 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Literal Token Overlap: Token Alignability for Multilinguality
Feb 10, 2025



Previous work has considered token overlap, or even similarity of token distributions, as predictors for multilinguality and cross-lingual knowledge transfer in language models. However, these very literal metrics assign large distances to language pairs with different scripts, which can nevertheless show good cross-linguality. This limits the explanatory strength of token overlap for knowledge transfer between language pairs that use distinct scripts or follow different orthographic conventions. In this paper, we propose subword token alignability as a new way to understand the impact and quality of multilingual tokenisation. In particular, this metric predicts multilinguality much better when scripts are disparate and the overlap of literal tokens is low. We analyse this metric in the context of both encoder and decoder models, look at data size as a potential distractor, and discuss how this insight may be applied to multilingual tokenisation in future work. We recommend our subword token alignability metric for identifying optimal language pairs for cross-lingual transfer, as well as to guide the construction of better multilingual tokenisers in the future. We publish our code and reproducibility details.
Understanding Cross-Lingual Alignment -- A Survey
Apr 09, 2024



Cross-lingual alignment, the meaningful similarity of representations across languages in multilingual language models, has been an active field of research in recent years. We survey the literature of techniques to improve cross-lingual alignment, providing a taxonomy of methods and summarising insights from throughout the field. We present different understandings of cross-lingual alignment and their limitations. We provide a qualitative summary of results from a large number of surveyed papers. Finally, we discuss how these insights may be applied not only to encoder models, where this topic has been heavily studied, but also to encoder-decoder or even decoder-only models, and argue that an effective trade-off between language-neutral and language-specific information is key.
Multilingual Text-to-Image Generation Magnifies Gender Stereotypes and Prompt Engineering May Not Help You
Jan 31, 2024Text-to-image generation models have recently achieved astonishing results in image quality, flexibility, and text alignment and are consequently employed in a fast-growing number of applications. Through improvements in multilingual abilities, a larger community now has access to this kind of technology. Yet, as we will show, multilingual models suffer similarly from (gender) biases as monolingual models. Furthermore, the natural expectation is that these models will provide similar results across languages, but this is not the case and there are important differences between languages. Thus, we propose a novel benchmark MAGBIG intending to foster research in multilingual models without gender bias. We investigate whether multilingual T2I models magnify gender bias with MAGBIG. To this end, we use multilingual prompts requesting portrait images of persons of a certain occupation or trait (using adjectives). Our results show not only that models deviate from the normative assumption that each gender should be equally likely to be generated, but that there are also big differences across languages. Furthermore, we investigate prompt engineering strategies, i.e. the use of indirect, neutral formulations, as a possible remedy for these biases. Unfortunately, they help only to a limited extent and result in worse text-to-image alignment. Consequently, this work calls for more research into diverse representations across languages in image generators.
