of input features on a model's output. In this work, we formally prove an alarming incompatibility: transformers are structurally incapable to align with popular surrogate models for feature attribution, undermining the grounding of these conventional explanation methodologies. To address this discrepancy, we introduce the Softmax-Linked Additive Log-Odds Model (SLALOM), a novel surrogate model specifically designed to align with the transformer framework. Unlike existing methods, SLALOM demonstrates the capacity to deliver a range of faithful and insightful explanations across both synthetic and real-world datasets. Showing that diverse explanations computed from SLALOM outperform common surrogate explanations on different tasks, we highlight the need for task-specific feature attributions rather than a one-size-fits-all approach.
Exploring Anisotropy and Outliers in Multilingual Language Models for Cross-Lingual Semantic Sentence Similarity
Jun 07, 2023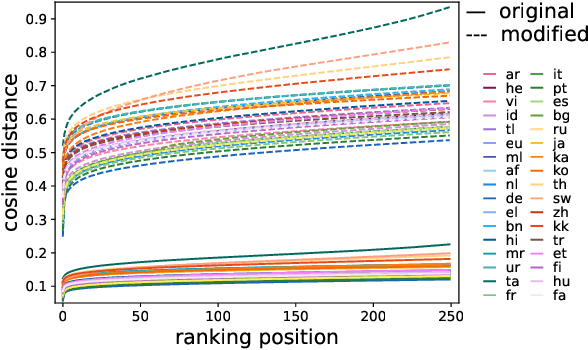
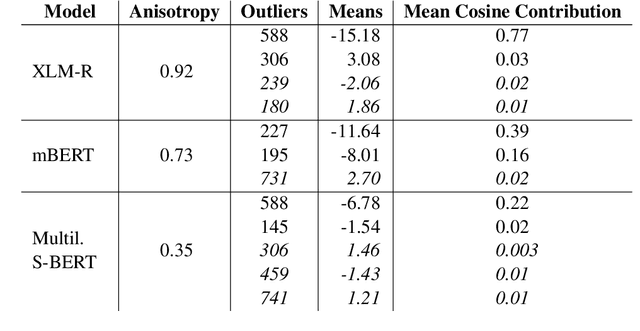
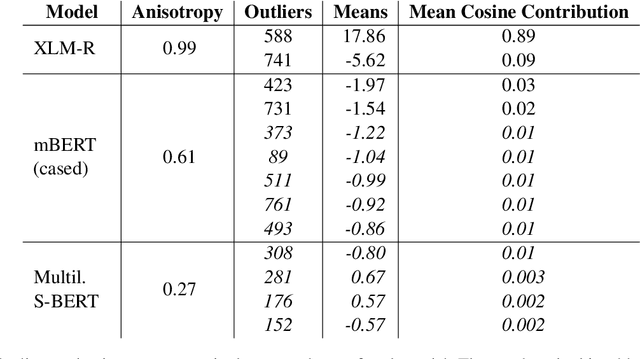
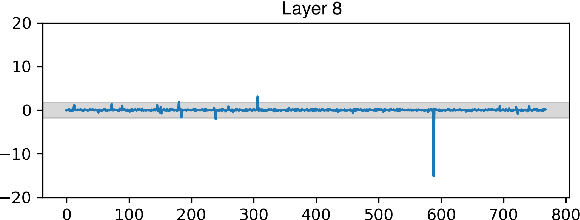
Previous work has shown that the representations output by contextual language models are more anisotropic than static type embeddings, and typically display outlier dimensions. This seems to be true for both monolingual and multilingual models, although much less work has been done on the multilingual context. Why these outliers occur and how they affect the representations is still an active area of research. We investigate outlier dimensions and their relationship to anisotropy in multiple pre-trained multilingual language models. We focus on cross-lingual semantic similarity tasks, as these are natural tasks for evaluating multilingual representations. Specifically, we examine sentence representations. Sentence transformers which are fine-tuned on parallel resources (that are not always available) perform better on this task, and we show that their representations are more isotropic. However, we aim to improve multilingual representations in general. We investigate how much of the performance difference can be made up by only transforming the embedding space without fine-tuning, and visualise the resulting spaces. We test different operations: Removing individual outlier dimensions, cluster-based isotropy enhancement, and ZCA whitening. We publish our code for reproducibility.