Exploring Anisotropy and Outliers in Multilingual Language Models for Cross-Lingual Semantic Sentence Similarity
Jun 07, 2023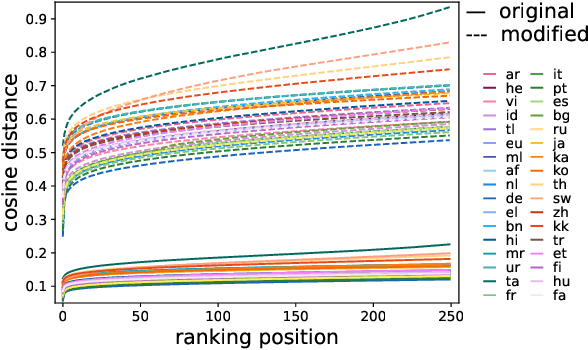
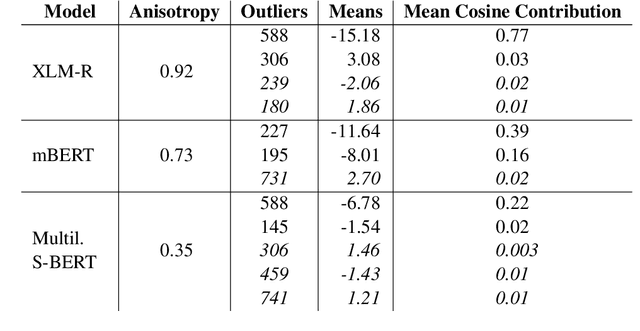
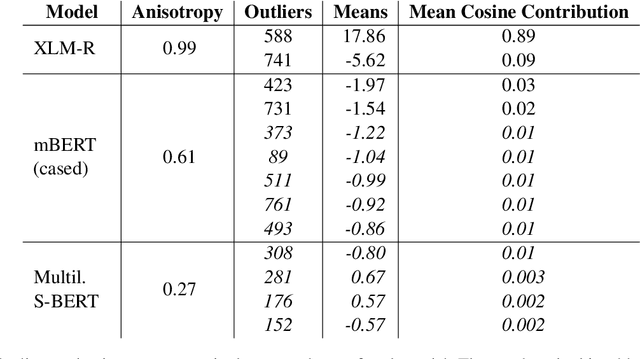
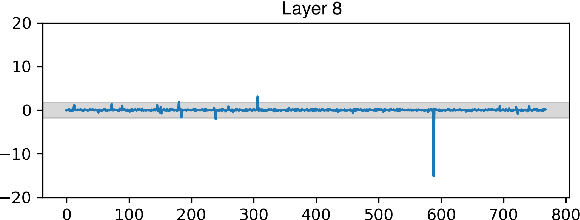
Previous work has shown that the representations output by contextual language models are more anisotropic than static type embeddings, and typically display outlier dimensions. This seems to be true for both monolingual and multilingual models, although much less work has been done on the multilingual context. Why these outliers occur and how they affect the representations is still an active area of research. We investigate outlier dimensions and their relationship to anisotropy in multiple pre-trained multilingual language models. We focus on cross-lingual semantic similarity tasks, as these are natural tasks for evaluating multilingual representations. Specifically, we examine sentence representations. Sentence transformers which are fine-tuned on parallel resources (that are not always available) perform better on this task, and we show that their representations are more isotropic. However, we aim to improve multilingual representations in general. We investigate how much of the performance difference can be made up by only transforming the embedding space without fine-tuning, and visualise the resulting spaces. We test different operations: Removing individual outlier dimensions, cluster-based isotropy enhancement, and ZCA whitening. We publish our code for reproducibility.
Speaking Multiple Languages Affects the Moral Bias of Language Models
Nov 14, 2022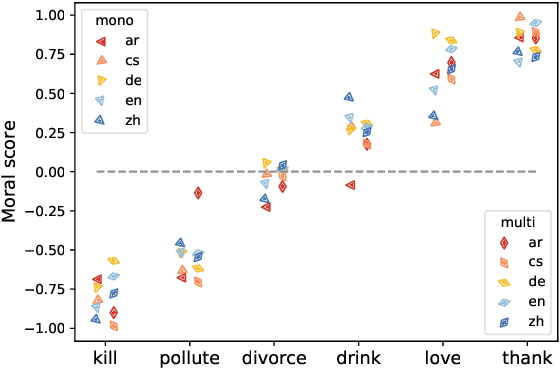
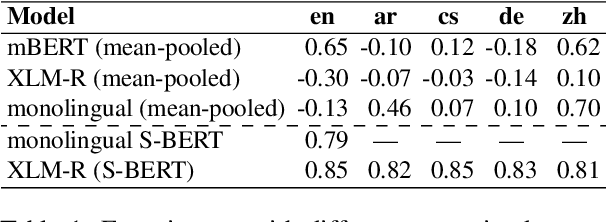
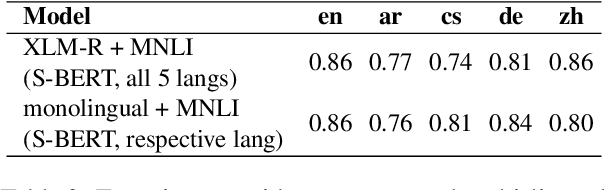
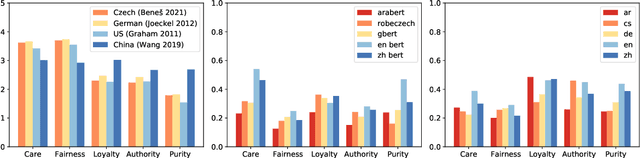
Pre-trained multilingual language models (PMLMs) are commonly used when dealing with data from multiple languages and cross-lingual transfer. However, PMLMs are trained on varying amounts of data for each language. In practice this means their performance is often much better on English than many other languages. We explore to what extent this also applies to moral norms. Do the models capture moral norms from English and impose them on other languages? Do the models exhibit random and thus potentially harmful beliefs in certain languages? Both these issues could negatively impact cross-lingual transfer and potentially lead to harmful outcomes. In this paper, we (1) apply the MoralDirection framework to multilingual models, comparing results in German, Czech, Arabic, Mandarin Chinese, and English, (2) analyse model behaviour on filtered parallel subtitles corpora, and (3) apply the models to a Moral Foundations Questionnaire, comparing with human responses from different countries. Our experiments demonstrate that, indeed, PMLMs encode differing moral biases, but these do not necessarily correspond to cultural differences or commonalities in human opinions.
Do Multilingual Language Models Capture Differing Moral Norms?
Mar 18, 2022

Massively multilingual sentence representations are trained on large corpora of uncurated data, with a very imbalanced proportion of languages included in the training. This may cause the models to grasp cultural values including moral judgments from the high-resource languages and impose them on the low-resource languages. The lack of data in certain languages can also lead to developing random and thus potentially harmful beliefs. Both these issues can negatively influence zero-shot cross-lingual model transfer and potentially lead to harmful outcomes. Therefore, we aim to (1) detect and quantify these issues by comparing different models in different languages, (2) develop methods for improving undesirable properties of the models. Our initial experiments using the multilingual model XLM-R show that indeed multilingual LMs capture moral norms, even with potentially higher human-agreement than monolingual ones. However, it is not yet clear to what extent these moral norms differ between languages.
Combining Static and Contextualised Multilingual Embeddings
Mar 17, 2022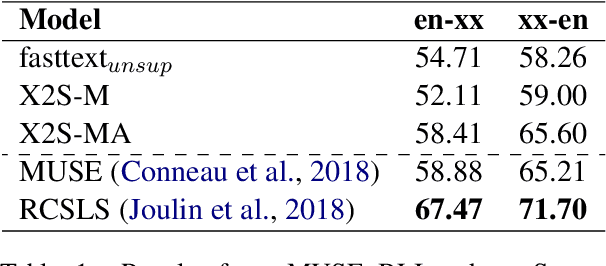
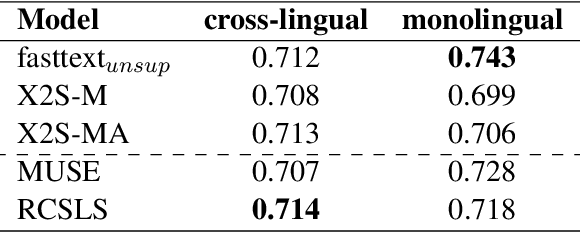
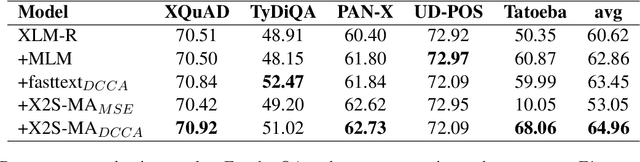

Static and contextual multilingual embeddings have complementary strengths. Static embeddings, while less expressive than contextual language models, can be more straightforwardly aligned across multiple languages. We combine the strengths of static and contextual models to improve multilingual representations. We extract static embeddings for 40 languages from XLM-R, validate those embeddings with cross-lingual word retrieval, and then align them using VecMap. This results in high-quality, highly multilingual static embeddings. Then we apply a novel continued pre-training approach to XLM-R, leveraging the high quality alignment of our static embeddings to better align the representation space of XLM-R. We show positive results for multiple complex semantic tasks. We release the static embeddings and the continued pre-training code. Unlike most previous work, our continued pre-training approach does not require parallel text.